
并行基因组变异分析


这篇文章从黛博拉·西格尔从西北与丹尼基因组中心和华盛顿大学的李从砖在他们合作的基因组变异分析亚当和火花。
1。基因组测序的概括
2。并行基因组变异分析
3所示。预测地理人口使用基因组变异和k - means
介绍
在过去的几年里,我们看到了一个基因组测序的快速减少成本和时间。潜在的理解基因组序列的变化范围从帮助我们识别人倾向于常见疾病,解决罕见疾病,使临床医生能够个性化个人处方和剂量。
在这个分三部分的博客,我们将提供一个基因组测序引物及其潜力。我们将关注基因组变异分析,基因组序列之间的差异,以及如何加速利用Apache火花和亚当(基因组处理一个可扩展的API和CLI)使用砖Community Edition。最后,我们将执行一个k - means聚类算法对基因组变异数据,建立一个模型,将预测个人的地理原产地种群基于这些变体。
这篇文章将集中在并行基因组序列分析;基因组测序的复习,你可以检查基因组测序的概括。你也可以跳到第三个帖子预测地理人口使用基因组变异和k - means。
并行基因组变异分析
正如基因组测序的概括,有很多步骤和阶段的分析,可以分布式和并行的希望可能显著提高性能和改善结果非常大的数据Apache火花是适合序列数据,因为它不仅执行许多任务在分布式并行的方式,但是这样做主要内存与降低中间文件的必要性。
亚当的基准+火花(排序基因组读取和删除标记重复读取)显示可伸缩的加速效果,从1.5天在单个节点上对商品集群(不到一个小时亚当:基因组学云规模计算格式和处理模式)。
工作时提到的一个主要问题与当前基因组序列数据格式是不容易可平行的。从根本上说,当前的工具集和基因组数据格式(例如山姆,BAM VCF,等等)不精心设计的分布式计算环境。提供上下文,下一小节将提供一个简化的背景工作流从基因组序列变异的工作流。
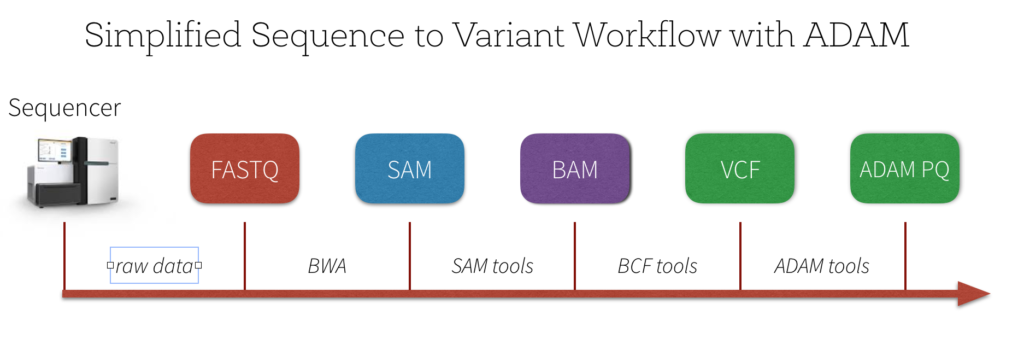
简化基因组序列变异的工作流
有很多质量控制和之前必须首先执行预处理步骤分析变异。一个简化的工作流程中可以看到下面的图片。
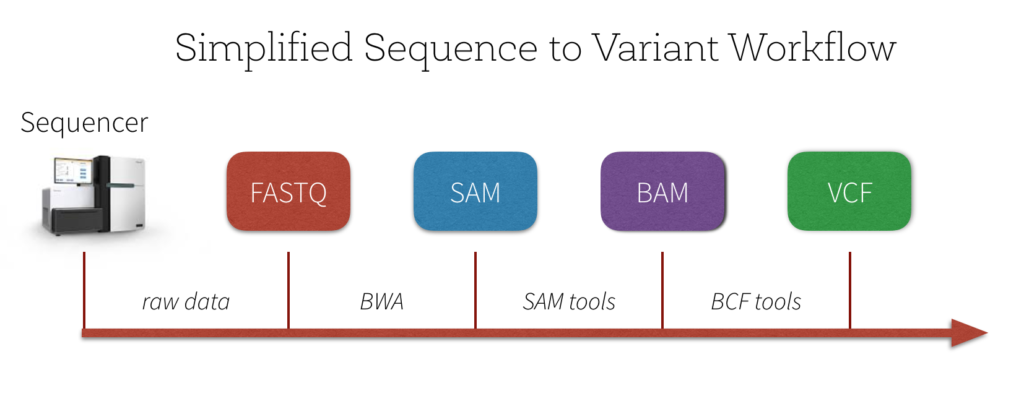
基因组测序仪的输出机FASTQ格式——基于文本的格式存储短核苷酸序列读取和它们相关的ASCII格式的质量分数。下图是一个例子的FASTQ格式的数据。

