
如何在6个简单步骤中扩展深度学习

简介:问题
深度学习有时看起来像巫术。它的最先进的应用程序有时令人愉快的有时令人不安的.令人惊讶的是,实现这些结果的工具大多是开源的,并且可以在云计算中按小时租用的强大硬件上发挥它们的魔力。bob下载地址
难怪很多公司都渴望申请深度学习对于更平凡的业务问题,如更好的流失预测,图像管理,聊天机器人,时间序列分析等。仅仅因为这些工具唾手可得并不意味着它们很容易使用。甚至选择正确的架构、图层和激活都是艺术而不是科学。
这篇博客不会讨论如何调整深度学习架构以获得准确性。然而,这个过程需要在试错的过程中训练大量的模型。这导致了一个更直接的问题:扩大性能深度学习训练。
调优深度学习训练不像调优ETL工作。它需要专业硬件的大量计算,最终每个人都会发现深度学习训练“太慢”。在尝试扩展时,用户往往会获得可能过度、昂贵且速度不够快的解决方案,而忽略了一些损害性能的基本错误。
本文将介绍一些基本步骤,以避免在训练中出现常见的性能缺陷,然后按照正确的顺序考虑正确的步骤,通过应用更复杂的工具和更多硬件来进行扩展。希望你会发现你的建模工作可以更快地进行,而不需要立即使用额外的gpu集群。
一个简单的分类任务
因为这里的重点不是学习问题本身,所以下面的示例将开发一个简单的数据集和要解决的问题:将加州理工256数据集从大约3万张图片中选出257(是的,257)个类别。
数据由JPEG文件组成。这些需要调整到通用尺寸299×299,以匹配下面描述的预训练的基础层。然后,这些图像被写入带有标签的Parquet文件,以方便进行更大规模的训练,稍后将介绍。这可以通过Apache Spark中的“二进制”文件数据源来实现。请参阅附带的笔记本以获得完整的源代码,但以下是重点:
img_size =299defscale_image(image_bytes):image =图像。开放(io.BytesIO (image_bytes)) .convert (“RGB”)的形象。thumbnail((img_size, img_size), Image.ANTIALIAS)X, y = image.sizewith_bg = Image.new(“RGB”, (img_size, img_size), (255,255,255))with_bg。粘贴(image, box=(img_size - x) //2, (img_size - y) //2))返回with_bg.tobytes ()
...Raw_image_df = spark.read。格式(“binaryFile”)。\选项(“pathGlobFilter”,“* . jpg”) .option (“recursiveFileLookup”,“真正的”)。\负载(caltech_256_path) .repartition (64)Image_df = raw_image_df.select(file_to_label_udf (“路径”) .alias (“标签”),scale_image_udf (“内容”) .alias (“图像”) .cache ()(train_image_df, test_image_df) = image_df.randomSplit([0.9,0.1),种子=42)
...train_image_df.write。格式(“δ”).年代ave(table_path_base +“训练”)test_image_df.write。格式(“δ”).年代ave(table_path_base +“测试”)也可以使用Spark内置的“image”数据源类型来读取这些数据。
Keras,流行的高级前端Tensorflow,可以描述一个简单的深度学习模型来对图像进行分类。所以可以PyTorch——下面的想法也同样适用于这里,尽管它们的执行略有不同。没有必要从头开始构建图像分类器。相反,这个例子重用了预训练的Xception模型内置到Keras,并在顶部添加一个密集层进行分类。(注意,这个例子使用了Tensorflow 2.5.0中包含的Keras。keras,而不是独立的keras)。预先训练的层本身不会被进一步训练。把这作为第0步:在处理图像时使用迁移学习和预训练模型!
