



本机支持会话窗口的火花结构化流
Apache火花™结构化流允许用户做聚合在windows事件时间。在Apache 3.2火花™,火花支持暴跌windows和滑动赢得…
,当我们进入2022年,我们想花点时间反思的很大进步流媒体在砖和Apache的火花™!2021年,工程团队和开源贡献者大量进步了三个目标:bob下载地址
最终,这些目标背后的动机是为了让更多的团队运行流负载在砖和火花,方便客户操作关键任务同时生产流媒体应用程序数据砖和优化成本效率和资源使用。
有两个新的关键特性,专门针对降低延迟和有状态操作,以及改善状态api。第一个大型状态是异步的检查点操作,使在历史上同步设计和更高的延迟。
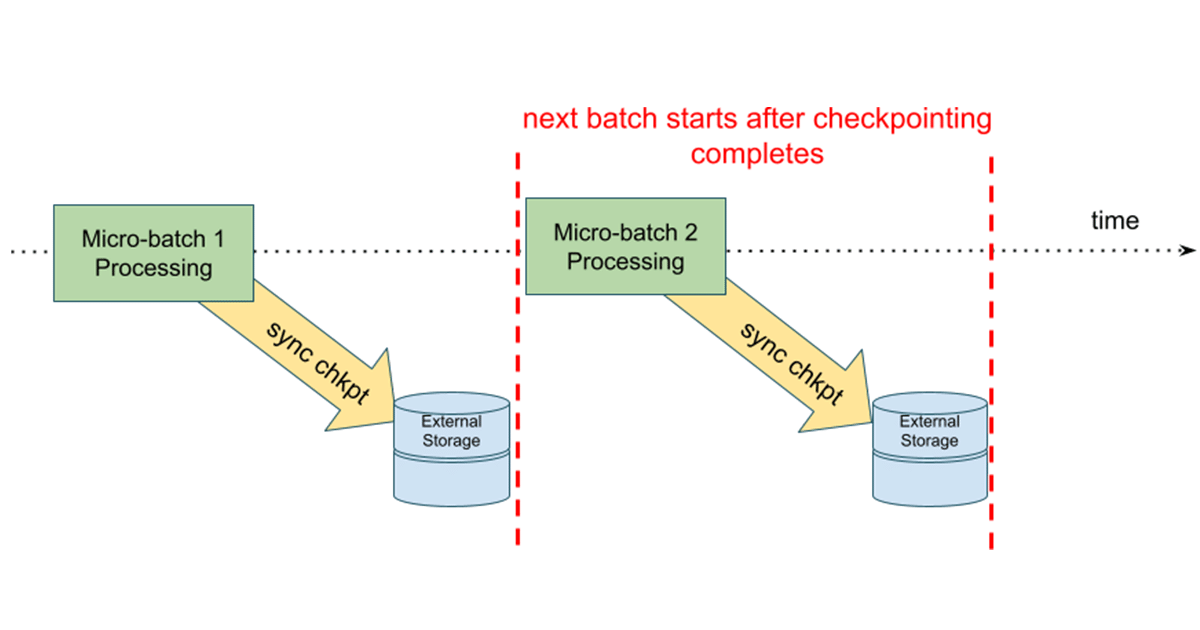
在这个模型中,状态更新写入到云存储检查点位置下microbatch开始之前。的优势是,如果一个有状态的流媒体查询失败,我们可以很容易的重新启动查询通过使用信息从最后一批成功完成。在异步模型,下一个microbatch不必等待状态更新,改善整体的端到端延时microbatch执行。
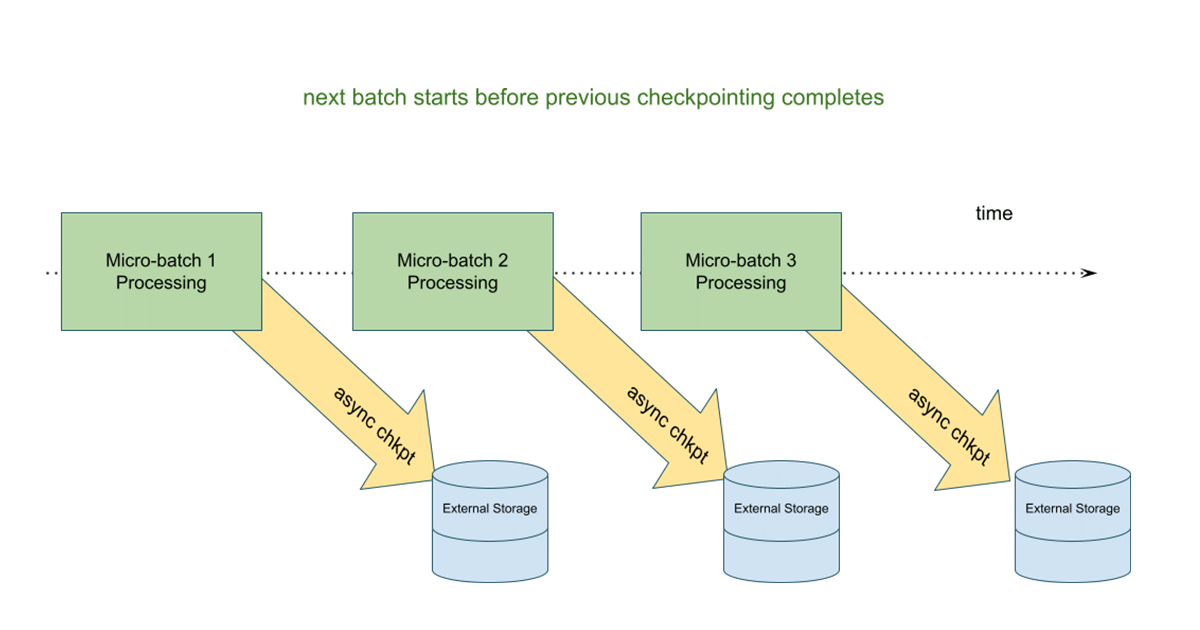
您可以了解更多关BOB低频彩于该特性在即将到来的深潜博客,并尝试在砖运行时10.3及以上。
在更之前的帖子结构中,我们介绍了任意状态处理流媒体(平面)MapGroupsWithState。这些运营商提供了很大的灵活性,使聚合之外更高级的有状态操作。我们已经介绍了改进这些操作符:
让我们先从以下flatMapGroupswithState算子:
def flatMapGroupsWithState [S:编码器,U:编码器)(outputMode: outputMode,timeoutConf:GroupStateTimeout,initialState:KeyValueGroupedDataset [K S]) (函数:(K,迭代器[V], GroupState [S])= >迭代器(U))这个自定义状态函数保持运行计数的水果。