一个典型的下一个步骤是使用BWA (burrows - wheeler对齐)序列比对工具等领结使大套短DNA序列(读取)参考基因组和创建一个山姆文件——一个序列比对映射文件存储映射标记一个基因组。下图(从序列比对/地图格式规范)是山姆格式的一个例子。这个规范的术语和概念的数量超出了这篇文章的范围;有关更多信息,请参考序列比对/地图格式规范。
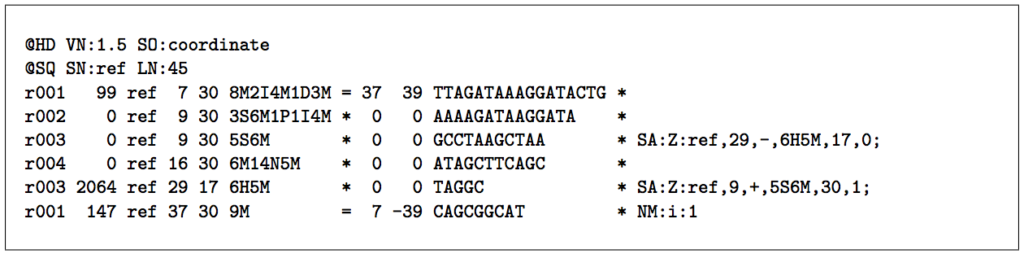
来源:序列比对/地图格式规范
下一步是把山姆到BAM (SAM)的二进制版本通常通过使用SAMtools(一个好的参考这个过程是戴夫唐的学习BAM文件)。最后,调用一个变体格式(VCF)文件是由比较BAM文件参考序列(通常这是使用BCFtools)。注意,一个伟大的短描述这个过程是Kaushik Ghose用博客山姆!砰!VCF !什么?。
简化的概述VCF
VCF文件之后,我们终于可以开始执行变异分析。VCF本身是一个复杂的规范对于一个更详细的解释,请参考1000人基因工程VCF(变体调用格式)版本4.0规范。
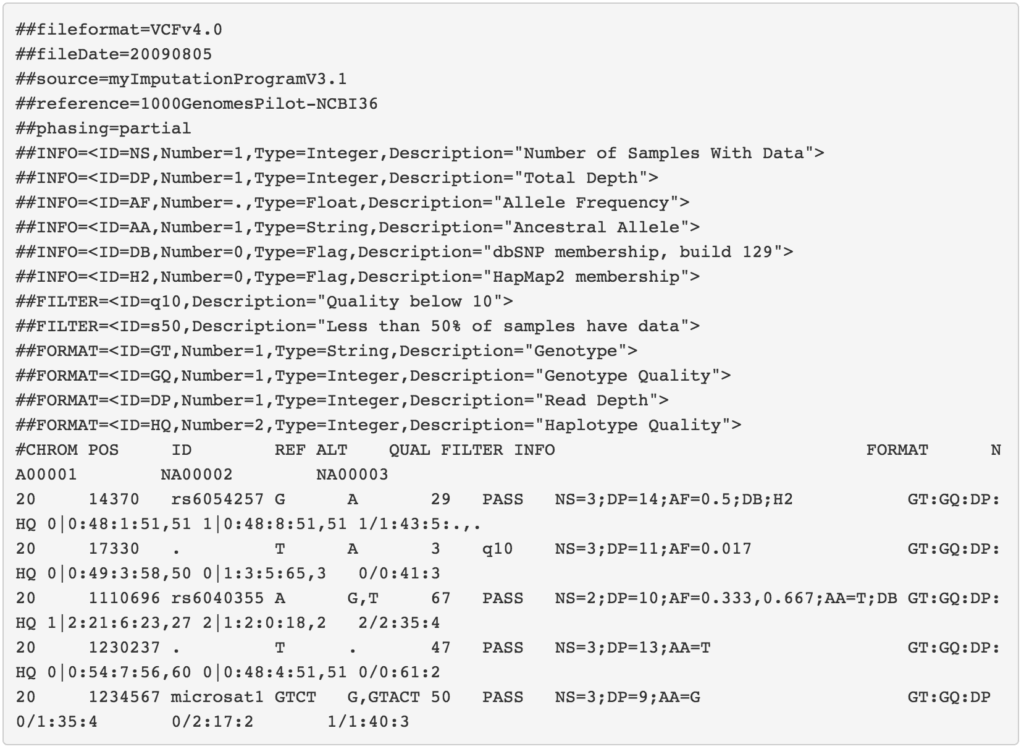
来源:1000人基因工程VCF(变体调用格式)版本4.0规范
虽然有各种工具可以处理和分析vcf,它们不能用于分布式并行的方式。VCF的简化视图文件,它包含元数据,标题,和数据。元数据通常是感兴趣的,应适用于每一基因型。见下图,即使你有四个节点(例如节点1,节点2,节点3,节点4)来处理你的基因型数据,不能有效地分发到所有四个节点的数据。与传统变异分析工具,整个文件包括所有的数据、元数据和标题必须被发送到一个节点。此外,VCF文件有多个观察每一行(变异和他们所有的基因型)。这使得它不可能并行分析基因型没有重新格式化或使用特殊的工具。
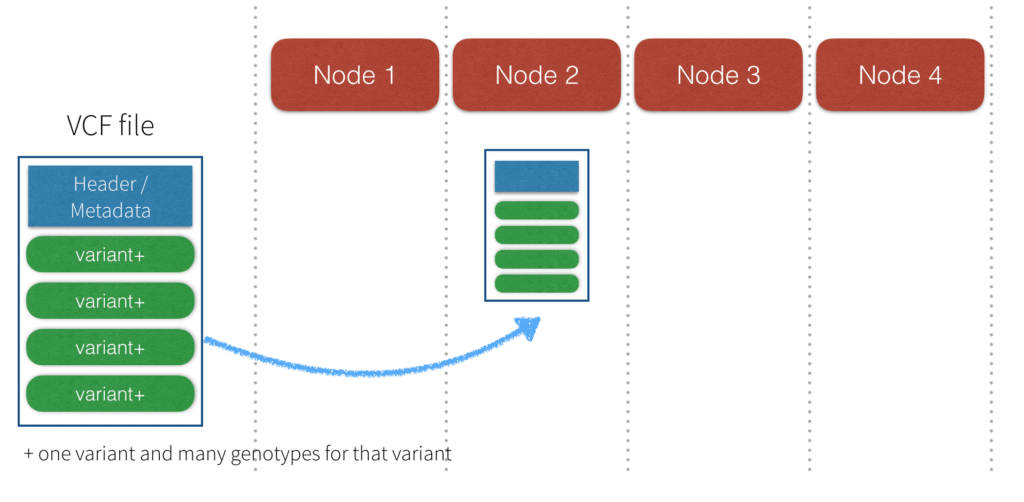
复杂的VCF分析另一个关键问题是围绕VCF格式规范的程度的复杂性。他指的是1000人基因工程VCF(变体调用格式)版本4.0规范周围,有许多的规则如何解释VCF内的线路。因此,任何数据科学家谁想分析变异数据必须花费大量的努力了解他们正在与特定的vcf和解析。
介绍亚当
大数据基因组学亚当项目旨在解决问题在分发序列数据和并行序列数据的处理在技术报告中指出亚当:基因组学云规模计算格式和处理模式。亚当由CLI(基因组学工具进行快速处理数据),许多api(接口转换、分析和查询基因组数据),模式和文件格式(柱状格式,允许有效的并行访问的数据)。
