

实时机器学习推理的基础设施设计
本文由Headspace高级软件工程师Yu Chen撰写。Headspace的核心产品是iOS、Android和基于web的应用程序。
本文由Headspace高级软件工程师Yu Chen撰写。
顶部空间的其核心产品是iOS、Android和基于网络的应用程序,专注于通过正念、冥想、睡眠、锻炼和专注内容来改善用户的健康和幸福。机器学习(ML)模型是我们用户体验的核心,它为用户提供新的相关、个性化的内容,让用户在他们的终身旅程中养成一致的习惯。
当输入到ML模型的数据可以立即用于即时决策时,通常是最有价值的,但是,传统上,消费者数据在机器学习和数据分析团队利用它之前,会被摄取、转换、持久化并休眠很长一段时间。
找到一种利用用户数据生成实时洞察和决策的方法,意味着像Headspace应用程序这样面向消费者的产品可以极大地缩短端到端用户反馈循环:用户在片刻之前执行的操作可以被整合到产品中,为用户生成更相关、个性化和针对具体情况的内容推荐。
这意味着我们的ML模型可以包含动态特征,这些特征可以在用户一天的过程中更新,甚至可以在单个会话中更新。这些特性的例子包括:
考虑到用户体验,Headspace机器学习团队通过将基础设施系统分解为模块化发布、接收器、编制和上菜层。该方法利用了Apache Spark™,结构化数据流,AWS SQS, Lambda和Sagemaker为我们的ML模型提供实时推理能力。
在这篇博文中,我们将从技术上深入探讨我们的架构。在描述了我们对实时推理的需求之后,我们讨论了适应传统离线ML工作流以满足我们需求的挑战。然后,在讨论关键体系结构组件的细节之前,我们将给出体系结构概述。
为了方便实时推断,个性化用户的内容推荐,我们需要
