
如何建立一个可扩展的广泛和深入的产品推荐



2021年6月9日 在工程的博客
下载笔记本电脑在本文中都有引用。
我有一家最喜欢的咖啡店,多年来一直光顾。当我走进来的时候,咖啡师知道我的名字,并问我是否要我常喝的饮料。大多数时候,答案是“是的”,但偶尔,我看到他们有一些应季的商品,就会让我推荐。因为我通常点一杯微甜的拿铁,再加一杯浓咖啡,咖啡师可能会推荐黑巧克力摩卡,而不是那种堆积着鲜奶油和糖屑的水果混合物。咖啡师了解我的明确偏好,并能够根据我过去的选择进行概括,这为我提供了高度个性化的体验。因为我知道咖啡师了解我,理解我,所以我相信他们的建议。

就像我最喜欢的咖啡店里的咖啡师一样,推荐系统的广泛和深度学习能够根据用户行为和客户互动来记忆和概括产品推荐。首先,我由谷歌介绍在其谷歌Play应用程序商店中使用,广泛和深度机器学习(ML)模型已经在各种在线场景中流行起来,因为它能够个性化用户参与,甚至在数据输入稀疏的“冷启动问题”场景中也是如此。
广泛而深入的推荐人的目标是提供和我们最喜欢的咖啡师一样的客户亲密程度。该模型使用显式和隐式反馈来为客户扩展考虑事项集。广泛而深入的推荐人超越了一些协作过滤器中对客户反馈的简单加权平均,以平衡对个人的了解和对类似客户的了解。如果处理得当,这些建议会让客户感到被理解,这将为客户和企业带来更大的价值。
理解模型设计
要理解深度推荐和广泛推荐的概念,最好将其视为两个独立但相互协作的引擎。宽模型,在文献中通常被称为线性模型,记住用户和他们过去的产品选择。它的输入可能仅仅由用户标识符和产品标识符组成,尽管也可能包含与模式相关的其他属性(例如一天中的时间)。
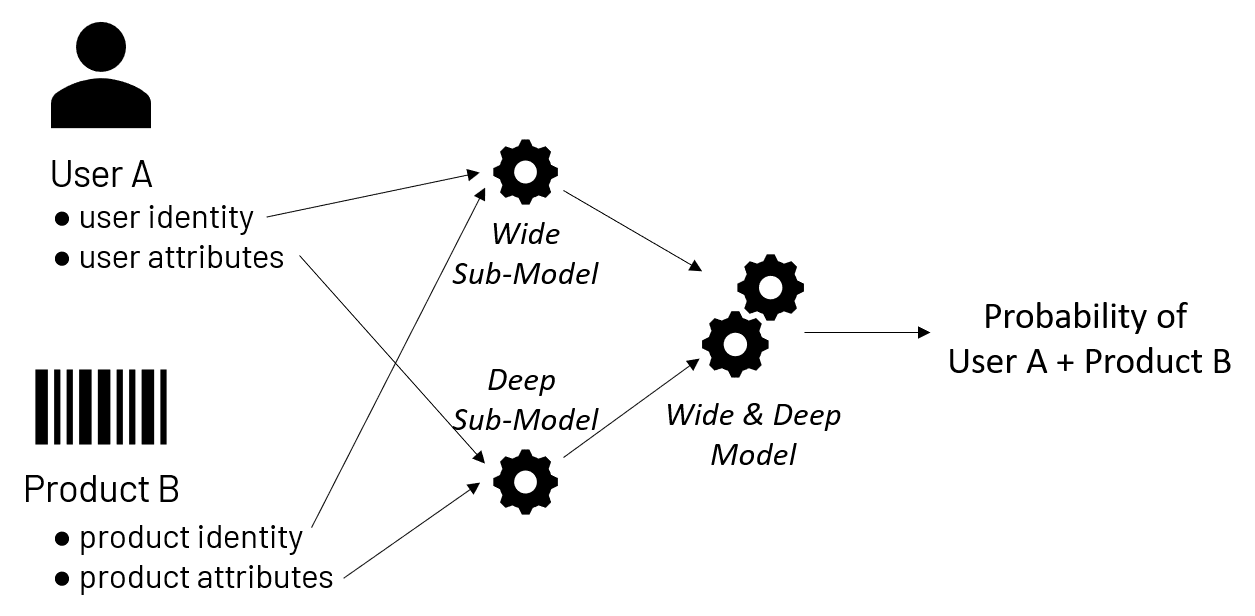
模型的深层部分,因为它是一个深层神经网络,所以被命名为深层神经网络,检查用户的可归纳属性及其产品选择。从这些数据中,该模型了解到更广泛的特征,这些特征倾向于用户的产品选择。
宽子模型和深子模型一起根据单个用户的历史产品选择进行训练,以预测未来的产品选择。最终的结果是一个单一的模型,能够计算用户购买特定商品的概率,同时考虑到用户过去的选择和对用户偏好的概括。这些概率形成了用户特定产品排名的基础,可用于提出建议。
构建模型
广深推荐的直观逻辑掩盖了其实际结构的复杂性。必须为模型的每个宽部分和深部分分别定义输入,并且必须以协调的方式对每个输入进行训练,以获得单个输出,但是使用针对每个子模型性质的优化器进行调优。值得庆幸的是,Tensorflow DNNLinearCombinedClassifier估计器提供预打包的体系结构,极大地简化了整个模型的组装。
培训
对大多数组织来说,挑战在于训练推荐者使用数据中发现的大量用户-产品组合。使用Petastorm它是一个开源库,用于将Apache Spark™中组装的大型数据集提供给Tensorflow(以及其他ML库),我们可以在高速临时存储上缓存数据,然后在训练期间以可管理的增量将数据读取到模型中。这样做,我们限制了与训练相关的内存开销,同时保持了性能。
调优
调优模型成为下一个挑战。各种模型参数控制着它得到最优解的能力。处理潜在参数组合的最有效方法是简单地迭代一些训练周期,在每次运行时比较模型的评估指标,以确定理想的参数组合。通过利用hyperopt与SparkTrails,我们可以在许多计算节点上并行执行这项工作,从而可以及时地执行优化。
部署
最后,我们需要部署模型,以便与各种零售应用程序集成。利用MLflow允许我们持久化我们的模型,并将其打包部署到各种各样的微服务层,包括Azure机器学习、AWS Sagemaker、Kubernetes和Databricks模型服务。
虽然这看起来像是为了构建一个单一模型而将大量的技术结合在一起,但Databricks将所有这些技术集成在一个平台中,为数据科学家、数据工程师和数据工程师提供服务bob体育客户端下载MLOps工程师需要统一的体验。这些技术的预集成意味着各种角色可以更快地工作并利用额外的功能,例如自动跟踪模型,以提高组织模型构建工作的透明度。
要查看如何在Databricks上建立一个广泛而深入的推荐模型的端到端示例,请查看以下笔记本: