

实时机器学习推理的基础设施设计
本文由Headspace高级软件工程师Yu Chen撰写。Headspace的核心产品是iOS、Android和基于web的应用程序。
2022年3月1日 在机器学习
网上购物已经成为普通消费者的默认体验,即使是老牌实体零售商也开始接受电子商务。为了确保平稳的用户体验,电子商务需要考虑多个因素。产品推荐系统是一个核心功能,它已被证明可以改善用户体验,从而为在线零售商带来收入。在今天这个时代,人们几乎不可能进入一个面向购物者的网站,却看不到产品推荐。
但并不是所有的推荐人都生来平等,也不应该如此。不同的购物体验需要不同的数据来进行推荐。要让购物者获得个性化的体验,需要多种数据和推荐方法。大多数推荐人关注的是在用户和产品属性数据上训练机器学习模型,这些数据被按摩成表格形式。
我们可以处理的用于构建推荐的数据的数量和种类呈指数级增长,在计算和算法方面也取得了显著的进步。特别是,存储、处理和从图像数据中学习的手段在过去几年中有了显著的增加。这使得零售商可以超越简单的协同过滤算法,使用更复杂的方法,如图像分类和深度卷积神经网络,这些方法可以考虑商品的视觉相似性作为推荐的输入。这一点尤其重要,因为网上购物主要是一种视觉体验,许多消费品都是根据美学来判断的。
在本文中,我们将更改脚本并展示端到端过程,用于训练和部署一个基于图像的相似性模型,该模型可以作为推荐系统的基础。此外,我们将展示Databricks中可用的底层分布式计算如何帮助扩展训练过程,以及Lakehouse、Delta Lake和MLflow的基本组件如何使这个过程简单且可重复。
相似度模型的训练采用对比学习。在对比学习中,目标是使机器学习(ML)模型学习一个嵌入空间,其中相似项之间的距离最小化,不同项之间的距离最大化。在这里,我们将使用时尚MNIST数据集,其中包括大约70,000张各种服装的图像。基于上述描述,在这个标记数据集上训练的相似度模型将学习到一个嵌入空间,其中相似产品(例如靴子)的嵌入距离较近,而不同的产品(例如靴子和套头衫)的嵌入距离较远。在监督对比学习中,除了原始像素数据本身之外,算法还可以访问元数据,例如图像标签,以进行学习。
这可以说明如下。