步骤1:使用GPU
在CPU上训练深度学习模型几乎唯一有意义的情况是没有可用的gpu。当在云中工作时,在像Databricks这样的平台上,为一台机器bob体育客户端下载配备GPU并准备好所有的驱动程序和库是很简单的。虽然GPU看起来很昂贵,但速度的提升通常会使它们更具成本效益(而且对于GPU实例来说,Databricks的成本实际上是打折的)。本例将直接跳到在单个NVIDIA Tesla T4 GPU上训练该模型。
第一次传递将从Delta中加载10%的样本数据作为a熊猫DataFrame,重塑图像数据,并在90%的样本上进行记忆训练。在这里,训练只是在一个小批量上运行60个epoch。小提示:当使用预训练的网络时,将图像值归一化到网络期望的范围是至关重要的。这里是[-1,1],Keras提供了一个preprocess_input函数这样做。
(注意:要在Databricks上运行此示例,请选择支持GPU的8.4 ML Runtime或更高版本,并选择单个GPU的单节点集群类型和实例类型。)
(注意:要在Databricks上运行此示例,请选择支持GPU的8.4 ML Runtime或更高版本,并选择单个GPU的单节点集群类型和实例类型。)
Df_pd = spark.read。格式(“δ”) .load (“…”)采样(0.1种子=42) .toPandas ()X_raw = df_pd[“图像”) . valuesX = np.array([preprocess_input (np.frombuffer (X_raw[我],dtype = np.uint8) .reshape (img_size img_size,3.)))为我在范围(len(X_raw))))Y = df_pd[“标签”) . values-1# 1,因为标签是以1为基础的X_train, X_test, y_train, y_test =\train_test_split(X, y, test_size=0.1random_state =42)
...defbuild_model(辍学=没有一个):model = Sequential()xcexception = xcexception (include_top=假,input_shape = (img_size img_size,3.),池=“平均”)为层在xception.layers:层。可训练的=假model.add (xception)如果辍学:model.add(辍学(辍学))model.add(密度(257激活=“softmax”))返回模型
Model = build_model()模型。编译(优化器=纳丹(lr =0.001),损失=“sparse_categorical_crossentropy”指标= (“准确性”])模型。fit(X_train, y_train, batch_size=2时代=60verbose =2)模型。评估(X_test y_test)
...时代59/601211/1211- 20 -损失:6.2584 e-08准确性:1.0000时代60/601211/1211- 20 -损失:7.2973 e-08准确性:1.0000[1.3378633260726929,0.7851851582527161]结果看起来不错-大约20分钟后100%的准确性!然而,有一个重要的缺陷。对保留的10%验证数据的最终评估表明,真正的准确性更接近78.5%。实际上,模型存在过拟合。这并不好,但更糟的是,这意味着大部分训练时间都花在了让情况变得更糟上。当验证数据的准确性停止下降时,它就应该结束。这样不仅会留下一个更好的模型,而且会完成快.
