ML框架正在以疯狂的速度发展,从业者平均需要管理8个库。ML运行时提供了一键访问最流行的ML框架的可靠和性能分布,并通过预先构建的容器自定义ML环境。
Beschleunigen Sie das Machine Learning von der Datenvorbereitung bis zur Schlussfolgerung mit den integrierten AutoML-Funktionen, einschließlich Hyperparameter-Tuning und Modellsuche mit Hyperopt und MLflow。
Mit einer automatisch verwalteten und skalierbaren Cluster-Infrastruktur können Sie mühelos von kleinen zu großen Datenmengen wechseln。机器学习运行时enthält auch einzigartige Leistungsverbesserungen für die gängigsten Algorithmen sowie HorovodRunner, eine einfache API für verteiltes深度学习。
实验:Verfolgen, vergleichen and visualisieren Sie hundtausende von experimentmit开源oder管bob下载地址理MLflow和Funktion zur Darstellung并行器Koordinaten。
Automatisierte模型(für Single-Node-ML):Optimierte und verteilte bedingte Hyperparametersuche über mehere modelellarchitekturen mit erweitertem Hyperopt und automatisiertem Tracking für MLflow。
Automatisiertes超参数调优für单节点机器学习:Optimierte und vertete Hyperparametersuche mit erweitertem Hyperopt und automatisiertem Tracking für MLflow。
Automatisiertes超参数调优für vertetes机器学习:Tiefe集成在die Cross Validation von PySpark MLlib zur automatischen Verfolgung von MLlib- experimen在MLflow。
