Apache火花TM3.0.0がDatabricks Runtime 7.0で利用できるようになりました。Spark 3.0.0はオ,プンソ,スコミュニティでの多くのコントリビュ,トが結実したものです。3400年以上のパッチが含まれ,Python APIおよびANSI SQLの機能拡充に加え,開発や調査が行いやすくなるような工夫が施されています。オープンソースプロジェクトとして10年目を迎え,多くの参加者の意見と多様なユースケースに応え続けてきた結果が反映されています。
Apache Spark 3.0の主な新機能:

Apache Spark 3.0.0の導入に際しては,大きなコ,ド変更は不要です。詳細にいては,移行ガ@ @ドを参照してください。
Spark開発のこれまでの10年間
Sparkは,カリフォルニア大学バ,クレ,校の研究ラボAMPlabでのデ,タ集約型コンピュ,ティングに関する研究から生まれました。AMPlabの研究者は当初,大手インターネット企業との共同研究を通じてデータとAIの問題に取り組んでいましたが,それらの問題が,増え続けるデータ量に対応しようとするあらゆる企業において,いずれは共通の課題となることに気づきました。そこで,これらのワークロードのための新たなエンジンと,ビッグデータを利用しやすくするためのAPIの開発に着手したのです。
コミュニティでの開発を通じてSparkはさまざまな分野で活用されるようになりました。ストリーミングやPythonとSQLに関する新しい機能が追加され,今ではそれらが火花の主要なユースケースになっています。そして,この継続的な取り組みを通じて,火花はデータ処理,データサイエンス,機械学習,データ分析ワークロードにおける事実上の標準となるに至りました。Apache火花3.0 は、こうした方向性に沿って開発され、広く使用されている Python と SQL の両言語のサポートを大幅に改善し、全般的なパフォーマンスと運用性の最適化を図っています。
Spark SQLエンジンの改善
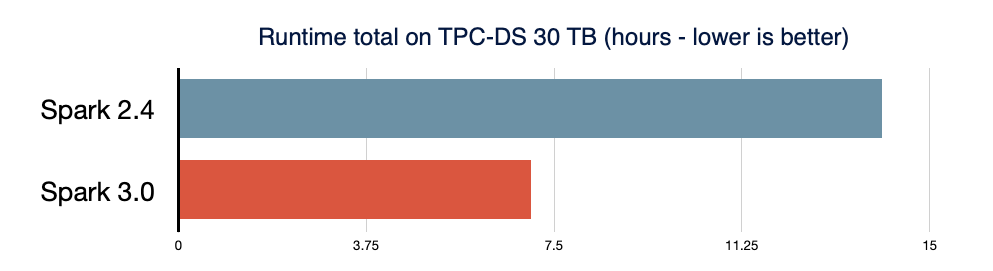
