Ein einheitliches Erlebnis zur Steigerung der Produktivität und Agilität von数据科学
数据科学家stehen während des gesamten数据科学工作流vor zahlreichen Herausforderungen, die die Produktivität behind dern。大的世界,大的世界,大的世界,大的世界,大的世界,大的世界,大的世界,大的世界,大的世界,大的世界,大的世界,大的世界,大的世界,大的世界,大的世界,大的世界,大的世界。
VORHER

紧随其后
Eine offene und einheitliche平台für die gemeinsame Ausführung aller Arten von analytics - workload, von der Datenvorbereitung
bis hin zu explorativen Analysen和vorausschauenden Analysen in großem Maßstab。

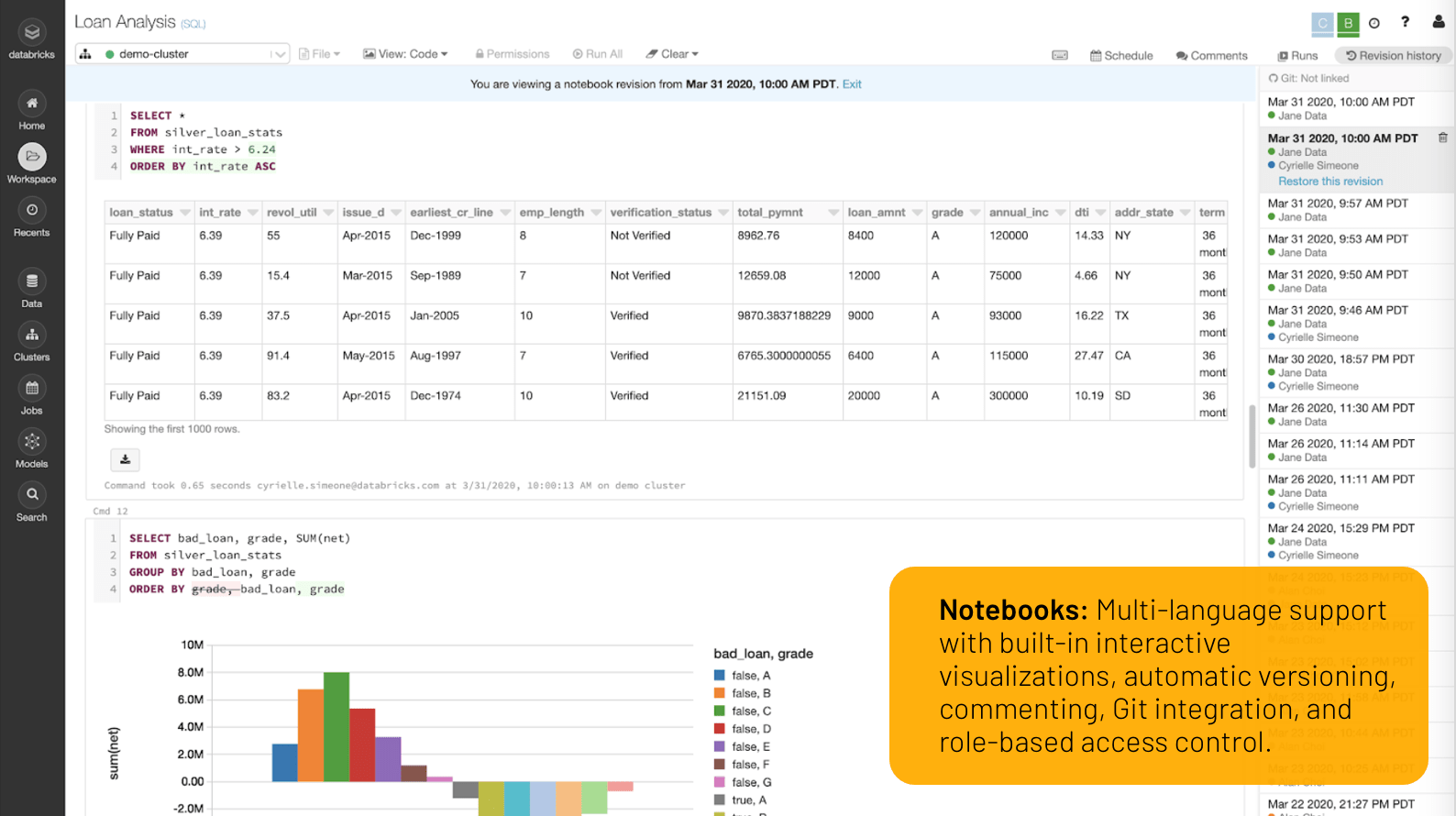



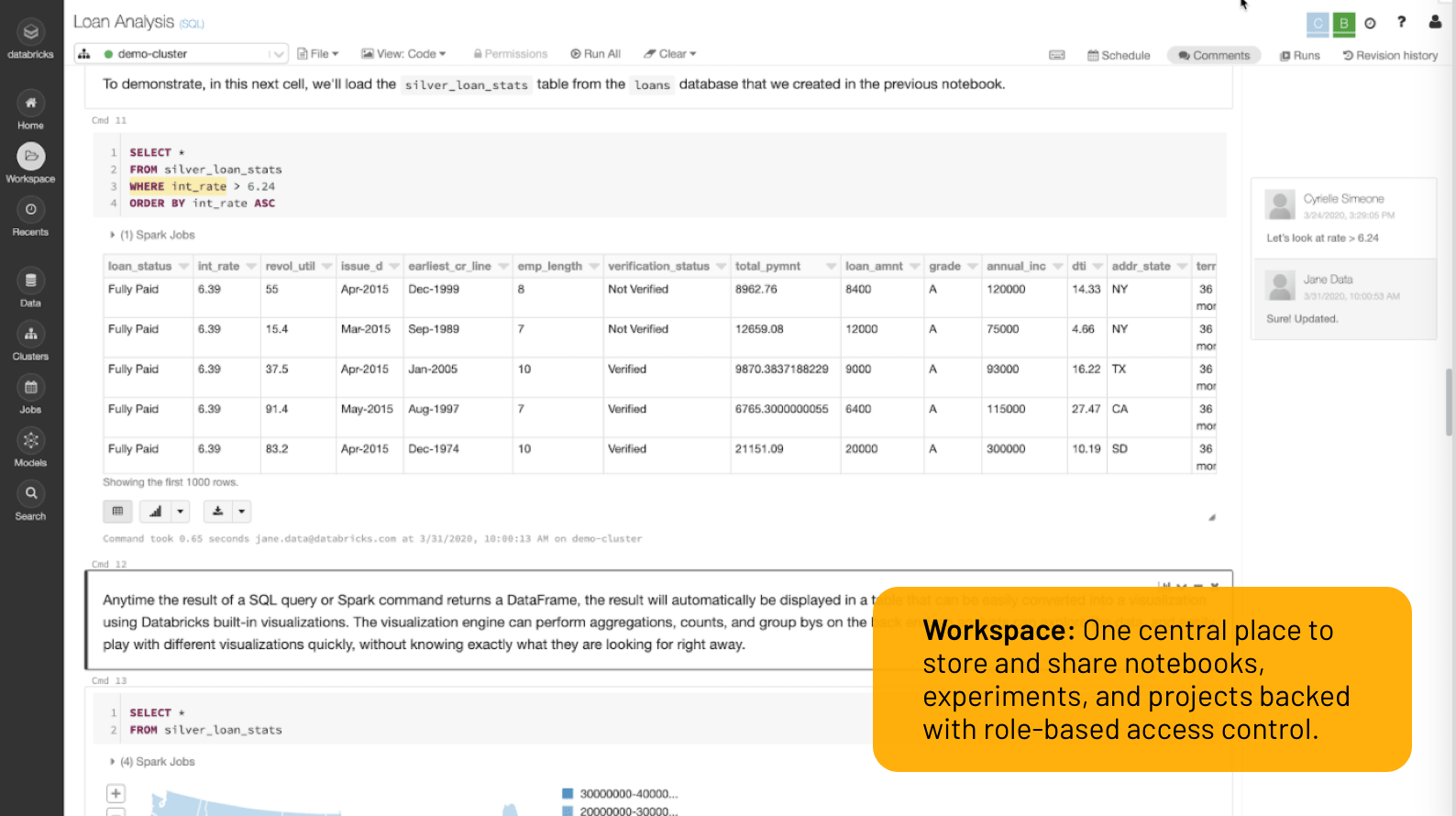
Mit Databricks笔记本entwickeln Sie gemeinsam Code in Python, R, Scala和SQL, analysieren Daten mittel interaktiver Visualisierung und gewinnen neue Einblicke。
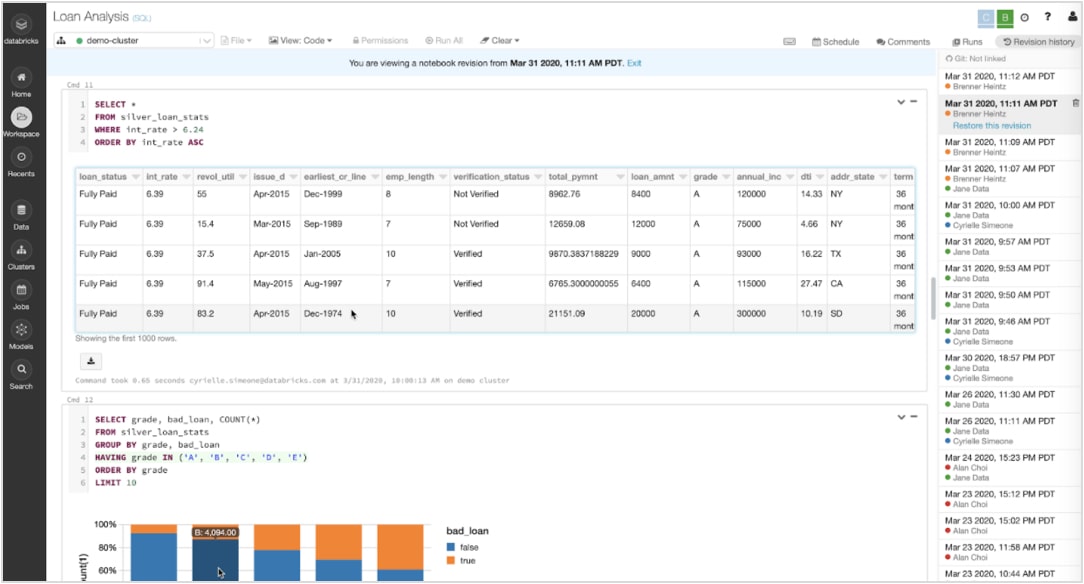
Geben Sie Ihren Code sicher und ohne Bedenken frei - mit Co-Authoring, Kommentierung, automatischer Versionierung, Git-Integrationen and rollenbasierten zugriffskontrolen。