TensorFlow optimiert:Profitieren Sie von der CUDA-optimierten Version von TensorFlow auf gpu - cluster für maximale Leistung。
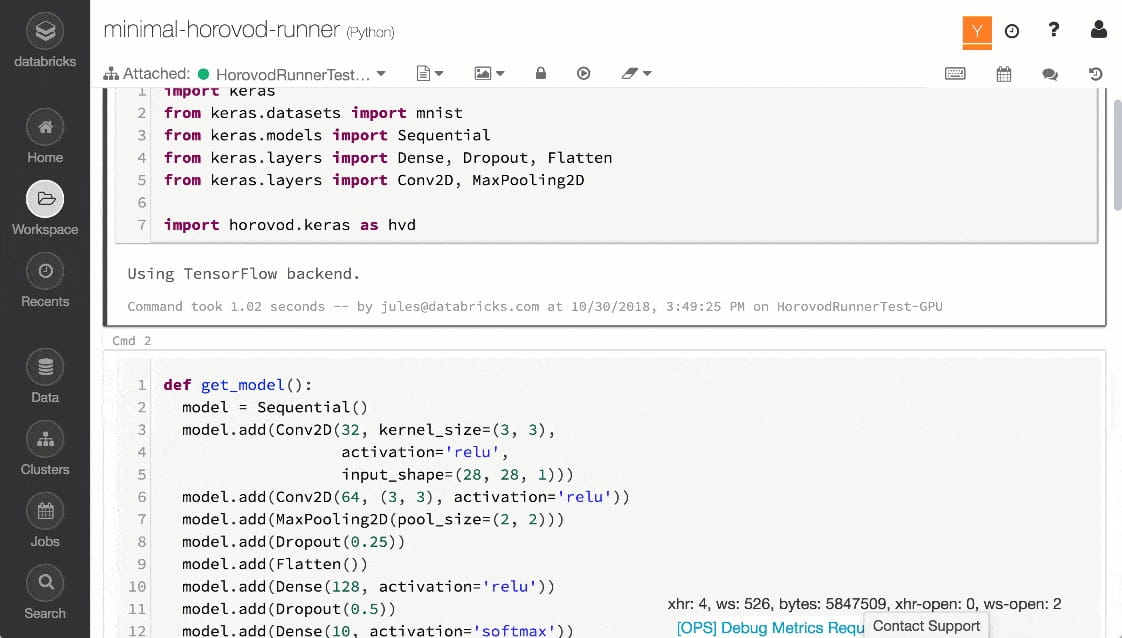
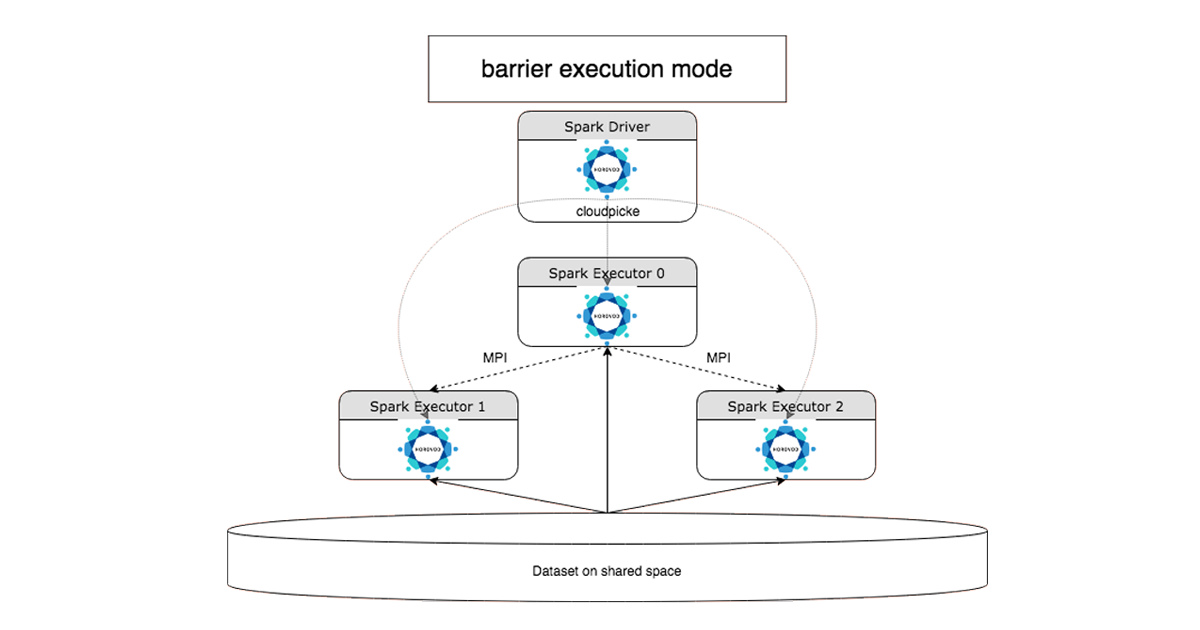
HorovodRunner:Rüsten Sie schnell und unkompliziert Ihren Deep Learning-Trainingscode für Einzelknoten auf damit er über HorovodRunner in einem databicks - cluster laufen kann。HorovodRunner ist eine einfache API, die Komplikationen, die bei der Verwendung von Horovod für verteiltes训练entstehen,抽象者kann。
优化logistic回归与Baumklassifizierung für MLlib:Zu Databricks运行时für机器学习gehört auch die Optimierung der bekanntesten Estimators。Im Vergleich mit Apache Spark 2.4.0, können Sie hier nun eine um bis zu 40 Prozent höhere Geschwindigkeit erzielen。
Machine Learning Runtime baut auf Databricks Runtime auf。Mit jder neuen Version von Databricks Runtime erhält es dementsprechend auch ein更新。Erhältlich ist es für die gesamte databeks - producduktpalette wie Azure Databricks, AWS-Cloud, GPU-Cluster和CPU-Cluster。
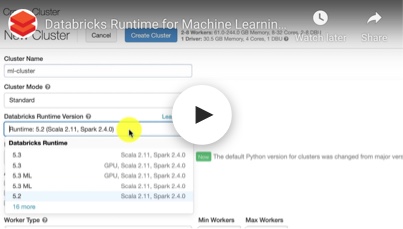
Wenn Sie ML Runtime nutzen möchten, wählen Sie beim Erstellen Ihres Clusters einfach die ML- version von Runtime aus。