用于图像分类的传统ML模型侧重于减少损失函数,该函数旨在最大化预测的类别概率。然而,推荐系统从根本上尝试做的是建议给定项目的替代品。这些项目可以被描述为在某个嵌入空间中彼此比其他项目更接近。因此,在大多数情况下,与传统的监督学习相比,推荐系统的工作原理与对比学习机制的工作原理密切一致。此外,基于相似度,相似度模型更擅长推广到未见过的数据。例如,如果原始训练数据不包含任何夹克衫的图像,但包含卫衣和靴子的图像,在此数据上训练的相似性模型将定位夹克衫图像的嵌入位置更接近卫衣,而远离靴子。这在推荐方法中是非常强大的。
具体来说,我们使用Tensorflow相似库来训练模型和Apache Spark,结合Horovod在GPU集群上扩展模型训练。我们使用Hyperopt通过Spark在GPU集群上扩展超参数搜索,只需几行代码。所有这些实验都将被MLflow跟踪和记录,以保持模型谱系和可重复性。Delta将用作跟踪数据沿袭的数据源格式。
的supervised_hello_world例子在Tensorflow Similarity Github存储库中为手头的任务提供了一个完美的模板。我们对推荐人所做的事情类似于相似度模型的行为方式。也就是说,您选择一个项目的图像,然后查询模型以返回n个最相似的项目,这些项目也可能引起您的兴趣。
为了充分利用Databricks平台,最好是启动一个集群,其中包含bob体育客户端下载一个用于驱动程序的GPU节点(因为我们最初将进行一些单节点训练),两个或更多GPU工作节点(因为我们将扩展超参数优化并分发训练本身),以及一个Databricks机器学习运行时为10.0或以上。对于这个练习,T4 GPU实例是一个很好的选择。
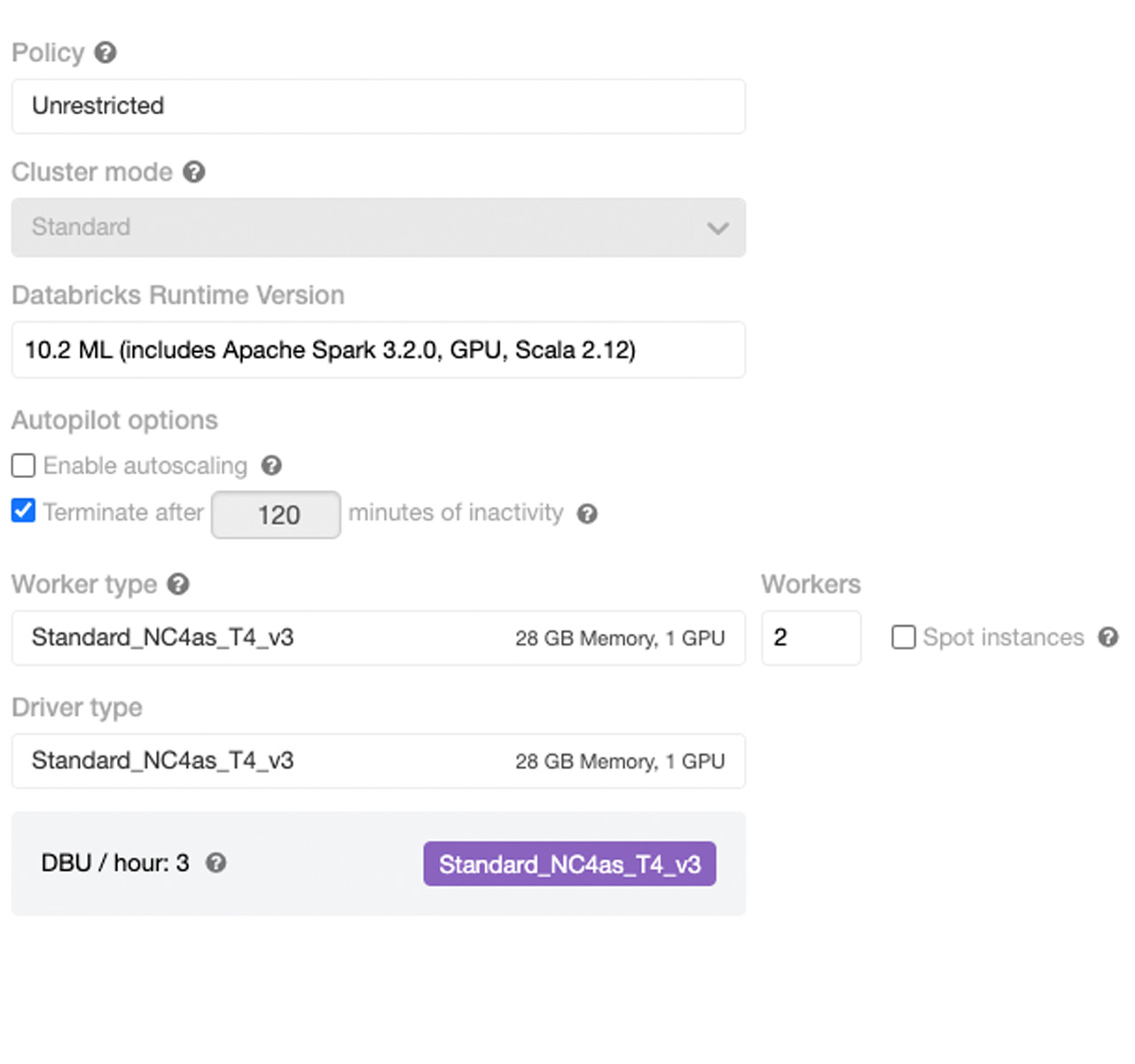
整个过程不超过5分钟(包括集群启动时间)。
时尚MNIST训练和测试数据可以使用一系列简单的shell命令和帮助函数' convert '(从原始版本修改到:'https://pjreddie.com/projects/mnist-in-csv/’(减少不必要的文件I/O)可用于将图像和标签文件转换为表格格式。随后,这些表可以存储为Delta表。