步骤2:及早停止
Keras(以及其他框架,如PyTorch Lightning)有内置的支持,可以在进一步的训练似乎使模型变得更糟时停止。在Keras,它是EarlyStopping回调。使用它意味着将验证数据传递给训练过程,以便在每个阶段进行评估。训练将在几个阶段过去后没有改善后停止。restore_best_weights=True确保最终模型的权重来自其最佳纪元,而不仅仅是最后一个纪元。这应该是您的默认值。
...early_stopping=EarlyStopping(耐心=3.、监控=“val_accuracy”,restore_best_weights=真正的,详细=1)模型。fit(X_train, y_train, batch_size=2,时代=60,详细=2,validation_data=(X_test, y_test),回调=[early_stopping])模型。评估(X_test y_test)
...时代11/601211/1211-21年代-失:0.0023-准确性:0.9992-val_loss:1.0048-val_accuracy:0.7815恢复模型权重从的结束的最好的时代。时代00011:提前停止[1.0000447034835815,0.7851851582527161]现在,训练在11个周期内停止,而不是60个周期,而且只有4分钟。由于对验证数据的评估,每个epoch花费的时间略长(21秒vs 18秒)。准确率相似,为78.5%。
在提前停止的情况下,请注意传递给fit()的epoch数量仅作为将运行的最大epoch数量的限制。可以设置为较大的值。这是这里的第一个观察结果,表明了同样的事情:作为训练单位,epoch并不重要。它们只是一些批次的数据组成了整个训练的输入。但是训练意味着重复地批量传递数据,直到模型得到足够的训练。这代表了多少个时代并不直接重要。epoch仍然是一个有用的比较点,用于每个数据量的训练时间。
步骤#3:用更大的批量大小最大化GPU
在Databricks中,集群指标通过基于ganglia的UI公开。这显示了训练期间GPU的利用率。监视利用率对于调优很重要,因为它可以提示瓶颈。这里,GPU的使用率是85%:
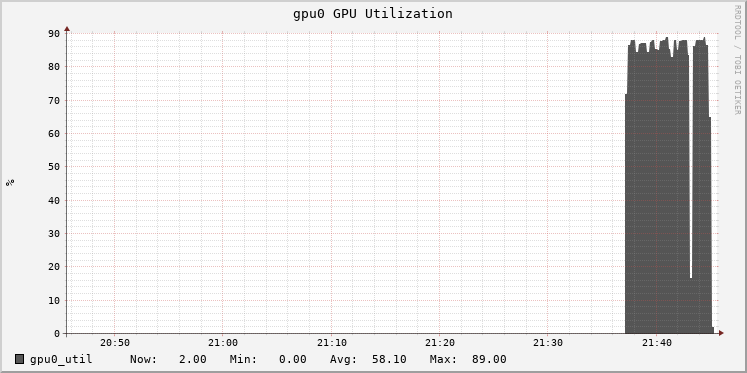
100%比85%冷。批处理大小为2很小,在处理过程中不会让GPU足够忙。增加批处理大小将提高利用率。我们的目标不仅仅是让GPU更繁忙,而是从额外的工作中受益。更大的批量通过更精确的梯度提高了每个批量更新模型的效果(直到一点)。这反过来可以允许训练使用更高的学习率,并更快地达到模型停止改进的点。
或者,有了额外的容量,就有可能增加网络架构本身的复杂性来利用这一点。本例不打算探讨调优架构,但将尝试添加一些dropout以减少网络过拟合的趋势。
Model = build_model(dropout=0.5)模型。编译(优化器=纳丹(lr =0.004),损失=“sparse_categorical_crossentropy”指标= (“准确性”])模型。fit(X_train, y_train, batch_size=16时代=30.verbose =2,validation_data=(X_test, y_test), callback =[early_stop])
...时代7/30.152/152- 18s -损失:0.0259准确性:0.9963- val_loss:0.9538- val_accuracy:0.7704时代8/30.152/152- 18s -损失:0.0224准确性:0.9946- val_loss:0.9844- val_accuracy:0.7667恢复模型权重从最好的时代结束了。纪元00008:提前停止[0.977917492389679,0.7814815044403076]批处理大小从2个增加到16个,学习率从0.001增加到0.004,GPU在18秒内完成epoch的处理,而不是21秒。该模型仅在8个epoch中就达到了相同的精度(78.1%)。火车的总时间只有2.6分钟,远远好于20分钟。
很容易将学习率提高太多,在这种情况下,训练的准确性就会很差,并且一直很差。当批处理大小增加8倍时,通常建议将学习率增加最多8 x。一些研究表明,当批处理大小增加N时,学习率可以缩放约根号(N)。
请注意,在训练过程中有一些固有的随机性,因为输入被Keras打乱了。准确性随着时间的推移波动很大,但有时会下降,加上早期停止,训练可能会根据遇到数据的顺序提前或推迟结束。为了平衡这一点,提前停止的“耐心”可以在最后以额外的训练为代价来增加。
步骤#4:使用petstorm访问大数据
上面的训练只使用了10%的数据样本,上面的技巧通过采用一些最佳实践来缩短训练时间。当然,下一步是在所有数据上进行训练。这应该有助于实现更高的准确性,但也意味着需要处理更多的数据。完整的数据集有许多gb,仍然可以装入内存,但为了这里的目的,让我们假设它不能装入内存。在训练过程中,需要用不同的方法将数据以块的形式有效地加载到内存中。
幸运的是,Petastorm该库旨在以这种方式将基于parquet的数据输入Tensorflow(或Keras或PyTorch)训练。它可以通过调整预处理和训练代码来创建Tensorflow数据集,而不是熊猫数据框架,用于训练。这里的数据集就像数据上的无限迭代器,这意味着现在定义了steps_per_epoch来指定多少批生成一个epoch。这强调了一个“时代”是多么的随意。
在引擎盖下,Petastorm的Spark集成接受一个Spark DataFrame的数据(图像,这里),并将它们序列化到Parquet文件,然后作为数据集流到训练过程。
spark.conf。集(SparkDatasetConverter。PARENT_CACHE_DIR_URL_CONF, \“文件:/ / / dbfs / tmp /……”)Converter_train = make_spark_converter(spark.read. converter)格式(“δ”) .load (“…”))Converter_test = make_spark_converter(spark.read. converter)格式(“δ”) .load (“…”))img_size =299deftransform_reader(数据集):deftransform_input(x):Img_bytes = tf.重塑(decode_raw(x。图像,tf.uint8), (-1img_size img_size,3.))输入= preprocess_input(tf。铸造(img_bytes tf.float32))Outputs = x.label -1返回(输入、输出)返回数据集。地图(transform_input)临时Parquet文件存储在DBFS (Databricks File System)上的路径中,DBFS仅仅是使分布式存储看起来像本地文件的一个缓冲,并且在某些情况下使访问更快。在/dbfs路径上缓存是个好主意;这也适用于检查点文件(本例中没有显示)。
上面的方法根据Tensorflow的转换api重新实现了早期代码中的一些预处理。