我们大致的端到端延迟目标(从用户事件转发到Kinesis流到实时推断预测)是30秒.
上述需求通常是离线模型无法解决(也不需要解决)的问题,这些模型提供日常批处理预测。从ELT / ETL数据管道提取和转换的记录中进行推断的ML模型通常具有原始事件数据的几个小时交货时间.传统上,ML模型的训练和服务工作流将涉及以下步骤,通过每隔几小时或每天运行一次的周期性作业执行:
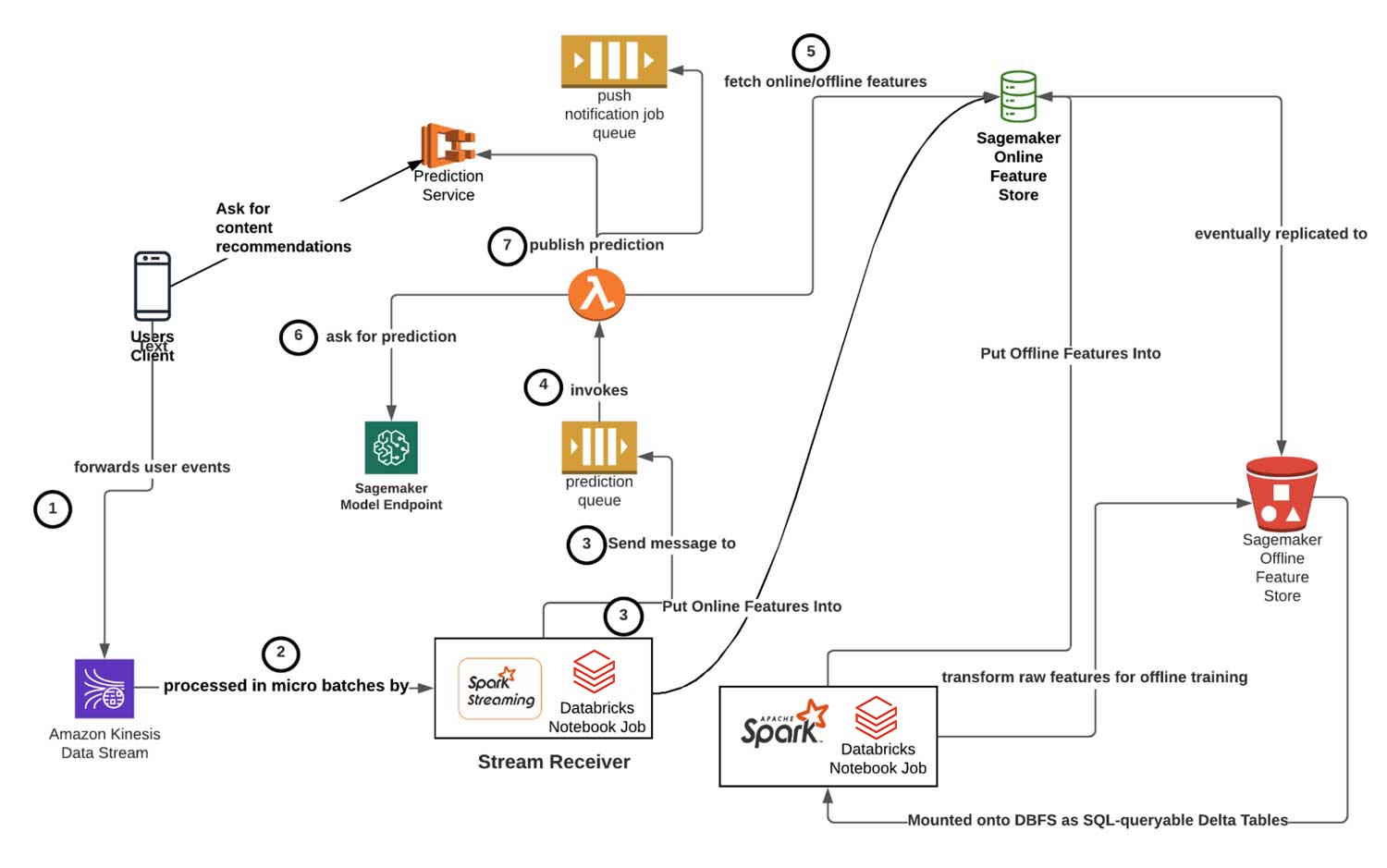
用户通过在Headspace应用程序中执行操作来生成事件,这些事件最终会被转发到我们的Kinesis Streams中,由Spark Structured Streaming进行处理。用户应用程序通过向我们的后端服务发出RESTful HTTP请求来获取接近实时的预测,传递他们的用户id和特征标志来指示要发送回哪种类型的ML建议。体系结构的其他组件将在下面更详细地描述。
ML模型在Databricks notebook中开发,并通过MLflow实验对核心离线指标进行评估,例如在k处召回推荐系统。Headspace ML团队已经编写了包装器类,扩展了MLflow中的基本Python函数模型类:
这个MLflow上下文管理器允许实验运行(参数和指标)被跟踪并易于查询与MLModel.mlflow.start_run ()作为运行:省略数据转换和特征预处理代码(样板代码)...#模型构建lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)#培训lr。