将训练和测试数据存储为Delta表很重要,因为我们增量地将新的观察结果(新图像及其标签)写入这些表,Delta事务日志可以跟踪数据的更改。这使我们能够跟踪新的数据,我们可以使用这些数据在我们稍后将描述的相似度索引中重新索引数据。
用于训练相似度模型的神经网络与用于常规监督学习的神经网络非常相似。这里的主要区别在于我们使用的损失函数和度量嵌入层。在这里,我们使用了一个简单的卷积神经网络(cnn)架构,这是常见的计算机视觉应用.然而,代码中有一些细微的差异,使模型能够使用对比方法进行学习。
您将看到多类分类的多相似度损失函数,而不是在其他情况下看到的软最大损失函数。与其他用于对比学习的传统损失函数相比,多相似度损失考虑了多个相似点。这些相似点包括自相似、正相对相似和负相对相似。Multi-similarity Loss通过迭代硬对挖掘和加权来度量这三种相似性,在对比学习任务中带来显著的性能提升。这一具体损失的进一步细节将在原出版物由王等人.
在本例的上下文中,这种损失有助于最小化相似项之间的距离,并最大化嵌入空间中不同项之间的距离。中的supered_hello_world示例中已解释Tensorflow_Similarity存储库,使用MetricEmbedding()添加到模型中的嵌入层是一个L2归一化的密集层。对于每个小批,从随机采样的类中随机选择固定数量的嵌入(对应于图像)(类的数量是一个超参数)。然后在Multi-Similarity Loss层中对这些样本进行硬对挖掘和迭代加权,其中来自三种不同类型相似性的信息被用于惩罚更接近的不同样本。
如下图所示。
' ' 'defget_model():从tensorflow_similarity.layers进口MetricEmbedding从tensorflow.keras进口层从tensorflow_similarity.models进口SimilarityModel输入=层。输入(形状= (28,28,1))x = layers.experimental.预处理. rescale (1/255)(输入)X =层。Conv2D (32,3.激活=“relu”) (x)X =层。MaxPool2D (2,2) (x)X =层。辍学(0.3) (x)......X =层。辍学(0.3) (x)x = layers.Flatten()(x)输出=度量嵌入(128) (x)返回SimilarityModel(输入、输出)...