代表你的实验和模型一个einem Ort im Blick, erfassen Sie Wissen, veröffentlichen你的仪表板和erleichtern Sie die Übergabe一个Kollegen和Beteiligte im gesamten工作流- von Rohdaten bis hin zu Einblicken。
Künftig sinind Sie niht mehr auf die Datenspeicherkapazität Ihres笔记本电脑odder die Ihnen zur Verfügung stehende Rechenleistung beschränkt。
在云中,我的生命飘忽不定
und verbinden Sie笔记本mit automatisch verwalteten集群,嗯Ihre分析-负载nach Bedarf zu skalieren。
Wir wissen, wie beschäftigt Sie sind…Sie haben wahrscheinlich bereits Hunderte von Projekten auf Ihrem Laptop und sind an ein bestimmtes Toolset gewöhnt。
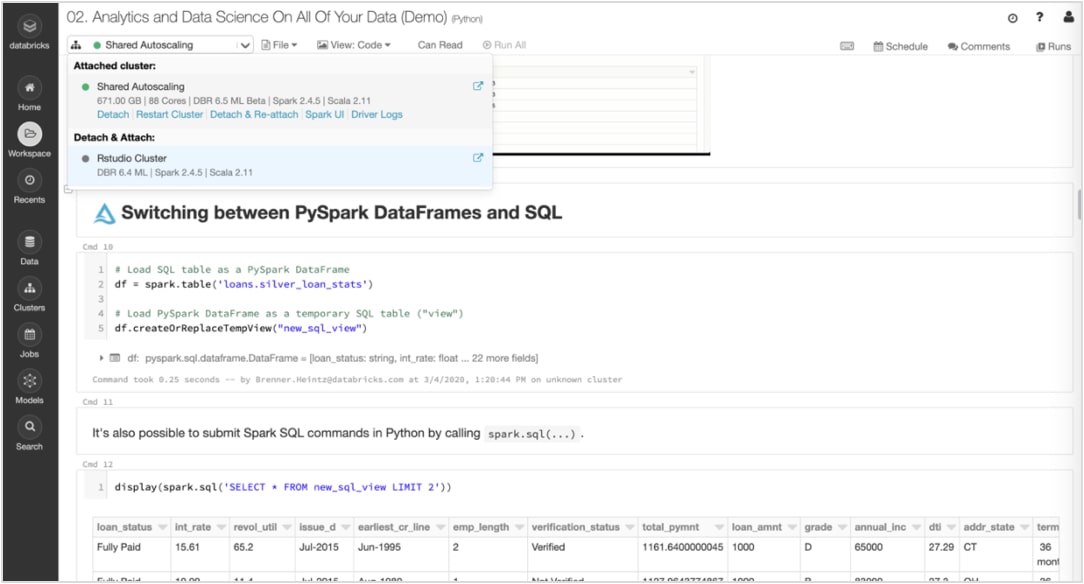
德国数据库künftig德国数据库和unbeschränkter德国数据库。可选verwenden Sie RStudio odder JupyterLab einfach direkt innerhalb von Databricks。那么奇怪的das Nutzungserlebnis nahtlos。
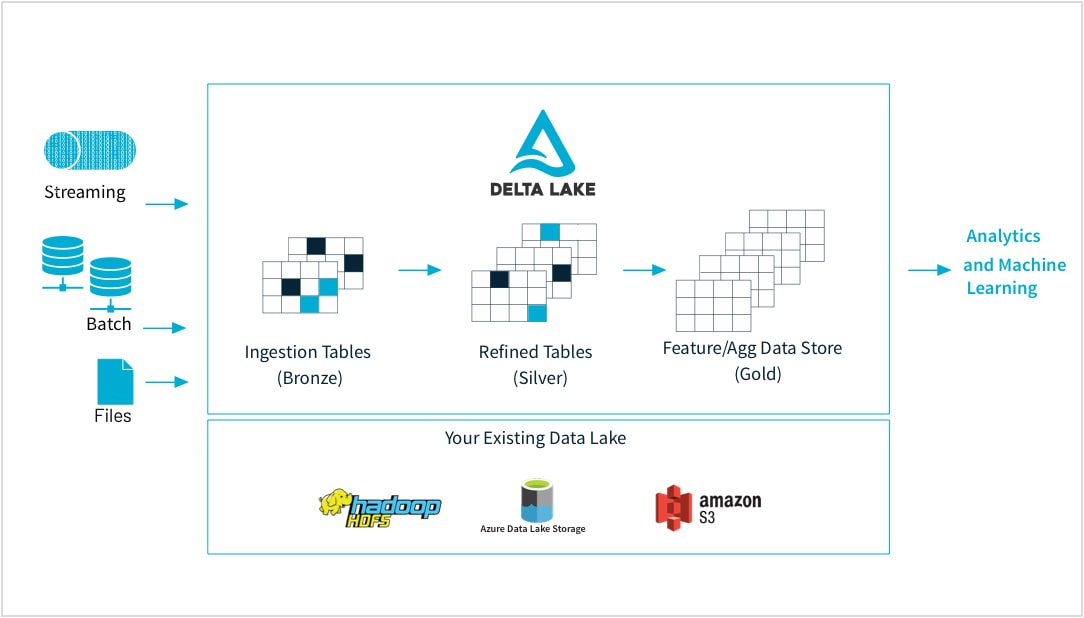
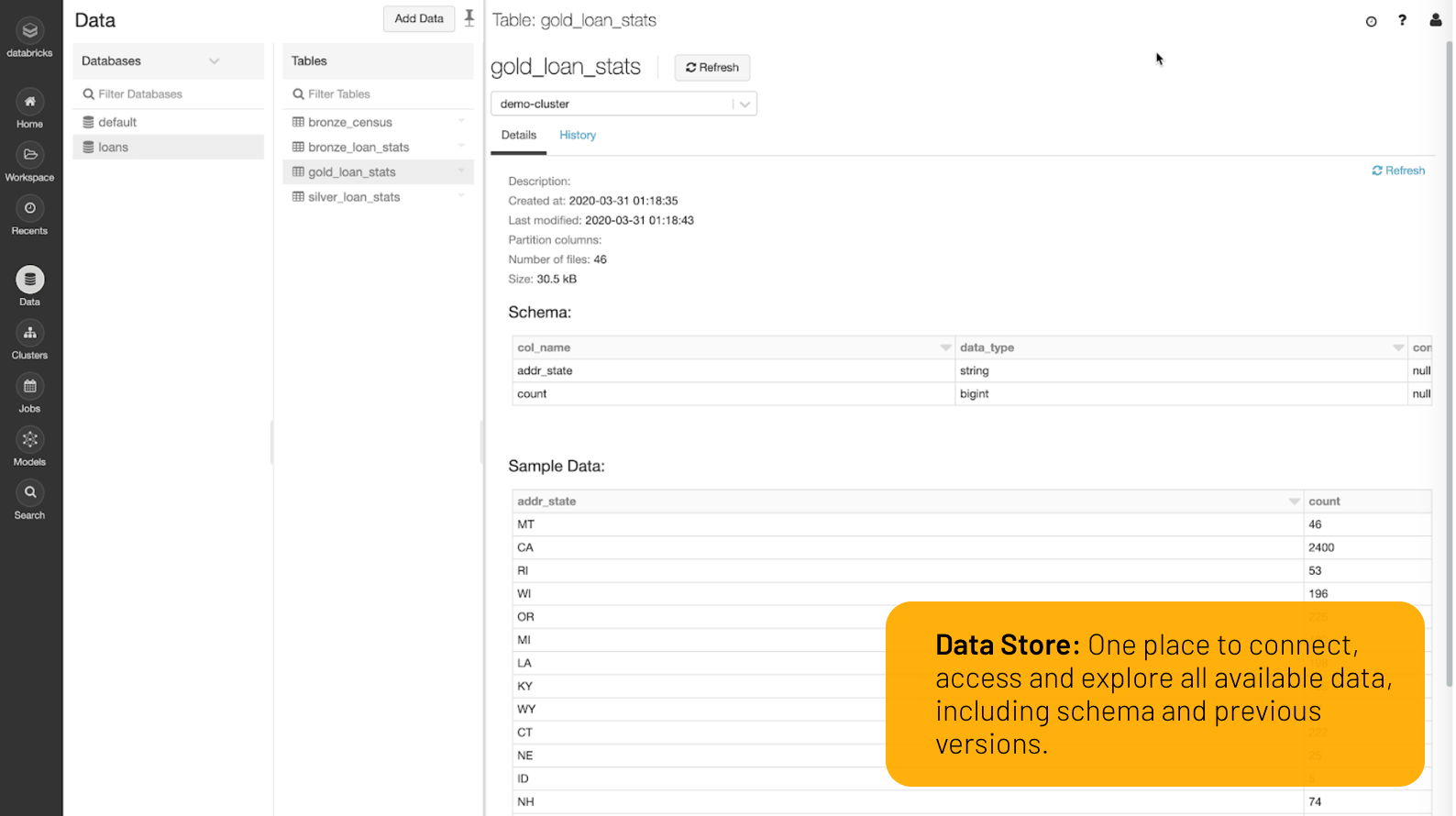
贝仁原和目录,你在我的日子里三角洲湖: ob Batch, Streaming, strukturiert oder unstrukturiert, und machen Sie Sie für Ihr gesamtes Unternehmen über einen zentralen Datenspeicher auffindbar。