batch_size =16与converter_train.make_tf_dataset (batch_size = batch_size)作为train_dataset, \converter_test.make_tf_dataset (batch_size = batch_size)作为test_dataset:
Train_dataset = transform_reader(Train_dataset)Test_dataset = transform_reader(Test_dataset)Model = build_model(dropout=0.5)model.compile(优化器=纳丹(lr =0.004),损失=“sparse_categorical_crossentropy”指标= (“准确性”])early_stop = earlystop(耐心=3.、监控=“val_accuracy”,restore_best_weights = True,冗长的=1)模型。适合(train_dataset时代=30.steps_per_epoch = (train_size/ / batch_size),validation_data = test_dataset validation_steps = (test_size/ / batch_size),verbose =2回调函数= [early_stopping])现在运行:
1722/1722 - 208s -损失:0.3708 -精度:0.9172 - val_loss: 1.2649 - val_accuracy: 0.8362时代10/301722/1722 - 212秒-损失:0.3294 -精度:0.9268 - val_loss: 1.3533 - val_accuracy: 0.8316时代11/301722/1722 - 210秒-损失:0.3394 -精度:0.9268 - val_loss: 1.3192 - val_accuracy: 0.8359时代12/301722/1722 - 207s -损失:0.3175 -精度:0.9317 - val_loss: 1.5006 - val_accuracy: 0.8359Epoch时间增加了11倍以上(208秒vs 18秒),但请记住,这里的Epoch现在是对训练数据的完整传递,而不是10%的样本。额外的开销来自从云存储读取数据时的I/O。GPU利用率图显示了GPU的“尖峰”利用率:
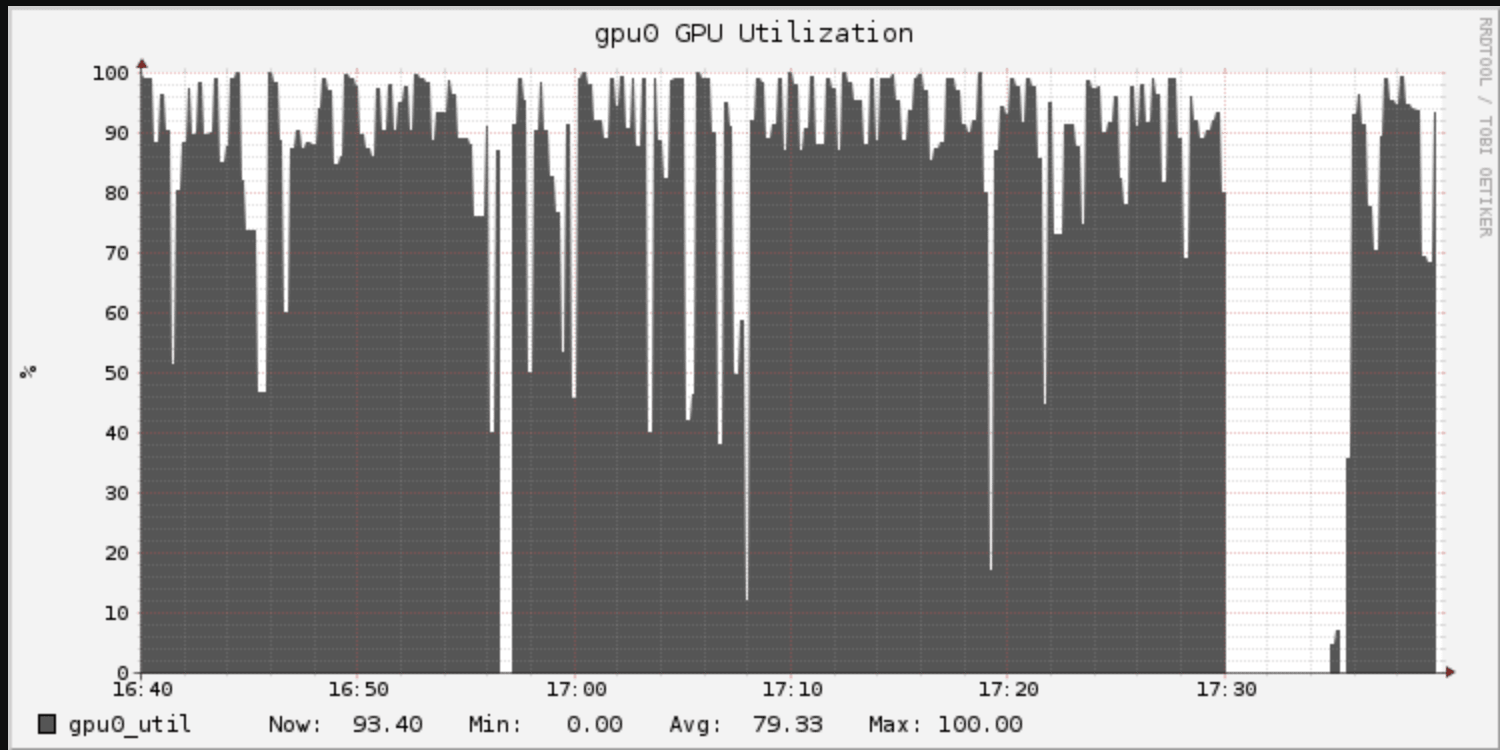
上行吗?准确率显著提高至83.6%。代价是训练时间变长了:从4分钟变成了42分钟。对于许多应用程序来说,为了提高7%的精度,这是非常值得的。
步骤5:使用多个gpu
还想要走得更快,有一些预算吗?在某种程度上,扩展意味着多个gpu。例如,云中有四个T4 gpu的实例。Tensorflow提供了一个名为mirrredstrategy的简单实用程序,可以在多个gpu上并行训练。(PyTorch中的类比是DataParallel)。这只是两行代码的更改:
策略=镜像策略()...与strategy.scope ():Model = build_model(dropout=0.5)...(注意:要运行此示例,请选择具有4个gpu的实例类型的单节点集群。)
修改很简单,但是不重复训练输出就直奔主题:精度是相似的,每个epoch的时间变成了68秒而不是208秒。不是快4倍,甚至不是3倍。4个gpu中的每一个只处理每批16个输入的1/4,所以每个gpu每批有效地只处理4个。如上所述,可以将批处理大小增加4倍以补偿到64,并进一步将学习率提高到0.008。(完整的代码清单见随附的笔记本。)