...损失= MultiSimilarityLoss(距离=距离)模型。编译(优化器=亚当(learning_rate),损失=损失)
' ' '在TensorFlow similarity中,理解训练好的相似度模型是如何发挥作用的是很重要的。在模型的训练过程中,我们学习了最小化相似项之间距离的嵌入。标准库的Indexer类提供了基于所选距离度量从这些嵌入构建索引的功能。例如,如果选择的距离度量是“余弦”,索引将基于余弦相似度建立。
索引的存在是为了快速找到嵌入“紧密”的项。为了快速搜索,必须以相对较低的延迟检索最相似的条目。这里的查询方法使用快速近似近邻搜索来检索给定项目的n个最近邻居,然后我们可以将其作为推荐。
' ' '使用训练数据建立索引x_index, y_index = select_examples(x_train, y_train, CLASSES,20.)tfsim_model.reset_index ()tfsim_model。在dex(x_index, y_index, data=x_index)使用查找方法查询索引tfsim_model。查找(x_display k =5)...' ' '这个模型可以在单个节点上训练,没有问题,我们可以建立一个索引来查询它。随后,训练好的模型可以在MLflow的帮助下通过REST端点进行查询。这是有意义的,因为本例中使用的时尚MNIST数据集很小,很容易适合单个启用GPU的实例的内存。然而,在实践中,产品的图像数据集可以跨越几个gb的大小。此外,即使是在小型数据集上训练的模型,如果在单个启用GPU的实例上完成,那么寻找模型的最佳超参数的过程可能是一个非常耗时的过程。在这两种情况下,Spark所支持的并行只需要改变几行代码就能创造奇迹。
在神经网络的情况下,你可以认为人工神经元的权重是在训练过程中更新的参数。这是通过梯度下降和误差反向传播来实现的。然而,诸如层数、每层神经元数,甚至神经元中的激活函数等数值在这个过程中都没有得到优化。这些被称为超参数,我们必须以一种聪明的方式搜索所有可能的超参数组合的空间,以便继续建模过程。