fit (train_x train_y)#评估模型性能predicted_traits = lr.predict(test_x)(rmse, mae, r2) = eval_metrics(test_y, predicted_质量)在我们的自定义包装类中包装模型模型= ScikitLearnModel(lr)model.log_params(…)model.log_metrics(…)在ML跟踪服务器中记录运行结果#可选地保存模型工件到对象存储和注册模型(给它一个语义版本)#所以它可以被构建到一个sagemaker服务的Docker映像中model.save(注册=真正的)Headspace ML团队的模型包装类调用MLflow自己的save_model方法来执行大部分实现逻辑,在我们的ML Models S3桶中创建一个目录,其中包含构建MLflow模型Docker映像所需的元数据、依赖项和模型构件:
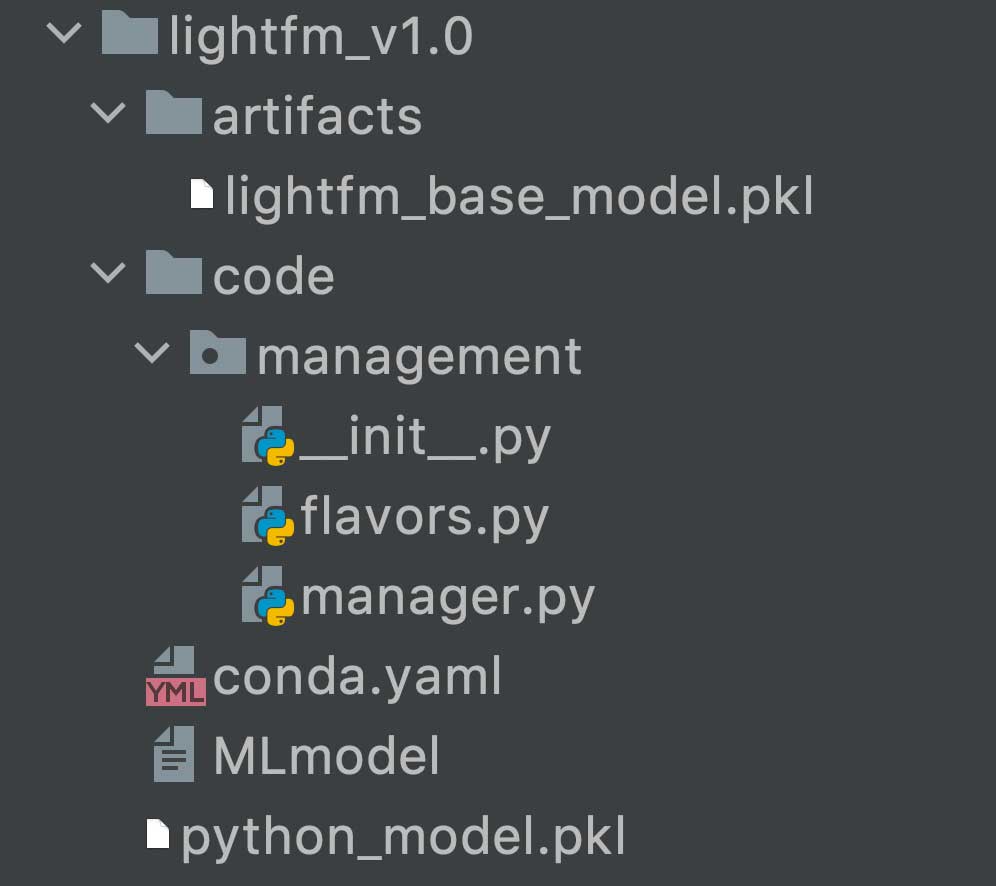
然后,我们可以创建一个正式的Github Release,指向我们刚刚保存在S3中的模型。这可以通过CircleCI等CI/CD工具获取,这些工具可以测试和构建MLflow模型映像,这些映像最终会被推送到AWS ECR,并部署到Sagemaker模型端点上。
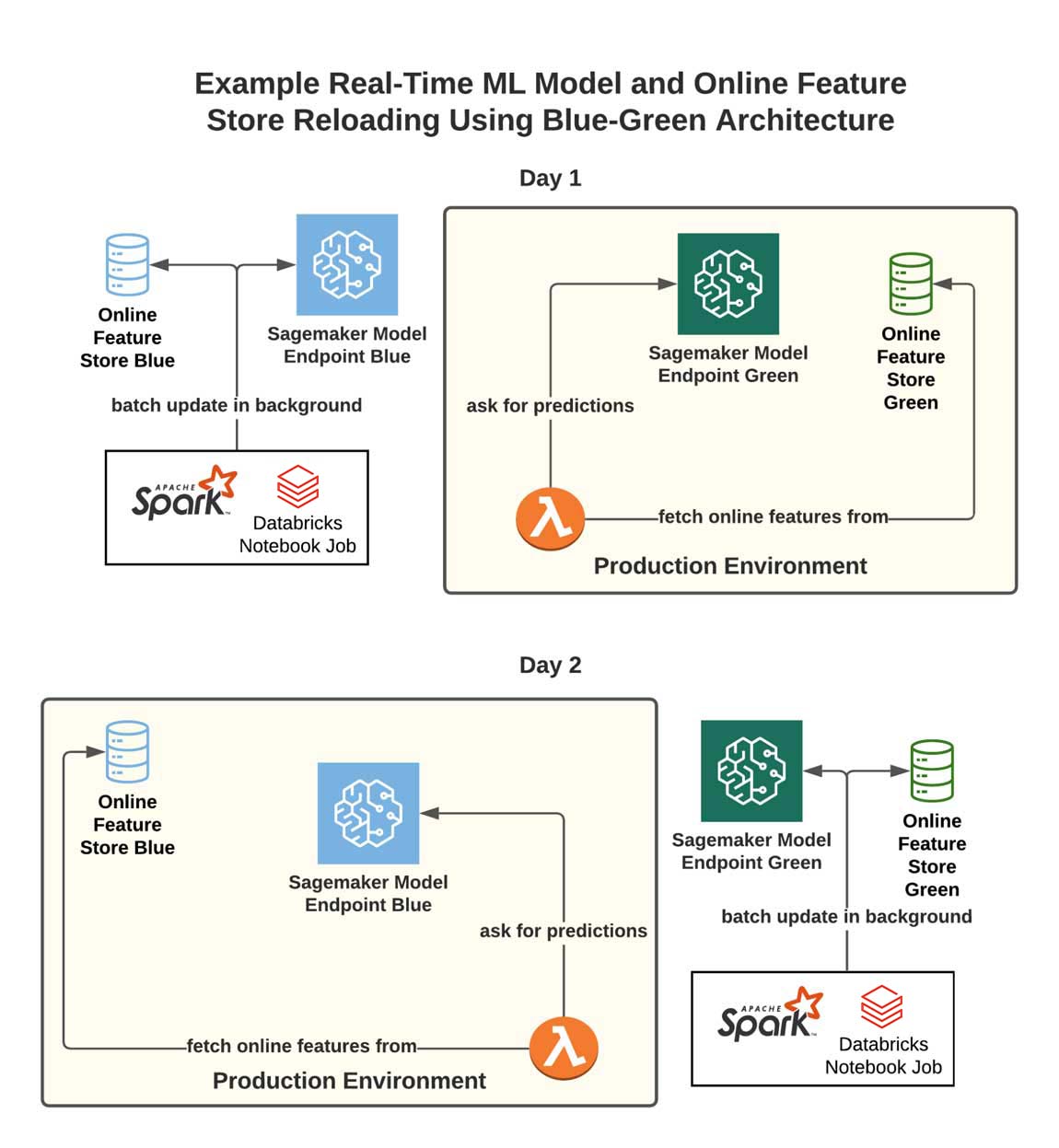
我们经常重新训练我们的模型,但是在生产中更新实时推理模型是很棘手的。AWS有多种部署模式(逐步推出、金丝雀等),我们可以利用这些模式来更新实际服务的Sagemaker模型。然而,实时模型也需要同步的在线功能商店,考虑到Headspace的用户基础规模,完全更新可能需要30分钟。假设我们不希望每次更新模型图像时都停机,我们需要小心确保我们的特征存储与我们的模型图像同步。