它揭示了训练的速度更快,每个纪元为61秒。加速更好了,但仍然没有达到4倍。准确率稳定在84.4%左右(稍好),所以这仍然朝着更快的训练方向发展。Tensorflow的实现很简单,但不是最优的。GPU利用率仍然很高,因为GPU在以直接但缓慢的方式组合部分梯度时处于空闲状态。
Horovod是Uber的另一个项目,它帮助扩展深度学习训练,不仅仅是在一台机器上的多个gpu上,而是在多台机器上的gpu上,并且具有很高的效率。虽然它通常与跨多台机器的训练有关,但这实际上并不是扩大规模的下一步。它可以帮助当前的多gpu设置。在其他条件相同的情况下,利用连接到同一虚拟机的4个gpu比分散在网络上更有效。
它需要对代码进行不同的修改,该代码使用HorovodRunner实用程序从Databricks集成Horovod与Spark:
batch_size=16num_gpus=4
def train_hvd ():进口tensorflow作为特遣部队hvd.init ()gpu=tf.config.experimental.list_physical_devices (“图形”)为gpu在gpu:tf.config.experimental.set_memory_growth (gpu,真正的)如果gpu:tf.config.experimental.set_visible_devices (gpu [hvd.local_rank ()),“图形”)与converter_train.make_tf_dataset (batch_size=batch_size, cur_shard=hvd。排名(), shard_count=hvd.size ())作为train_dataset, \converter_test.make_tf_dataset (batch_size=batch_size, cur_shard=hvd。排名(), shard_count=hvd.size ())作为test_dataset:train_dataset=transform_reader (train_dataset)test_dataset=transform_reader (test_dataset)模型=build_model(辍学=0.5)优化器=hvd。DistributedOptimizer(纳丹(lr=0.008))model.compile(优化器=优化器,\损失=“sparse_categorical_crossentropy”、指标=[“准确性”])回调=[hvd.callbacks.BroadcastGlobalVariablesCallback (0),hvd.callbacks.MetricAverageCallback (),EarlyStopping(耐心=3.、监控=“val_accuracy”, restore_best_weights=真正的,详细=(1如果hvd。排名()==0其他的0))]
模型。fit (train_dataset时代=30.,steps_per_epoch=(train_size//(batch_size*num_gpus)),validation_data=test_dataset,validation_steps=(test_size//(batch_size*num_gpus)),详细的=(2如果hvd。排名()==0其他的0),回调=回调函数)人力资源=HorovodRunner (np=-num_gpus)hr.run (train_hvd)再提几点注意事项:
- 注意,make_tf_dataset需要cur_shard和shard_count参数来理解加载哪个数据子集(例如,当前进程是4个中的2个)
- 使用hvd.callbacks.MetricAverageCallback正确平均验证指标
- 当本地时,将HorovodRunner的np=参数设置为负的gpu数量
- 批处理大小现在是每个GPU,而不是整体。注意在steps_per_epoch中的不同计算
训练的输出是嘈杂的,所以这里就不完整地复制了。大纪元时间从208秒下降到52秒,这令人满意地接近最大可能的4倍加速!准确率仍在84.4%左右。总运行时间现在只有7.3分钟,而不是42分钟。
步骤#6:跨多台机器使用Horovod
有时,8个甚至16个gpu是不够的,而这是今天你在一台机器上最多能得到的。或者,有时在许多小型机器上配置gpu会更便宜,以利用云计算中每种机器类型的不同价格。
上面相同的Horovod示例可以在八台1-GPU机器的集群上运行,而不是在一台4-GPU机器上运行,只需要做一行更改。事实证明,在撰写本文时,在一个云中,这8个gpu每小时的成本只比一台4-GPU机器高6%。尽管跨机器分布会带来更多的开销,但额外的吞吐量可能会使这种选择更便宜、更快。
HorovodRunner通过Spark 's来管理Horovod在Spark集群上的分布式工作障模式支持。
num_gpu = 8...hr = HorovodRunner(np=num_gpu)(注意:为了运行这个例子,提供一个有8个worker的集群,每个worker有1个GPU。)
唯一必要的更改是指定8,而不是-8,以在集群上而不是在驱动程序上选择8个gpu。然而,对于8个gpu,有效批处理大小增加了一倍,因此在上面的代码片段中将学习率提高到0.012可能会很有用。
8台机器的GPU利用率都很好。怠速者为驾驶员,不参加培训:
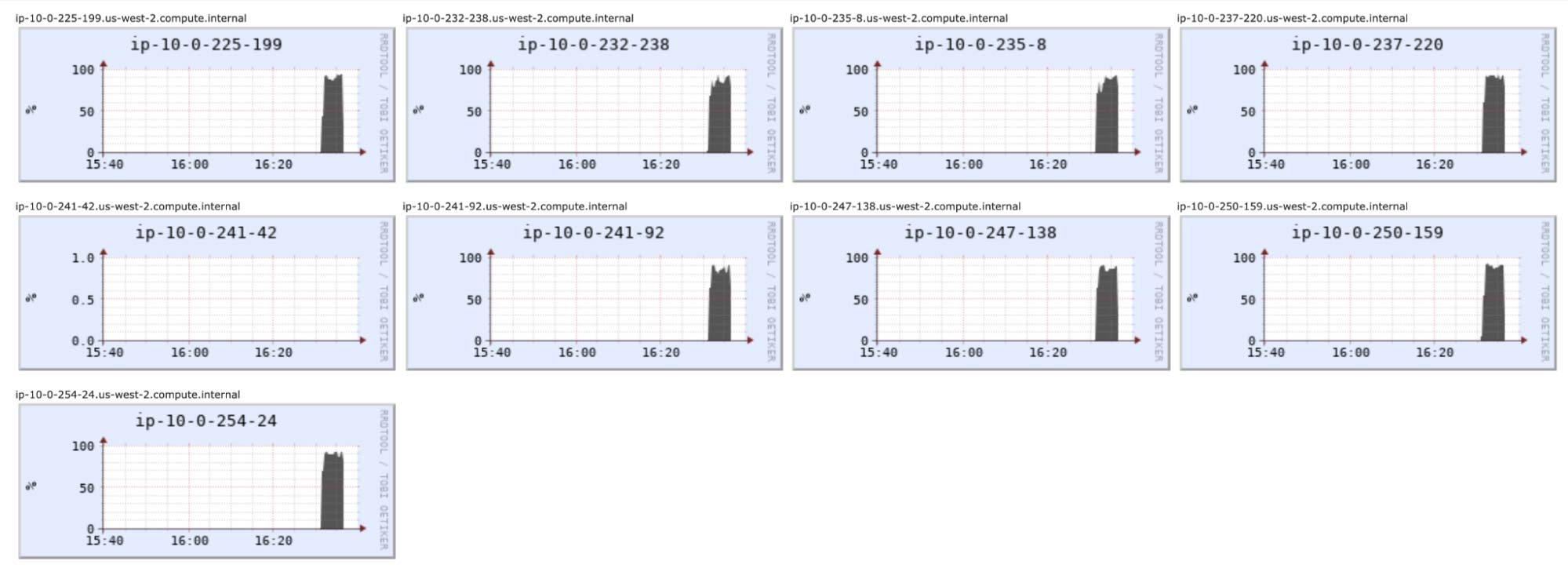
准确率提高了一些,达到了85.6%。总运行时间约为5.7分钟,而不是7.3分钟,这远没有达到2倍的速度。这在一定程度上反映了跨机器协调gpu的开销。
对于这种中等规模的问题,可能不可能有效地利用更多的GPU资源。让它们忙起来意味着更高的学习率,而学习率可能已经达到了它能达到的最高水平。对于这个网络,一些T4 gpu可能是最合适的资源部署量。当然,还有更大的网络和数据集!
结论
深度学习是强大的魔法,但我们总是希望它更快。但它的规模有不同的方式。在开始训练模型时,需要了解新的最佳实践和陷阱。其中一些帮助小图像分类问题实现了相同的78.5%的精度,同时将运行时间减少了7倍以上。扩展的第一步不是更多的资源,而是寻找简单的优化:
- 尽可能使用预先训练好的基础层
- 几乎总是使用GPU
- 及早停止
- 最大限度地利用更大的批处理大小和学习速率
在云中的整个大型数据集上进行扩展训练需要一些新的工具,但一开始不一定需要更多的gpu。通过仔细使用petstorm, 10倍的数据帮助在相同硬件上在大约10倍的时间内实现83.6%的精度。
- 使用petstorm在训练期间有效地处理大型数据集
扩大规模的下一步意味着使用像Horovod这样的工具来利用多个gpu,但并不一定意味着机器集群,不像ETL作业,机器集群是常态。单个4个GPU实例允许训练速度加快4倍,准确率达到84.4%。只有对于最大的问题才需要多个GPU实例,但是Horovod可以帮助在没有太多开销的情况下进一步扩展,进一步提高精度。
- 使用Horovod扩展到一台机器上的多个gpu
- 使用Horovod扩展更多的gpu分布在机器集群中
训练快乐!