Wenn die Daten eingehen, bird durch Qualitätsprüfungen sichergestellt, dass die Daten für die Analytics bereit sind。请在此查阅资料Ergänzen在此查阅资料并在此查阅资料,并在此查阅资料erfüllen können。
你的工作间和新工作间的相互作用可视化运行系统的顺序unterstützten图书馆的顺序顺序。
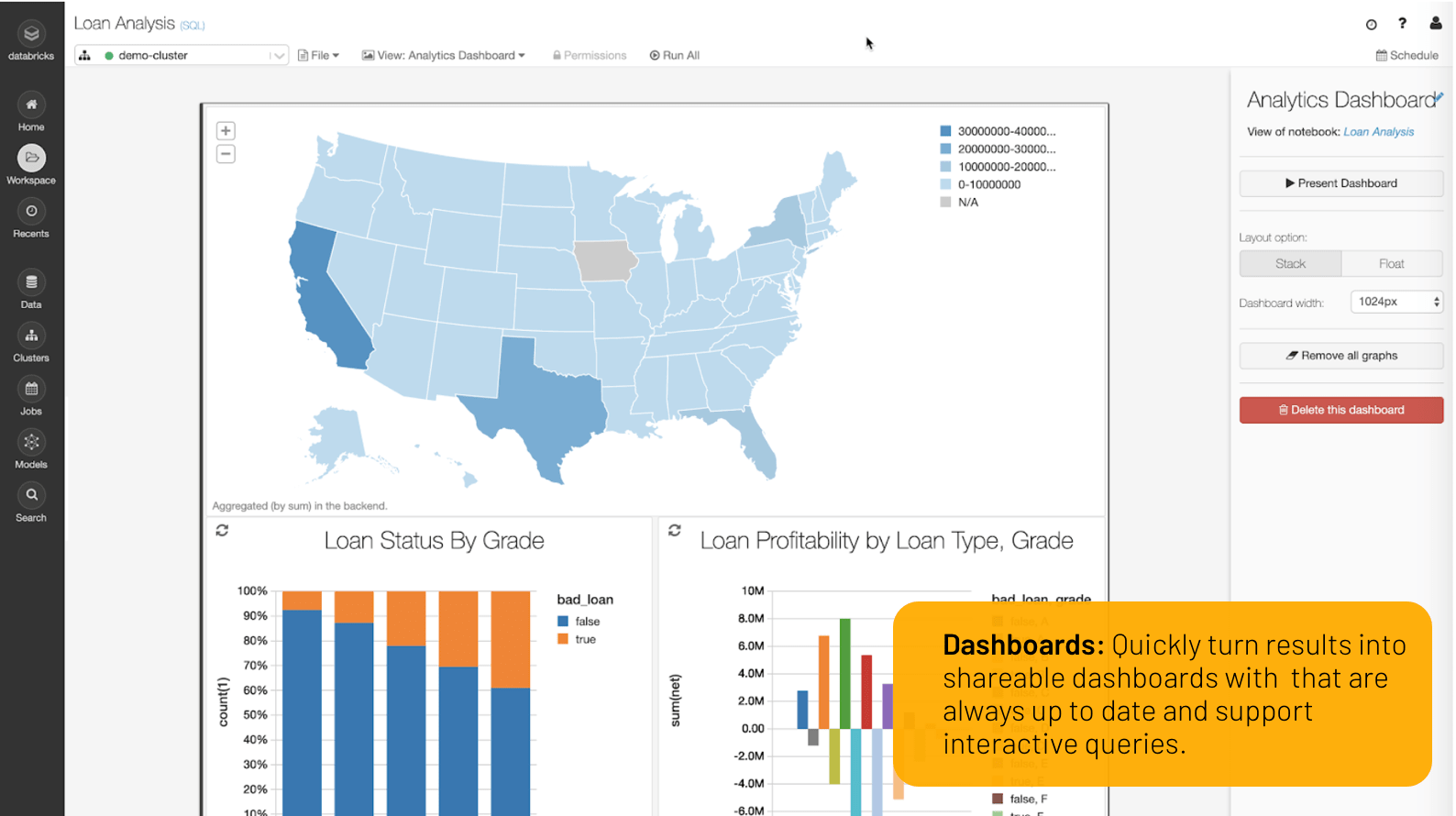
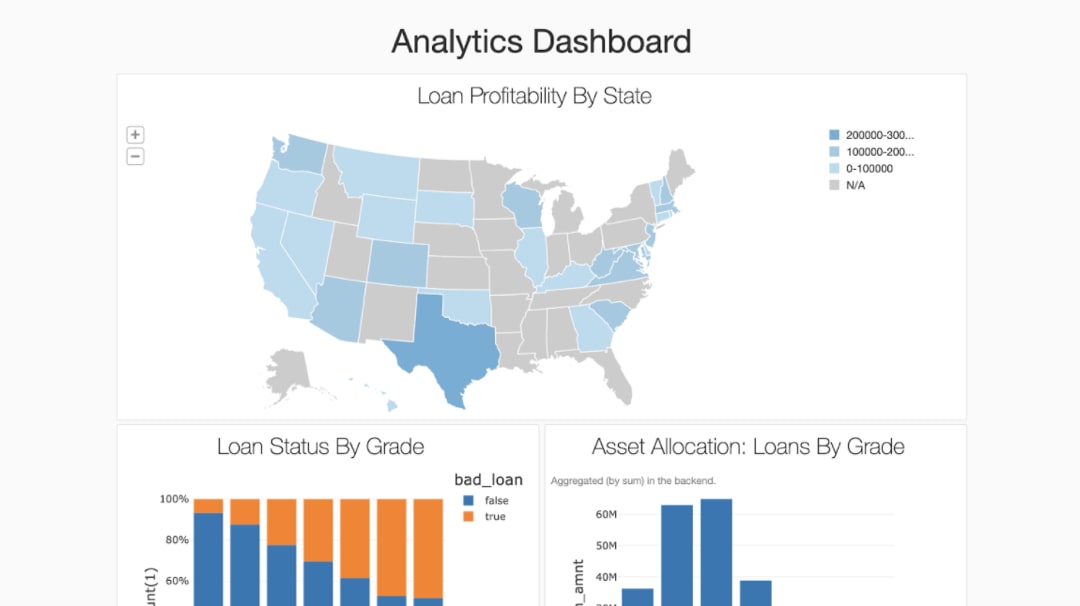
Verwandeln Sie Ihre Analyse im Handumdrehen in dynamisches Dashboard,嗯Ergebnisse schnell and einfach weiterzugeben and zu extieren。Die Dashboards sind immer auf dem neuesten Stand und können auch interaktive Abfragen durchführen。