例如,一个将Headspace用户ID映射到用户序列ID的模型,作为协同过滤模型的一部分——我们的特征存储必须包含用户ID到序列ID的最新映射。除非用户群体保持完全静态,否则如果我们只更新模型,我们的用户ID将在推理时映射到陈旧的序列ID,导致模型为随机用户而不是目标用户生成预测。
为了解决这个问题,我们可以采用蓝绿色体系结构,该体系结构遵循蓝绿色部署的DevOps实践。工作流程如下:
Headspace用户事件动作(登录到应用程序,播放特定内容,更新订阅,搜索内容等)被聚合并转发到Kinesis数据流(图中的第一步).我们利用Databricks之上的Spark结构化流框架从这些Kinesis流中消费。结构化流有几个好处,包括:
结构化流媒体应用micro-batching将连续的事件流分解为离散的块,在小的微批数据帧中处理传入事件。
流数据管道必须区分事件时间(当事件实际发生在客户端设备上时)和处理时间(当数据被服务器看到时)。网络分区、客户端缓冲和其他一系列问题都可能导致这两个时间戳之间出现重大差异。结构化流API允许简单的逻辑定制来处理这些差异:
df.withWatermark (“eventTime”,“十分钟”) \.groupBy (“标识”,窗口(“eventTime”,“十分钟”,“5分钟”))我们使用以下参数配置结构化流作业:
使用计划作业集群显著降低了计算DBU成本,同时还降低了相关基础设施故障的可能性。在故障集群上运行的作业(可能存在缺失/不正确的依赖项、实例概要文件或过载的可用分区)将失败,直到底层集群问题得到解决,但在集群之间分离作业可以防止干扰。