传统的模型调优(超参数搜索的简写)可以通过简单的方法完成,例如穷举网格搜索或随机搜索。Hyperopt是一个被广泛采用的用于模型调优的开源框架,它在这个过程中利用了更有效的贝叶斯搜索。
这种搜索可能很耗时,即使使用贝叶斯搜索等智能算法也是如此。然而,Spark可以与Hyperopt一起工作,在整个集群中并行化这个过程,从而大大减少所消耗的时间。要执行这种扩展,所要做的就是在hypropt通常使用的代码中添加2行python代码。注意并行度参数是如何设置为2的(即集群gpu的数量)。
' '`..从hyperopt导入SparkTrials..试验= SparkTrials(并行度= 2)..Best_params = fmin(fn = train_hyperopt,空间=空间,算法=算法,max_evals = 32,试验=试验)..`' '这种并行工作的机制可以如下所示。
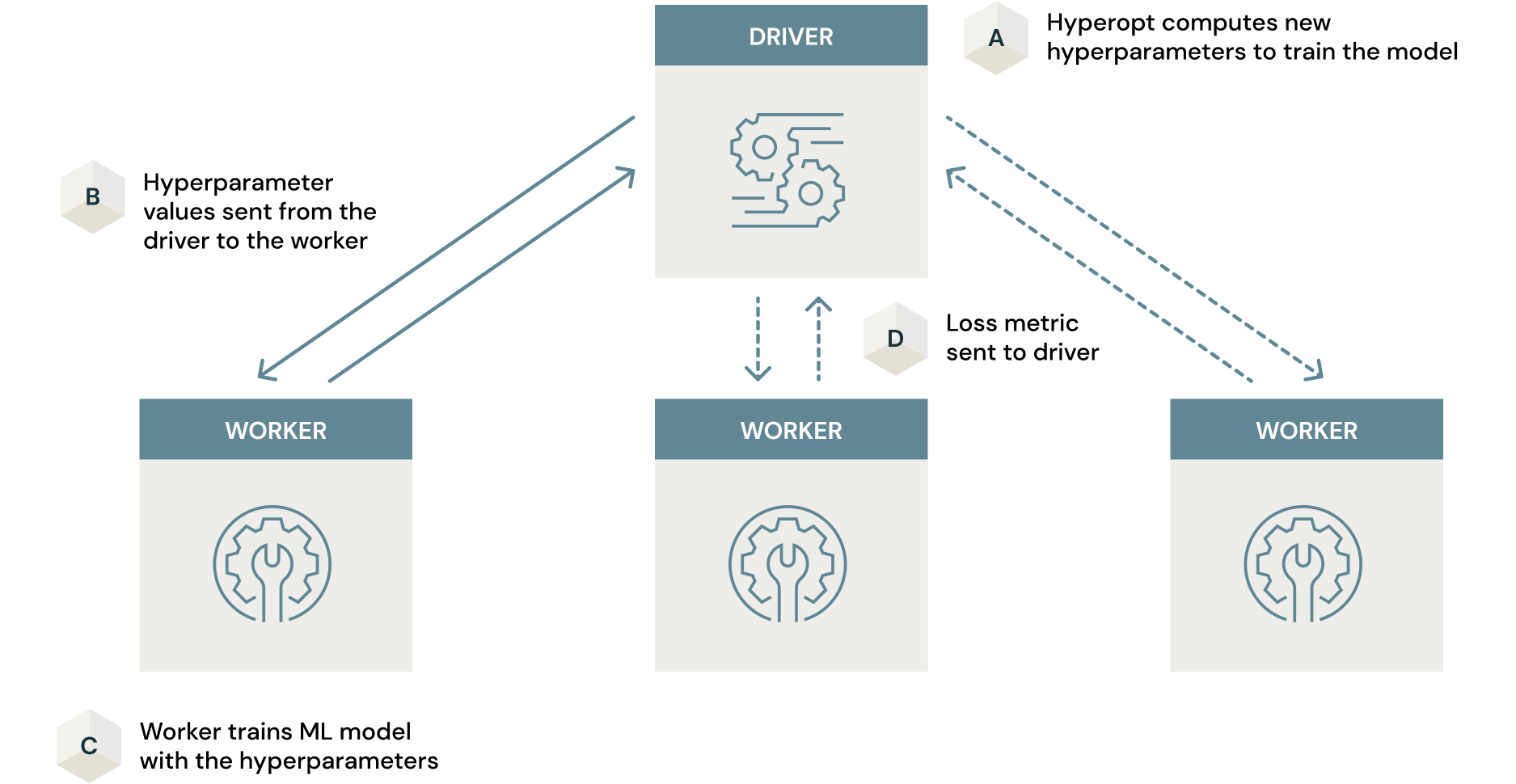
这篇文章在Python中扩展Hyperopt以优化机器学习模型对这是如何工作的进行了极好的深入探讨。在相似模型的情况下,对于这个过程使用GPU支持的节点是很重要的,特别是在这个利用Tensorflow的例子中。任何节省的时间都可能被不必要的长时间和低效的利用CPU节点的训练过程抵消。本文对此进行了详细的分析文章.
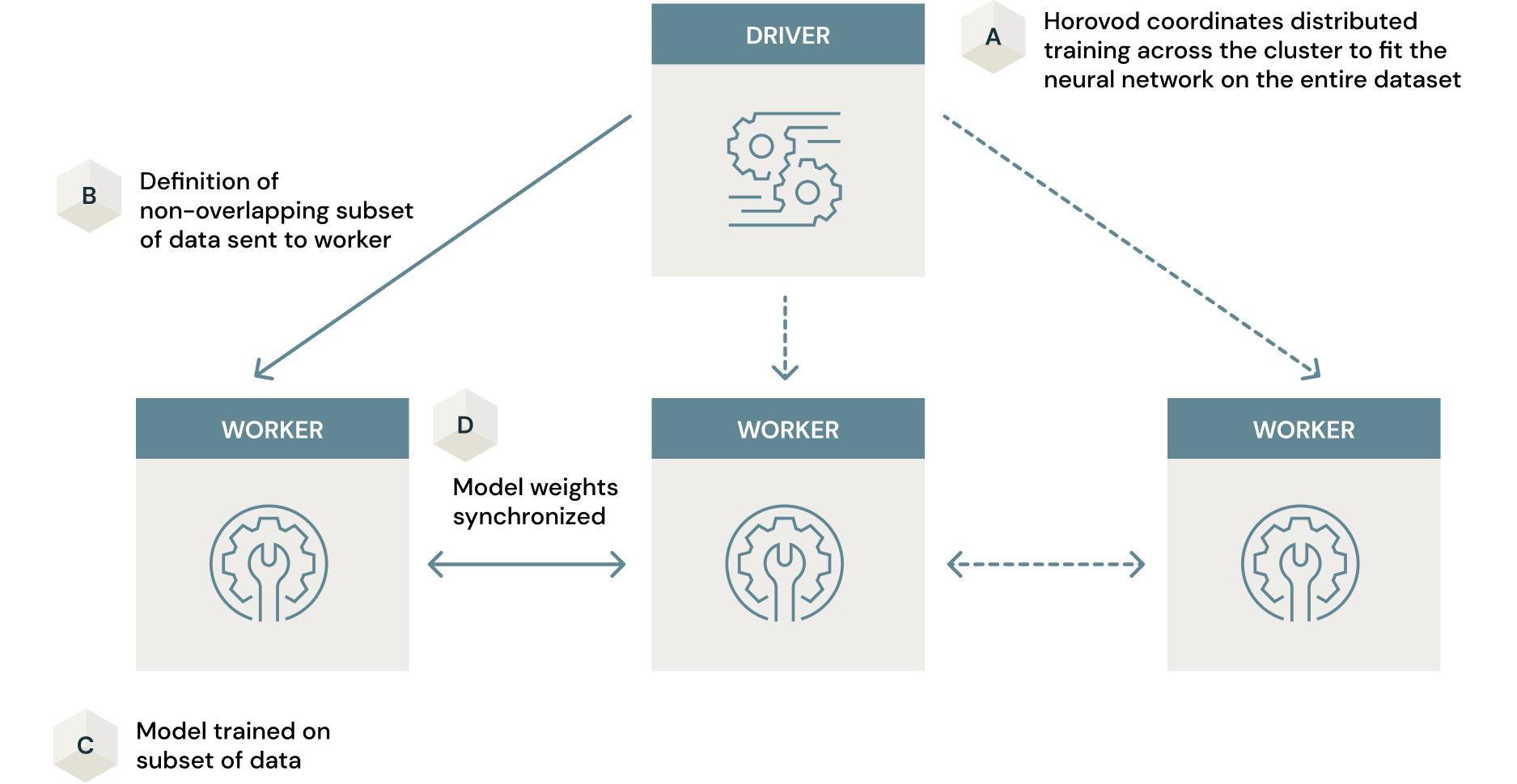
正如我们在前一节中看到的,Hyperopt利用Spark通过并行训练多个具有不同超参数组合的模型来分布超参数搜索。每个模型的训练都在一台机器上进行。分布式模型训练是另一种使用Spark的分布式处理可以使训练过程更有效的方式。在这里,单个模型在集群中的许多机器上进行训练。
如果训练数据集很大,这可能是训练生产就绪相似性模型的另一个瓶颈。实现这一点的一些方法包括仅在一台机器上的数据子集上训练模型。这是以最终模型次优为代价的。然而,通过Spark和Horovod(一个用于在集群中并行化模型训练过程的开源框架),这个问题可以得到解决。Horovod与Spark相结合,提供了一种数据并行方法,以最小的代码更改在大规模数据集上建模训练。在这里,一旦传递了数据子集的定义,模型就在集群中的每个节点上并行训练,以学习神经网络的权重。这些权重在整个集群中同步,从而得到最终的模型。最终,您将得到一个高度优化的模型,该模型在整个数据集上进行训练,而花费的时间只相当于在一台机器上进行训练的一小部分时间。这篇文章如何在6个简单步骤中扩展深度学习详细介绍了如何利用分布式计算进行深度学习。再次强调,Horovod是最有效的用于GPU集群.否则,跨集群扩展模型训练的优势将无法带来预期的效率。
处理大型图像数据集进行模型训练是另一个需要考虑的重要因素。在本例中,时尚MNIST是一个非常小的数据集,它根本不会对集群造成压力。然而,大型图像数据集经常出现在企业中,用例可能涉及在此类数据上训练相似性模型。在这里,Petastorm,一个基于深度学习构建的数据缓存库,将非常有用。链接笔记本将帮助您在用例中利用这项技术。
一旦训练出具有最优超参数的最终模型,部署相似模型的过程是一个微妙的过程。这是因为模型和索引需要一起部署。然而,使用MLflow,这个过程非常简单。如前所述,通过使用从查询样例推断的嵌入查询数据索引来检索建议。这可以用一种简单的方式说明如下。
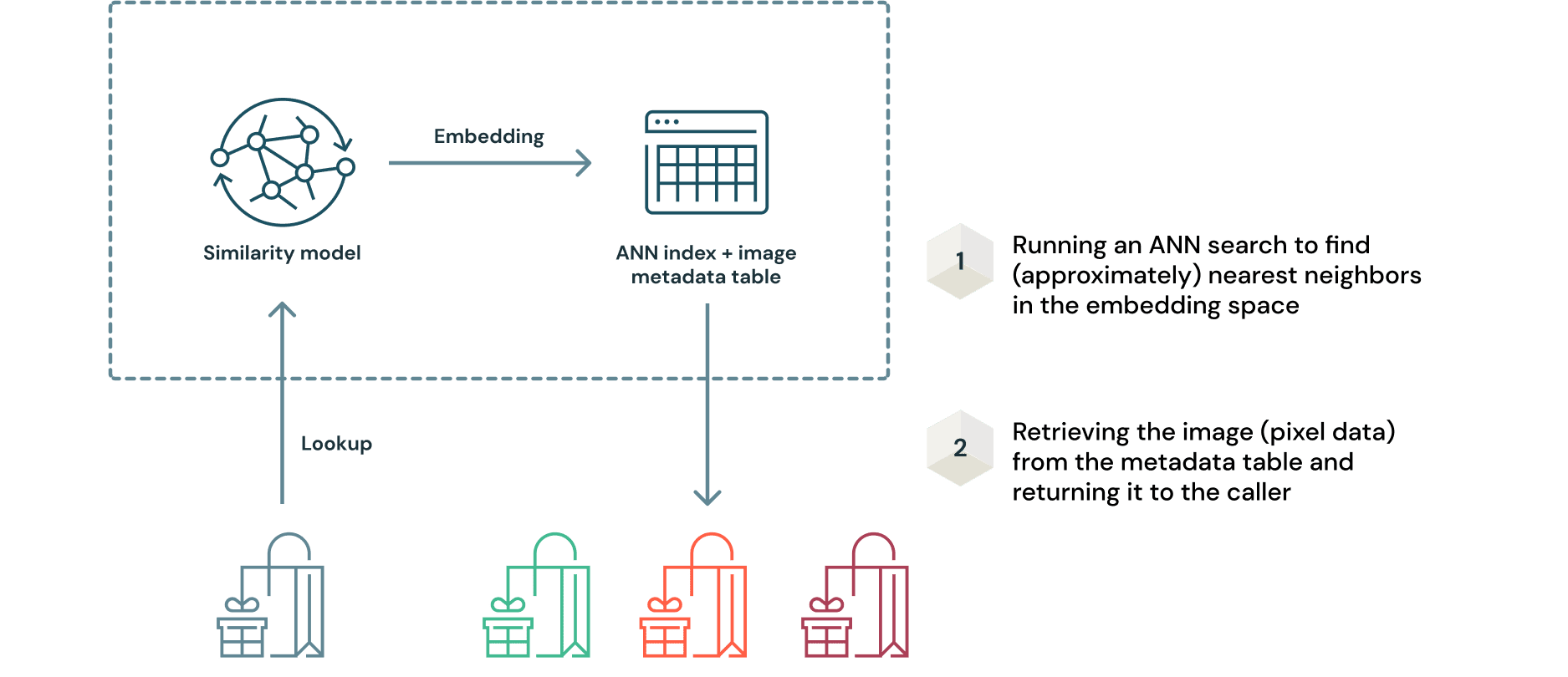
这种方法的一个关键优点是,当接收到新的图像数据时,不需要重新训练模型。可以使用模型生成嵌入,并将其添加到人工神经网络索引中进行查询。由于原始图像数据是Delta格式,对表的任何增量都将记录在增量事务日志.这确保了整个数据摄取过程的可重复性。
在MLflow中,有许多流行的(甚至晦涩的)ML框架的模型风格,可以轻松地打包模型以提供服务。在实践中,有许多情况下,训练过的模型必须与预处理和/或后处理逻辑一起部署,例如可查询的相似性模型和ANN索引。这里我们可以用mlflow.pyfunc模块创建一个自定义的“推荐模型”类(命名为TfsimWrapper在本例中)封装推理和查找逻辑。这链接提供关于如何完成此工作的详细文档。
' ' '进口mlflow.pyfunc类TfsimWrapper(mlflow.pyfunc.PythonModel):"""模型输入是一个单行单列的pandas数据帧,base64编码的字节字符串,即字节类型。列名在这里是input """ """"模型输出是一个pandas数据框架,其中每一行(即。元素(因为只有一列)是一个转换为十六进制的字符串,必须转换回字节,然后使用np.frombuffer(…)转换为numpy数组,并重新塑造为(28,28),然后可视化(如果需要)"""defload_context(自我,上下文):进口tensorflow_similarity作为tfsim从tensorflow_similarity.models进口SimilarityModel从tensorflow.keras进口模型进口熊猫作为pd进口numpy作为np
自我。tfsim_model = models.load_model(context.artifacts[“tfsim_model”])self.tfsim_model.load_index (context.artifacts [“tfsim_model”])def预测(Self context model_input):从公益诉讼进口图像进口base64进口ioimage = np.array(图像。开放(io.BytesIO (base64.b64decode (model_input [“输入”] [0] .encode ()))))# model_input必须是(1,28,28)的形式Image_reshaped = image. remodeling (-1,28,28)/255.0图片= np.array(self.tfsim_model. array)。查找(image_reshaped k =5))Image_dict = {}为我在范围(5):Image_dict [i] = images[0][我].data.tostring()。十六进制()返回pd.DataFrame.from_dict (image_dict东方=“指数”)
' ' '模型构件可以在同一个MLflow UI中作为REST端点进行记录、注册和部署,也可以利用MLflow API。除了这个功能之外,还可以将输入和输出模式定义为日志记录过程中的模型签名,以帮助快速切换到部署。这是通过包含以下3行代码自动处理的