val fruitCountFunc =(关键:字符串价值观:迭代器(字符串),状态:GroupState [RunningCount])= >{val数= state.getOption.map (_.count) .getOrElse l (0) + valList.sizestate.update (新RunningCount(计数)迭代器(关键,count.toString))}在这个示例中,我们指定该操作符的初始状态为某些水果:通过设置起始值
val fruitCountInitialDS:数据集(字符串RunningCount)] = > ((“苹果”,新RunningCount (1)),(“橙色”,新RunningCount (2)),(“芒果”,新RunningCount (5)),).toDS ()val fruitCountInitial = initialState.groupByKey (x= >x._1) .mapValues (_._2)
fruitStream.groupByKey (x= >x).flatMapGroupsWithState(更新GroupStateTimeout。NoTimeout fruitCountInitial) (fruitCountFunc)你也可以现在测试状态更新使用TestGroupState API。
进口org.apache.spark.sql.streaming._进口org.apache.spark.api.java.Optional测试(“flatMapGroupsWithState状态更新函数”){varprevState = TestGroupState.create [UserStatus] (optionalState = Optional.empty [UserStatus],timeoutConf = GroupStateTimeout.EventTimeTimeout,batchProcessingTimeMs = 1 l,eventTimeWatermarkMs = Optional.of(1升),hasTimedOut =假)val标识:字符串=……val行动:迭代器(UserAction) =…
断言(prevState.hasUpdated !)