然后,我们将流查询指向从专门配置的Amazon Kinesis流中读取,该流聚合了用户客户端事件(图的第二步).流查询可以使用以下逻辑进行配置:
处理器= RealTimeInferenceProcessor()
Query = df。writeStream \.option(“checkpointLocation”、“dbfs:/ / pathToYourCheckpoint”)\.foreachBatch processor.process_batch \.outputMode (“添加”) \.start ()在这里,outputMode定义数据如何写入流接收器的策略,可以取三个值:追加、完成和更新。由于结构化流作业与处理传入事件有关,因此我们选择只附加到处理“新”行。
配置检查点位置以优雅地重新启动失败的流查询是一个好主意,允许“回放”在失败之前恢复处理。
根据业务用例,我们还可以通过将参数设置为来减少延迟processingTime = " 0秒",以尽快启动每个微批处理:
查询=df。writeStream \.option(“checkpointLocation”、“dbfs://pathToYourCheckpoint”)\.foreachBatch process_batch \.outputMode \(“追加”).触发(processingTime=”0秒”)\.开始()此外,我们的Spark结构化流作业集群假设一个特殊的EC2实例概要使用适当的IAM策略与AWS Sagemaker功能组交互,并将消息放入我们的预测作业SQS队列中。
最终,由于每个结构化流作业包含不同的业务逻辑,我们将需要实现不同的微批处理函数,每个微批处理将调用一次。