Zellen, Visualisierungen oder笔记本können mit rollenbasierter Zugriffskontrolle geteilt und in verschiedenen Formaten wie HTML oder IPython笔记本出口商werden。

Legen Sie schnell los - mit einem Klick Zugriff auf einsatzbereite und optimierte Umgebungen für机器学习,einschließlich der beliebtesten框架wie scikit-learn, XGBoost, TensorFlow, Keras und mehr。order migrrieren und passen Sie ML-Umgebungen mühelos mit Conda an。笔记本电脑eingeschränkt信德,mühelos von kleinen zu großen Datenmenge auf Ihrem。
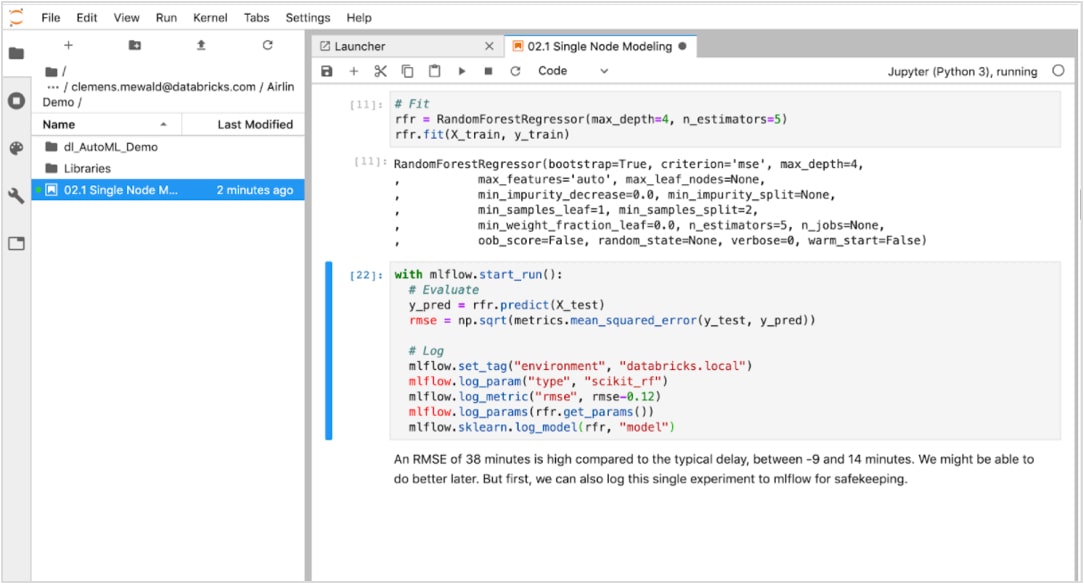
Die ML Runtime bietet integrerteAutoML-Funktionen, einschließlich超参数调优,model suche und vieles mehr, um den数据科学工作流zu beschleunigen。Beschleunigen Sie zum Beispiel die Trainingszeit mit integrerten Optimierungen für die am häufigsten verwendeten算法和框架,einschließlich logistischer回归,baumbasierter模型和图形框架。
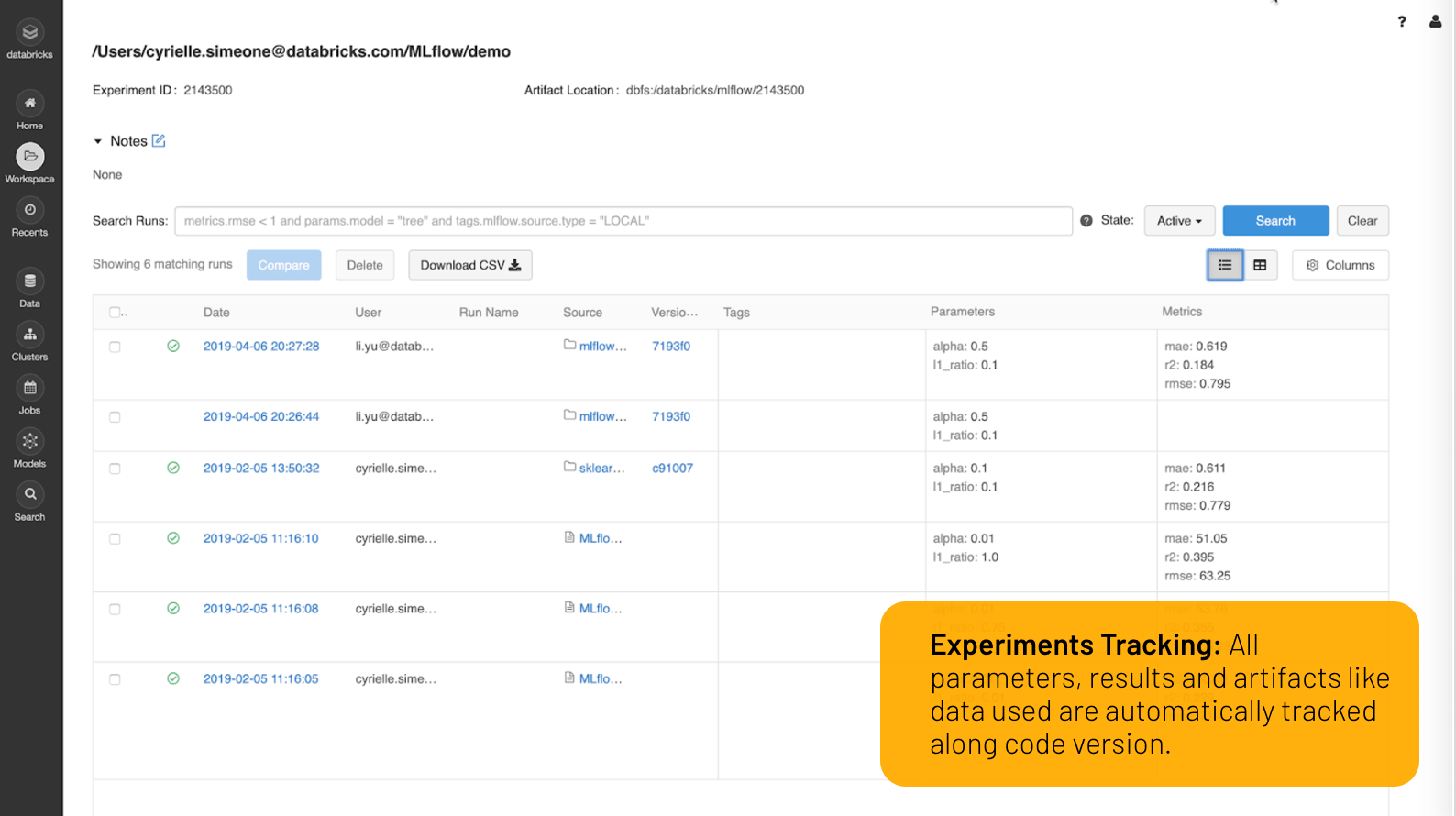
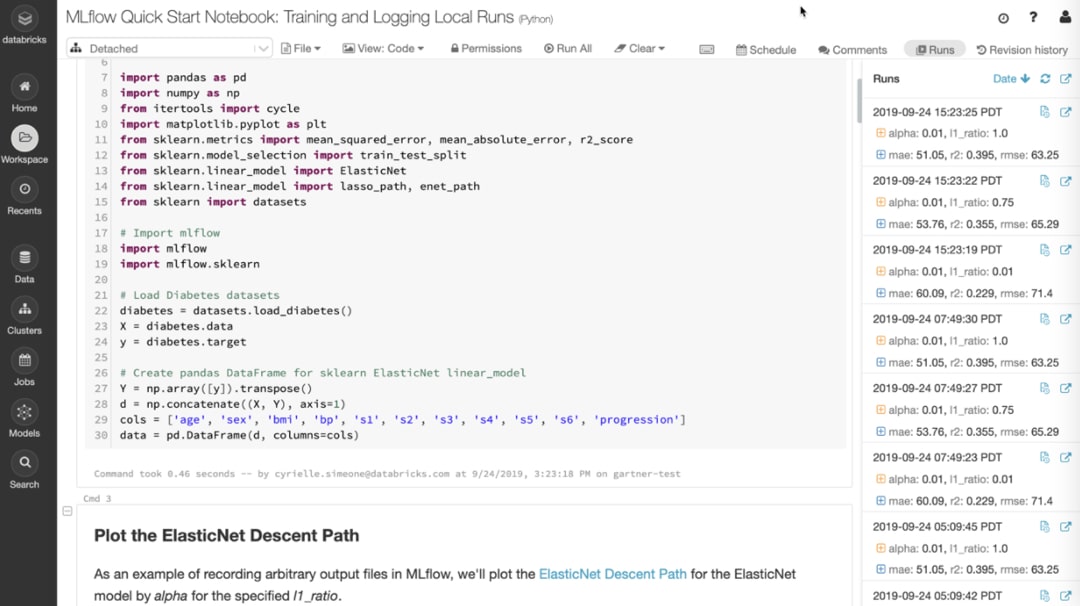
Verfolgen Sie实验自动完成aus beliebigen框架和原kollieren Sie参数,Ergebnisse和代码版本en für jede Ausführung mit verwaltetemMLflow.