' '`从mlflow.models.signature导入infer_signature签名= infer_signature(sample_image, loaded_model.predict(sample_image))mlflow. pyfunc_log_model (artifact_path=mlflow_pyfunc_model_path, python_model=TfsimWrapper(), artifacts=artifacts,Conda_env = Conda_env,签名=签名)`' '一旦推断出签名,数据输入输出模式期望将在UI中显示,如下所示。
一旦创建了REST端点,您就可以通过转到工作区左侧滑动面板上的用户设置来方便地生成一个承载令牌。使用此承载令牌,您可以在任何面向最终用户的应用程序或依赖于模型推断的内部流程中插入为REST端点自动生成的Python包装器代码。
下面的函数将帮助解码来自REST调用的JSON响应。
' ' '进口numpy作为npdefprocess_response_image(我):”“反应”是返回的JSON对象.我们可以循环一下对象而且返回重塑后的numpy数组为每个推荐的图像,然后可以渲染" " "Single_image_string = response[i][“0”]Image_array = np.frombuffer(字节.fromhex (single_image_string) dtype = np.float32)Image_reshaped = np。重塑(image_array, (28,28))返回image_reshaped
' ' '用于查询此端点的简单Streamlit应用程序的代码可在此博客文章的存储库.下面的简短录音展示了推荐人的实际行动。
通常,对许多人来说,摄取和格式化数据、模型优化、大规模训练以及为推荐部署相似度模型的过程是一个新颖而微妙的过程。通过Databricks提供的高度优化的管理Spark、Delta Lake和MLflow基础,这个过程在Lakehouse平台上变得简单而直接。bob体育客户端下载由于您可以访问托管计算集群,因此提供多个gpu的过程是无缝的,整个过程只需几分钟。下面链接的笔记本将详细地引导您完成构建和部署相似模型的端到端过程。我们欢迎您试用它,并根据您的需要定制它,并使用Databricks构建您自己的生产级基于ml的图像推荐系统。