bdg-formats模式
解决解析常见类型的序列数据的复杂性,如读、面向参考数据,变异,基因型,和组件——亚当•利用一组可扩展的Apache Avro模式建立在数据类型本身,而不是一个文件格式。换句话说,模式允许亚当(或其他任何工具)更容易查询数据而不是构建自定义代码来解析每一行的数据根据文件格式。这些数据格式是高效的,他们很容易可序列化的,每个特定模式的信息,比如数据类型,不需要发送多余地与每一批的数据。集群中的节点都知道什么是模式以可扩展的方式(数据可以添加一个扩展模式,并分析了与数据在旧模式下)。
并行分布通过亚当拼花
亚当铺文件(二进制或文本相比,VCF文件)启用快速处理,因为他们支持并行序列数据的分布。在前面的VCF文件,我们看到整个文件必须被发送到一个节点。与亚当铺文件、元数据和头纳入数据元素和模式,元素是“整洁”,有一个观察每个元素(一个基因型的一个变体)。

这使文件分布在多个节点。这也使简单过滤元素就是你想要的数据,如基因型在一定面板,不使用特殊工具。亚当文件存储在拼花柱状存储格式设计的并行处理。GATK4,基因组分析工具箱也能够读和写亚当铺格式化的数据。
更新简化基因组序列变异工作流
与定义模式(bdg-format)和亚当的api,数据科学家可以专注于查询数据,而不是解析数据格式。
下一个步骤
在接下来的博客我们将运行一个平行的生物信息学分析的例子预测地理人口使用基因组变异和k - means。你也可以检查在基因组测序引物:基因组测序的概括。
归因
我们想要给一个特定的电话下面的资源帮助我们创建了笔记本
- 亚当:基因组学云规模计算格式和处理模式(伯克利AMPLab)
- 安迪•彼得雷拉闪电快基因组学与火花和亚当和相关的GitHub回购。
- 尼尔•弗格森用深度学习人口分层分析基因组数据。
- 马修ConlenLightning-Viz项目。
- 盖Danford SlideShare演示(基因组学与火花)
- 孟德尔基因组学中心发现数以百计的罕见的基因基础条件
- 国家卫生研究院基因组测序计划目标共同的基因基础,罕见的疾病
- 1000人基因组计划
,我们想感谢额外贡献和评论由安东尼·约瑟夫Xiangrui孟,Hossein Falaki,蒂姆·亨特。