在我们的例子中,我们实现了aprocess_batch首先计算/更新在线特征的方法AWS Sagemaker功能商店,然后将用户事件转发到作业队列(步骤3):
从pyspark.sql.dataframe进口DataFrame作为SparkFrame类RealTimeInferenceProcessor(处理器):def__init__(自我):自我。feature store = initialize_feature store()defprocess_batch(self, df: SparkFrame, epoch:str) - - - >没有一个:”“”具体实现了流查询的微批处理逻辑。参数:df (SparkFrame):要处理的微批Spark DataFrame。epochID (str):批的标识符。”“”self.feature_store compute_online_features (df)
forward_micro_batch_to_job_queue (df)头顶空间用户产生事件,我们的实时推理模型在下游消费这些事件,从而提出新的建议。然而,用户事件活动量并不均匀分布。有各种各样的高峰和低谷——我们的用户通常在一天中的特定时间最活跃。
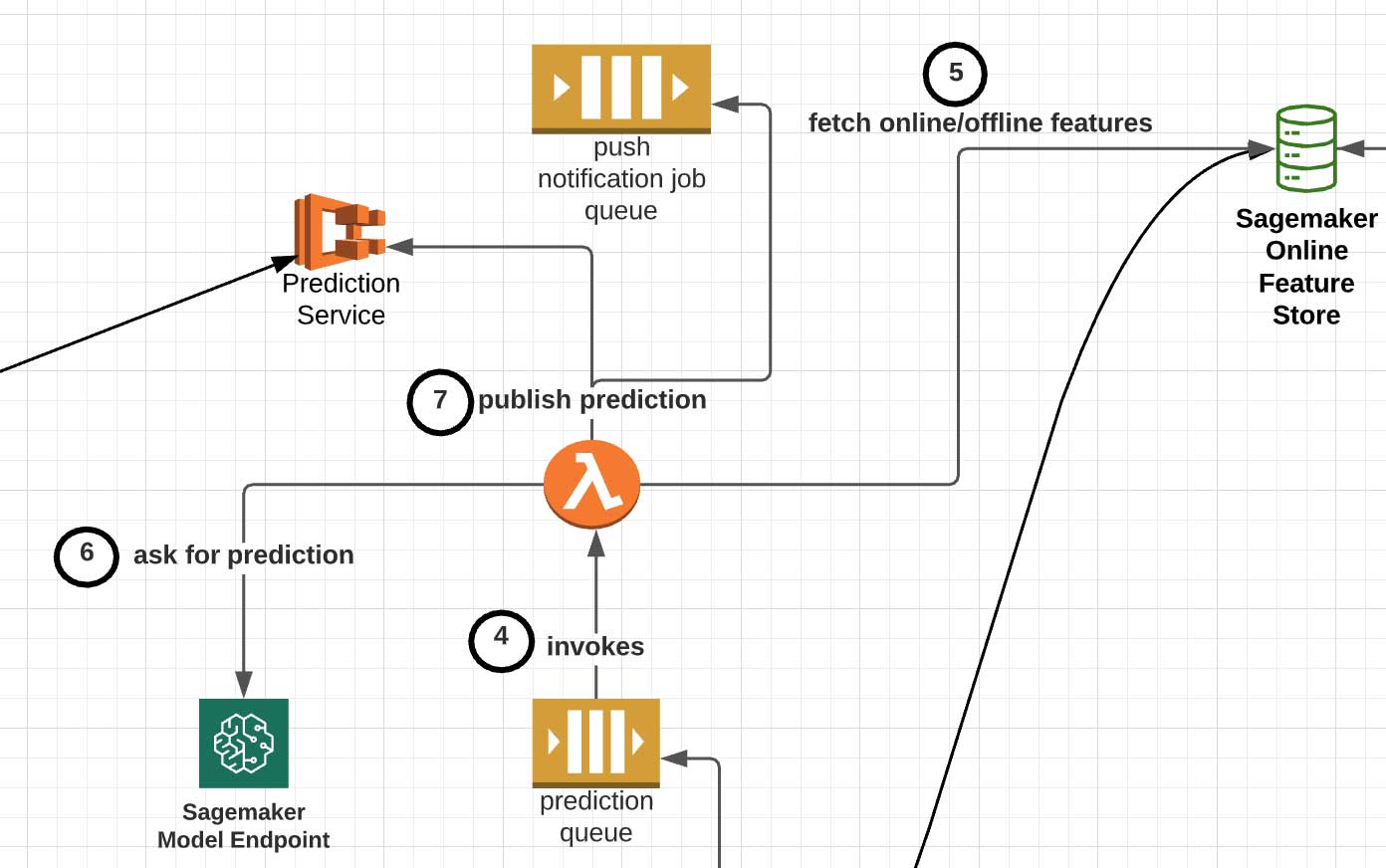
放置在SQS预测作业队列中的消息由AWS Lambda函数(图中的步骤4),执行以下步骤:
拉:这种方法包括将最终推荐的内容持久化到我们的内部预测服务,该服务负责根据客户端应用程序请求最终为用户提供Headspace应用程序的许多标签的更新个性化内容。下面是一个使用实时推理基础设施的示例实验,允许用户从应用程序的Today选项卡获取个性化推荐:

推动:该方法涉及将推荐放到另一个SQS队列中,用于推送通知或应用内模式内容推荐。下图是由用户最近搜索睡眠内容触发的应用内模式推送推荐的例子,下图是由用户最近完成内容触发的iOS推送通知:
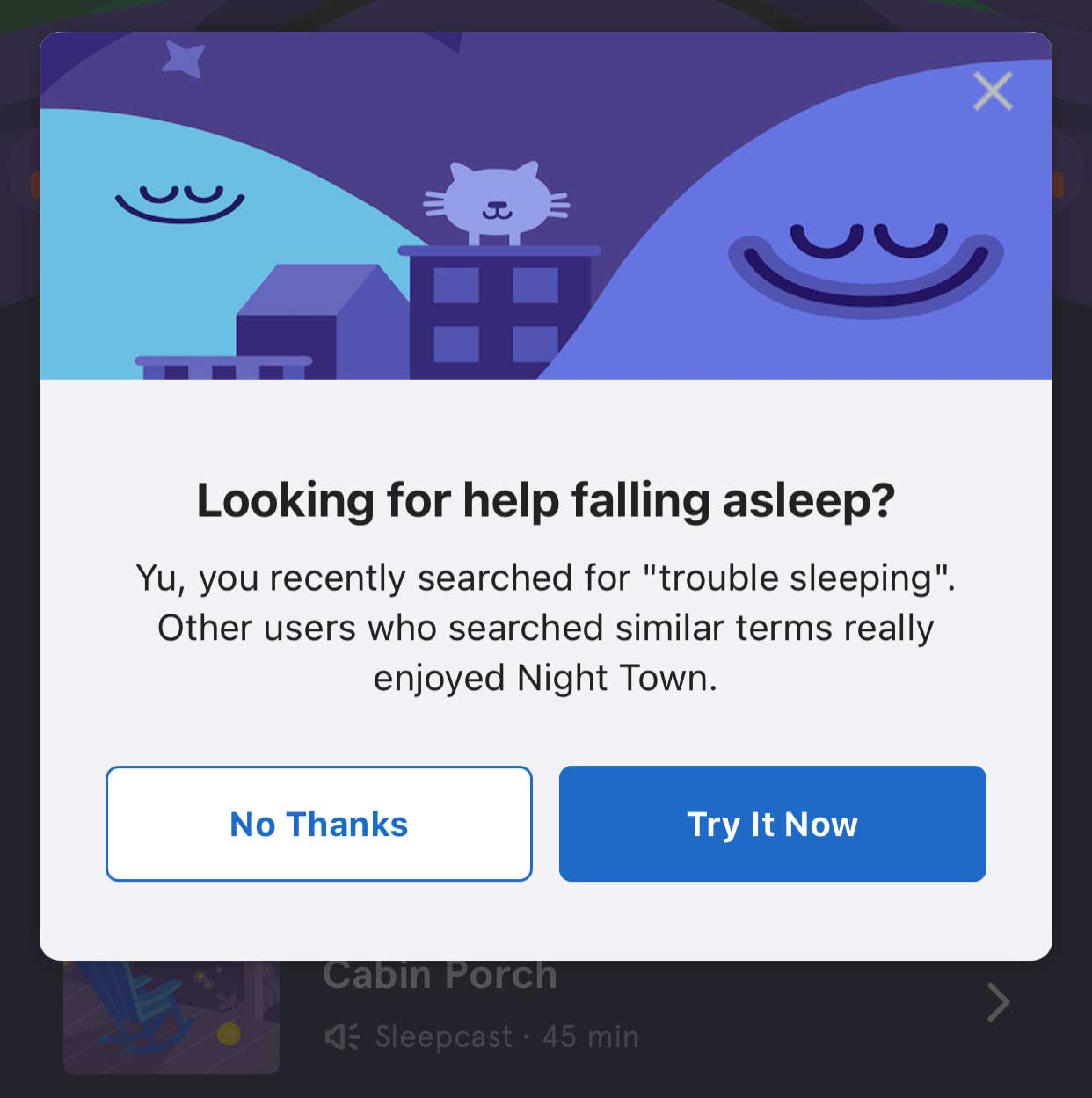

在完成一个特定的冥想或执行搜索的几分钟内,这些推送通知可以提供相关的下一个内容,而上下文仍然是用户最关心的。
此外,利用此事件队列允许重试预测作业请求——可以为SQS队列设置一个小的可见超时窗口(10-15秒),以便如果预测作业没有在该时间窗口内完成,则调用另一个Lambda函数重试。
从基础设施和体系结构的角度来看,一个重要的学习是在不同的服务之间设计灵活的移交点——在我们的例子中,是发布层、接收层、协调层和服务层。例如,
主动解决这些问题将有助于将复杂ML体系结构的各个组件解耦为更小的模块化基础设施集。
Headspace ML团队仍在为这一基础设施推出生产用例,但与其他Headspace项目和行业基准相比,最初的A/B测试和实验已经在内容启动率、内容完完率和直接/总推送打开率方面取得了显著提升。
通过利用能够实时推断的模型,Headspace显著缩短了用户操作和个性化内容推荐之间的端到端交付时间。事件流——最近的搜索,内容开始/退出/暂停,应用内导航操作,甚至生物特征数据——在当前会话中都可以被利用来不断更新我们为用户提供的建议,同时他们仍在与Headspace应用程序交互。
要了解BOB低频彩更多关于Databricks机器学习的信息,请收听2021年数据+人工智能峰会主题演讲获取优秀的概述,并在Databricks ML主页.
BOB低频彩了解更多关于Headspace的信息www.headspace.com.