


这是关于如何执行复杂任务的系列文章的第七篇流分析使用Apache Spark和结构化流。
简介
大多数数据流虽然在流中是连续的,但在流中有离散的事件,每个事件在发生时都用时间戳标记。因此,“事件时间”的概念是如何解决问题的核心结构化流api是为事件时处理以及它们提供的处理这些离散事件的功能而设计的。
事件时间基础和事件时间处理都被充分覆盖结构化流文档和我们的结构流技术资产选集.为了简洁起见,这里就不讲了。基于事件时处理中开发(并大规模测试)的概念,例如滑动窗口、滚动窗口和水印,本博客将集中讨论两个主题:
- 如何处理事件流中的重复
- 如何处理任意或自定义状态处理
删除重复的
所有流事件都没有重复条目。在一次记录系统中删除重复的条目是必要的——由于几个原因,这通常是一项繁琐的操作。首先,您必须同时处理小批量或大批量的记录以丢弃它们。其次,由于网络的高延迟,一些事件可能会出现紊乱或延迟,这可能会迫使您重复或重复该过程。你怎么解释?
结构化流确保了精确的一次语义,可以丢弃基于任意键进入的重复消息。为了重复数据删除,Spark将维护一些用户指定的密钥,并确保在遇到重复数据时丢弃。
就像结构化流中的其他有状态处理api一样,也受声明的限制用于后期数据的水印语义上,删除重复的内容也是如此。如果没有水印,所维护的状态可以在流的过程中无限增长。
指示结构化流删除副本的API与我们迄今为止在博客和文档中展示的所有其他API一样简单。使用API,您可以任意声明要删除重复项的列—例如,user_id和时间戳。具有相同时间戳和user_id的条目被标记为重复并删除,但是具有两个不同时间戳的相同条目不会被删除。
让我们看一个如何使用简单API删除重复项的示例。
import org.apache.spark.sql.functions.expr withEventTime .withWatermark("event_time", "5 seconds") . dropduplduplicate ("User", "event_time") .groupBy("User") .count() .writeStream .queryName(" deduplication ") .format("memory") .outputMode("complete") .start()from pyspark.sql.functions import expr withEventTime\ .withWatermark("event_time", "5秒")\ . dropduplduplicate (["User", "event_time"])\ .groupBy("User")\ .count()\ .writeStream\ .queryName(" pydeduplication ")\ .format("memory")\ .outputMode("complete")\ .start()在查询过程中,如果您要发出一个SQL查询,您将得到一个准确的结果,删除所有重复项。
SELECT * FROM删除处理 +----+-----+ | 用户|计数 | +----+-----+ | 8085 | | | | 9123 | | c | 7715 | | g | 9167 | | | 7733 | | e | 9891 | | f | 9206 | | d | 8124 | |我| 9255 | +----+-----+接下来,我们将详细介绍如何使用两个结构化流api实现自定义的有状态处理。
使用任意或自定义状态处理
并非所有基于事件时间的处理都是相同的,或者像在事件中聚合特定数据列那样简单。其他事件则更为复杂;它们需要按归属于一个组的事件行进行处理;它们只有在通过发出单个结果或多行结果进行整体处理时才有意义,这取决于您的用例。
考虑这些用例,其中任意或定制的有状态处理变得必不可少:
1.如果我们观察到事件随着时间的推移超过了阈值,我们希望根据一组或类型的事件发出警报
2.我们希望在确定或不确定的时间内维护用户会话,并持久化这些会话以供后期分析。
以上所有场景都需要定制处理。结构化流api提供了一组api来处理这些情况:mapGroupsWithState而且flatMapGroupsWithState。mapGroupsWithStatE可以对组进行操作,并且每个组只输出一个结果行,而flatMapGroupsWithState每个组可以发出单行或多行结果。
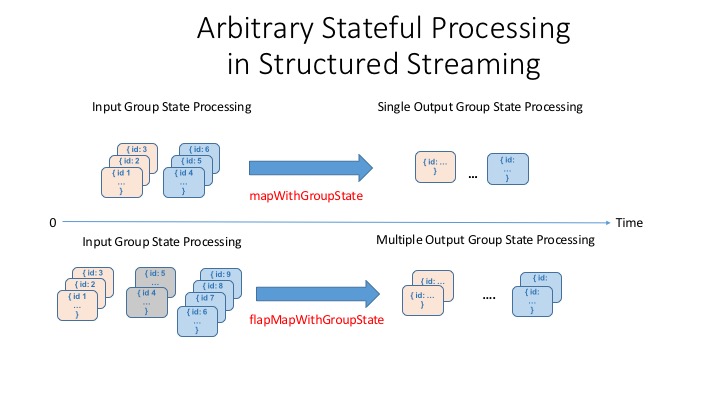
超时和状态
需要注意的一点是,因为我们根据用户定义的概念管理组的状态,正如上面用例所表达的那样,水印的语义(过期或丢弃事件)可能并不总是适用于这里。相反,我们必须自己指定一个适当的超时。Timeout指示我们在超时某个中间状态之前应该等待多长时间。
超时可以基于处理时间(GroupStateTimeout.ProcessingTimeTimeout)或事件时间(GroupStateTimeout.EventTimeTimeout)。在使用超时时,您可以在处理值之前通过检查标志来检查超时state.hasTimedOut。
若要设置处理超时时间,使用GroupState.setTimeoutDuration(…)方法。这意味着超时保证将在以下条件下发生:
- 在时钟前进之前,超时永远不会发生X女士在方法中指定
- 之后,当查询中有触发器时,将最终发生超时X女士
若要设置事件超时时间,请使用GroupState.setTimeoutTimestamp(…).仅对于基于事件时间的超时,必须指定水印。这样,比水印时间更早的组中的所有事件将被过滤掉,当水印时间超过设置的时间戳时,将发生超时。
当超时发生时,流查询中提供的函数将被参数调用:用于保持状态的键;输入的迭代器行和旧状态。举个例子mapGroupsWithState下面定义了一些使用的函数类和对象。
mapGroupsWithState的示例
让我们举一个简单的例子,我们想要找出用户在流中的给定数据集中执行他或她的第一个和最后一个活动的时间戳。在本例中,我们将在用户键和活动键组合上进行分组(或映射)。
但首先,mapGroupsWithState需要一些函数类和对象:
1.三个类定义:输入定义、状态定义和可选的输出定义。
2.一个基于键、事件迭代器和先前状态的更新函数。
3.如上所述的超时参数。
因此,让我们定义输入、输出和状态数据结构定义。
case类InputRow(用户:字符串,时间戳:java.sql. xml)时间戳,活动:字符串)案例类UserState(用户:字符串,var活动:字符串,var start:java.sql。时间戳,var结束:java.sql.Timestamp)基于给定的输入行,我们定义更新函数
def updateUserStateWithEvent(state:UserState, input:InputRow):UserState ={//没有时间戳,只是忽略它if (Option(input.timestamp). isempty) {return state} //如果(state. timestamp)输入行的活动匹配。Activity == input.activity) {if (input.timestamp.after(state.end)){状态。End = input。时间戳}if (input.timestamp.before(state.start)){状态。Start = input。时间戳}}else{//其他活动if (input.timestamp.after(state.end)){状态。Start = input。时间戳的状态。End = input。时间戳的状态。活动=输入。Activity}} //返回更新的状态state}最后,我们编写函数,定义基于行历的状态更新方式。
进口org.apache.spark.sql.streaming。{GroupStateTimeout, OutputMode, GroupState} def updateAcrossEvents(user:String, inputs: Iterator[InputRow], oldState: GroupState[UserState]):UserState = {var state:UserState = if (oldState.exists) oldState. if (oldState.exists)get else UserState(user, "", new java.sql.Timestamp(6284160000000L), new java.sql.Timestamp(6284160L)) //我们简单地指定一个旧的日期,我们可以比较和//立即根据我们的数据中的值进行更新(input <- inputs) {state = updateUserStateWithEvent(state, input) oldState.update(state)} state}有了这些部分,现在就可以在查询中使用它们了。如上所述,我们必须指定超时,以便该方法可以超时给定组的状态,并且我们可以控制在超时后没有收到更新时应该对状态做什么。对于本例,我们将无限期地保持状态。
import org.apache.spark.sql.stream . groupstatetimeout withEventTime .selectExpr("User as User ", "cast(Creation_Time/1000000000 as timestamp) as timestamp", "gt as activity") .as[InputRow] //按用户key分组状态。groupbykey (_.user) .mapGroupsWithState(GroupStateTimeout.NoTimeout)(updateAcrossEvents) .writeStream .queryName("events_per_window") .format("memory") .outputMode("update") .start()现在我们可以在流中查询结果:
SELECT * FROM events_per_window,按用户顺序启动我们的示例结果显示了第一个和最后一个时间戳的用户活动:
+----+--------+--------------------+--------------------+ | 用户活动| | |结束开始 | +----+--------+--------------------+--------------------+ | | |自行车2015-02-23 13:30:……| 2015-02-23 14:06:…||a| bike|2015-02-23 13:30:...|2015-02-23 14:06:...| ... | b| bike|2015-02-24 14:01:...|2015-02-24 14:38:...| | b| bike|2015-02-24 14:01:...|2015-02-24 14:38:...| | c| bike|2015-02-23 12:40:...|2015-02-23 13:15:...| ... | d| bike|2015-02-24 13:07:...|2015-02-24 13:42:...| +----+--------+--------------------+--------------------+接下来是什么
在这篇博客中,我们扩展了两个用于高级流分析的附加功能和api。第一种方法允许删除以水印为界的副本。使用第二种方法,您可以实现自定义的有状态聚合事件时间基本而且事件时间处理.
通过使用mapGroupsWithState api的示例,我们演示了如何为事件实现自定义的有状态聚合,这些事件的处理语义不仅可以通过超时定义,还可以通过用户语义和业务逻辑定义。
在本系列的下一篇博客中,我们将探索高级方面flatMapGroupsWithState用例,将在Spark欧盟峰会在都柏林,在一个深入讨论结构化流.
阅读更多
从Apache Spark 2.0开始,在结构化流的开发和发布过程中,我们已经编译了一个全面的技术资产概要,包括我们的结构化系列博客。你可以在这里阅读相关资产:
在Databricks上尝试Apache Spark的结构化流媒体最新api数据湖屋平台bob体育客户端下载.