在Arbeitsbereichen,和视觉的实验,计划的顺序和笔记本Mitwirkenden Durchläufen和meherren Mitwirkenden。
Vergleichen Sie Ergebnisse mit Such-, Sortier-, Filter- und erweiterten Visualisierungen, um die best Version Ihres model zu finden, und kehren Sie für diese spezifische Ausführung schnell zur richtigen Version Ihres Codes zurück。
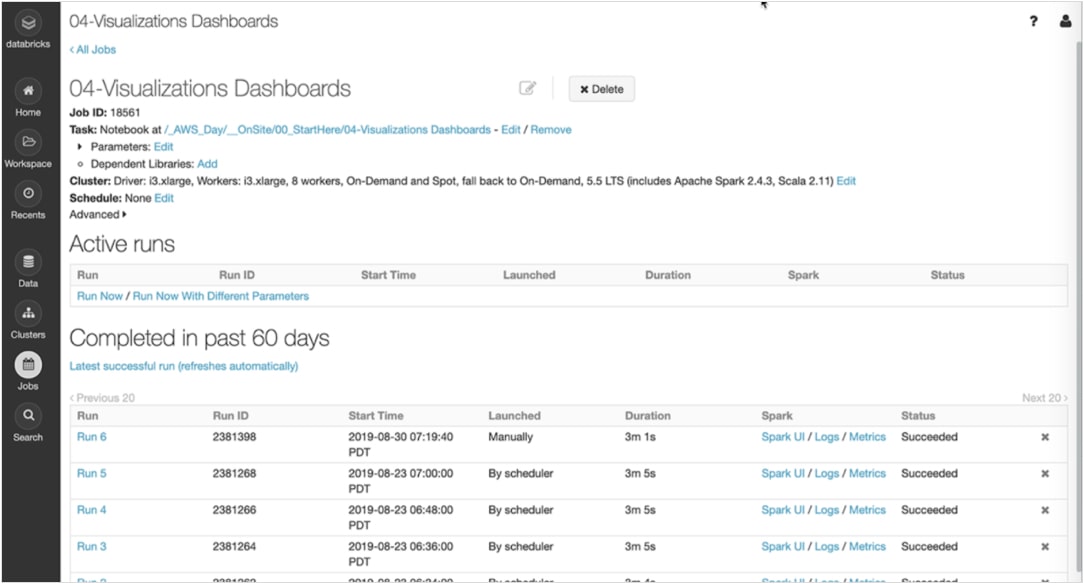
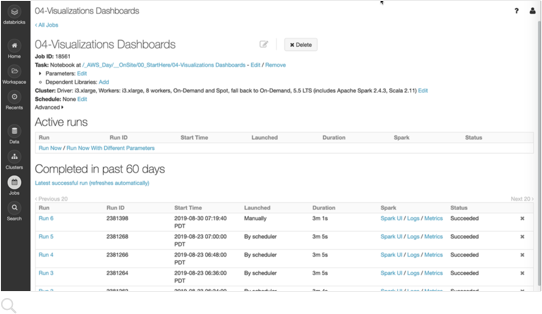
Planen Sie笔记本,um Datenumwandlungen和Modellierungen automatisch durchzuführen und aktuelle Ergebnisse zu teilen。
Richten Sie Alarmmeldungen in und greifen Sie schnell auf Audit-Protokolle zu,嗯die Überwachung und Fehlersuche zu erleichtern。

![]()
Shell hat weltweit in Data-Science-Tool implementiert, mit dem es das Ersatzteilinventar von 1 Mrd。美元贬值和乐观,下跌。
Möchten你堕落了吗?