updateState(标识、行动、prevState)
断言(prevState.hasUpdated)
}你可以找到这些,更多的例子砖的文档。
结构化流媒体介绍了能力基于聚合在事件时间窗口使用滚动或滑动窗口,这两个是固定长度的窗户。在火花3.2中,我们介绍的概念会话窗口,允许动态窗口长度。这历史上需要自定义状态使用flatMapGroupsWithState运营商。
使用动态间隙的一个例子:
#定义会话窗口有动态基于差距持续时间在eventTypesession_window expr=session_window(事件。时间戳,\当(events.eventType==类型1、5秒”)\。当(events.eventType==“type2”、“20秒”)\.otherwise(5分钟)#集团的数据通过会话窗口和用户标识,和计算出数量的每一个集团windowedCountsDF=事件\.withWatermark(“时间戳”,“十分钟”)\.groupBy(事件。userID, session_window_expr) \。数()而StreamingQueryListener异步API允许您监控中查询SparkSession和自定义回调函数查询状态,进展,和终止事件,理解背压和推理的瓶颈在microbatch仍具有挑战性。砖8.1运行时,StreamingQueryProgress对象数据源特定的背压指标报告卡夫卡,运动,三角洲湖和自动加载程序流源。
度量提供了卡夫卡的一个例子:
{“源”:[{“描述”:“KafkaV2订阅(主题)”,“指标”:{“avgOffsetsBehindLatest”:“4.0”,“maxOffsetsBehindLatest”:“4”,“minOffsetsBehindLatest”:“4”,“estimatedTotalBytesBehindLatest”:“80.0”},})}砖运行时8.3引入了实时度量来帮助理解的表现RocksDB状态存储和调试状态操作的性能。这些也可以帮助识别目标的工作负载为异步检查点。
一个新的状态存储度量的例子:
{“id”:“6774075 e - 8869 - 454 b - ad51 - 513 be86cfd43”,“runId”:“3 d08104d-d1d4-4d1a-b21e-0b2e1fb871c5”,“batchId”:7,“stateOperators”:[{“numRowsTotal”:20000000,“numRowsUpdated”:20000000,“memoryUsedBytes”:31005397,“numRowsDroppedByWatermark”:0,“customMetrics”:{“rocksdbBytesCopied”:141037747,“rocksdbCommitCheckpointLatency”:2,“rocksdbCommitCompactLatency”:22061年,“rocksdbCommitFileSyncLatencyMs”:1710年,“rocksdbCommitFlushLatency”:19032年,“rocksdbCommitPauseLatency”:0,“rocksdbCommitWriteBatchLatency”:56155年,“rocksdbFilesCopied”:2,“rocksdbFilesReused”:0,“rocksdbGetCount”:40000000,“rocksdbGetLatency”:21834年,“rocksdbPutCount”:1,“rocksdbPutLatency”:56155599000,“rocksdbReadBlockCacheHitCount”:1988年,“rocksdbReadBlockCacheMissCount”:40341617,“rocksdbSstFileSize”:141037747,“rocksdbTotalBytesReadByCompaction”:336853375,“rocksdbTotalBytesReadByGet”:680000000,“rocksdbTotalBytesReadThroughIterator”:0,“rocksdbTotalBytesWrittenByCompaction”:141037747,“rocksdbTotalBytesWrittenByPut”:740000012,“rocksdbTotalCompactionLatencyMs”:21949695000,“rocksdbWriterStallLatencyMs”:0,“rocksdbZipFileBytesUncompressed”:7038年}}),“源”:[{}),“沉”:{}}去年数据+人工智能峰会上,我们宣布三角洲生活表以声明的方式,这是一个框架,该框架允许您构建和协调数据管道,和主要摘要需要配置集群和节点类型。我们把这进一步引入一个智能自动定量流管道,改进了现有的解决方案砖优化的自动定量。这些好处包括:
新算法利用新背压指标调整集群大小来更好地处理场景中有流工作负载的波动,最终导致更好地使用集群。
虽然现有的自动定量解决退休节点只有在空闲,新的DLT Autoscaler将主动关闭时选定的节点利用率低,同时保证不会有失败的任务由于关闭。
目前正在编写,此功能私人预览。有关更多信息,请伸出您的帐户的团队。
在结构化流、触发器允许一个用户定义的时间流查询的数据处理。这些触发类型可以micro-batch(默认),固定间隔micro-batch (Trigger.ProcessingTime (“
砖10.1运行时介绍了一种新型的触发;Trigger.AvailableNowthat is similar to Trigger.Once but provides better scalability. Like Trigger Once, all available data will be processed before the query is stopped, but in multiple batches instead of one. This is supported for Delta Lake and Auto Loader streaming sources.
例子:
spark.readStream.format(“δ”).option (“maxFilesPerTrigger”,“1”).load (inputDir)之类.writeStream。触发(Trigger.AvailableNow)checkpointDir .option (“checkpointLocation”)。开始()在2022年即将来临之际,我们将继续加快创新结构化流,进一步提高性能,减少延迟和实现新的和令人兴奋的功能。全年的更多信息,请继续关注!