Spark SQLは多くのSparkアプリケションを支えるエンジンです。たとえば,Databricksでは,Spark API呼び出しの90% 以上で,DataFrame、数据集、SQLの各APIとSQLオプティマイザによって最適化されたライブラリを使用しています。つまり,PythonやScalaで開発を行う場合であっても,作業の大半に火花SQLエンジンが関わっていることになります。Spark 3.0でコントリビュ,トされたパッチの46%は,sqlのパフォ,マンスとANSIとの互換性に関するもので,下の図に示すように,Apache Spark 3.0はSpark 2.4に比べ,合計実行時間が約半分にまで改善されています。次に,Spark SQLエンジンの4の新機能にいて説明します。
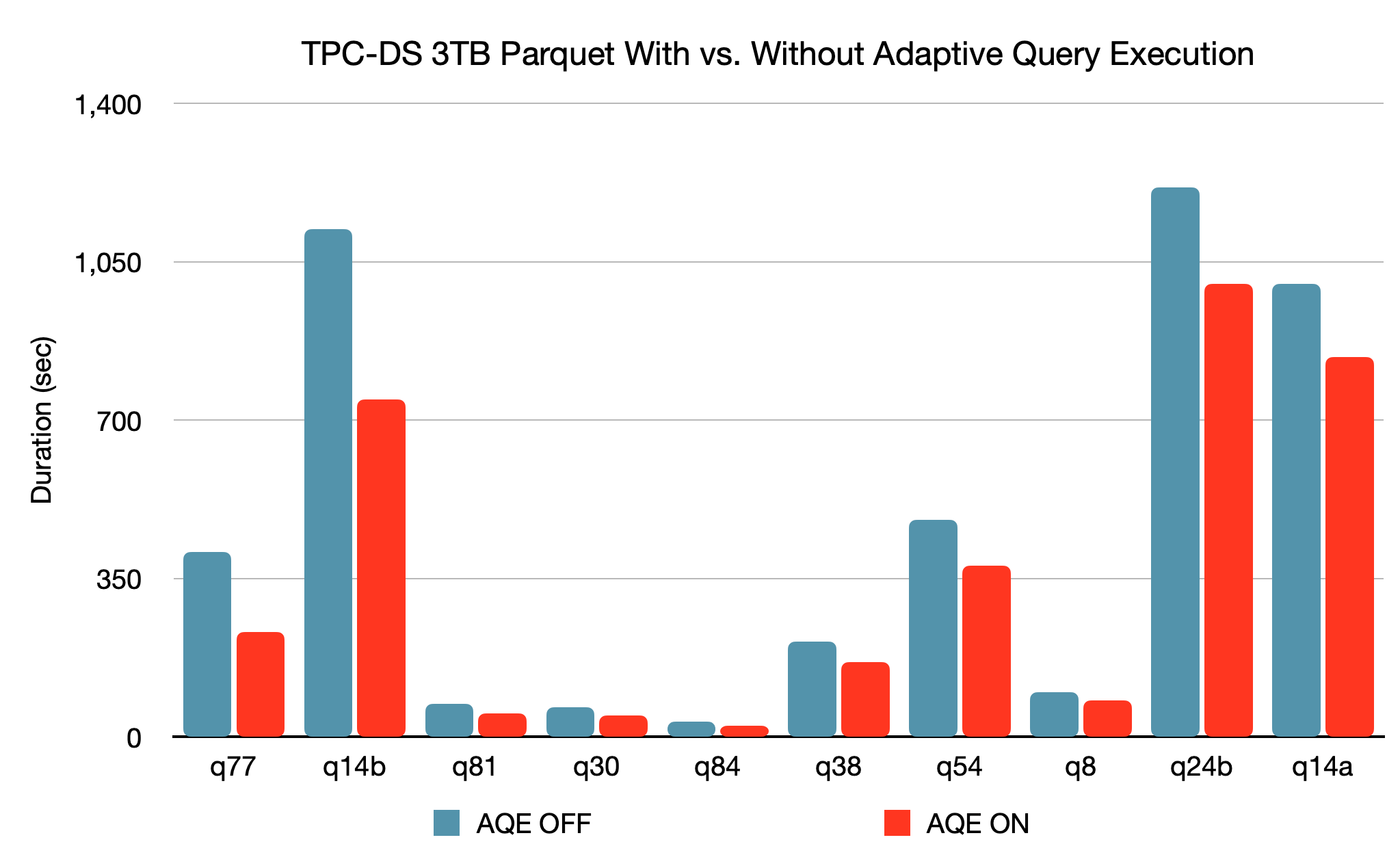
Spark SQLエンジンには,4 . .新しい適応型クエリ実行(AQE:自适应查询执行)フレームワークでは,より効率的な実行計画を生成することでパフォーマンスの向上とチューニングの簡略化を行います。正確な統計情報の不足やコスト推定の誤りにより最初の計画が十分に最適化されていない場合でも有効です。火花では,ストレージとコンピューティングが分離されており,データの到着が予測できないことから,従来のシステムに比べて実行時の適応性が重要になります。そこで,Apache Spark 3.0では適応型の最適化機能が新たに3導入されました。
- シャッフルパ,ティションの動的統合により,シャッフルパ,ティション数のチュ,ニングを簡略化,もしくはチュ,ニング自体を不要にします。ユーザーは,事前に多めのシャッフルパーティション数を設定しておくことができ,AQEは実行時に隣接する小さなパーティションを大きなパーティションに結合できます。
- 結合戦略の動的切り替えにより,統計情報の不足やサイズ推定の誤りのために十分に最適化されていない計画が実行されることを,一定の割合で回避します。ソートマージ結合が自動的にブロードキャストハッシュ結合に変換されるため,チューニングの簡略化とパフォーマンスの向上が期待できます。
- スキュ,デ,タ結合時の動的な最適化により,スキュ,デ,タ結合時の処理の偏りに起因する極端なパフォ,マンスの低下を防ぎます。AQEがシャッフルファイル統計からスキューを検出した場合,スキューが発生しているパーティションを小さなパーティションに分割したうえで,対応するパーティションと結合させます。その結果,スキュ,が並行処理されることとなり,全体的なパフォ,マンスが向上します。
3结核病のTPC-DSベンチマークでは,AQEが機能していない場合と比べてAQEが機能している火花のパフォーマンスは2つのクエリで1.5倍高速になり,別の37のクエリでも1.1倍に向上することが確認されています。
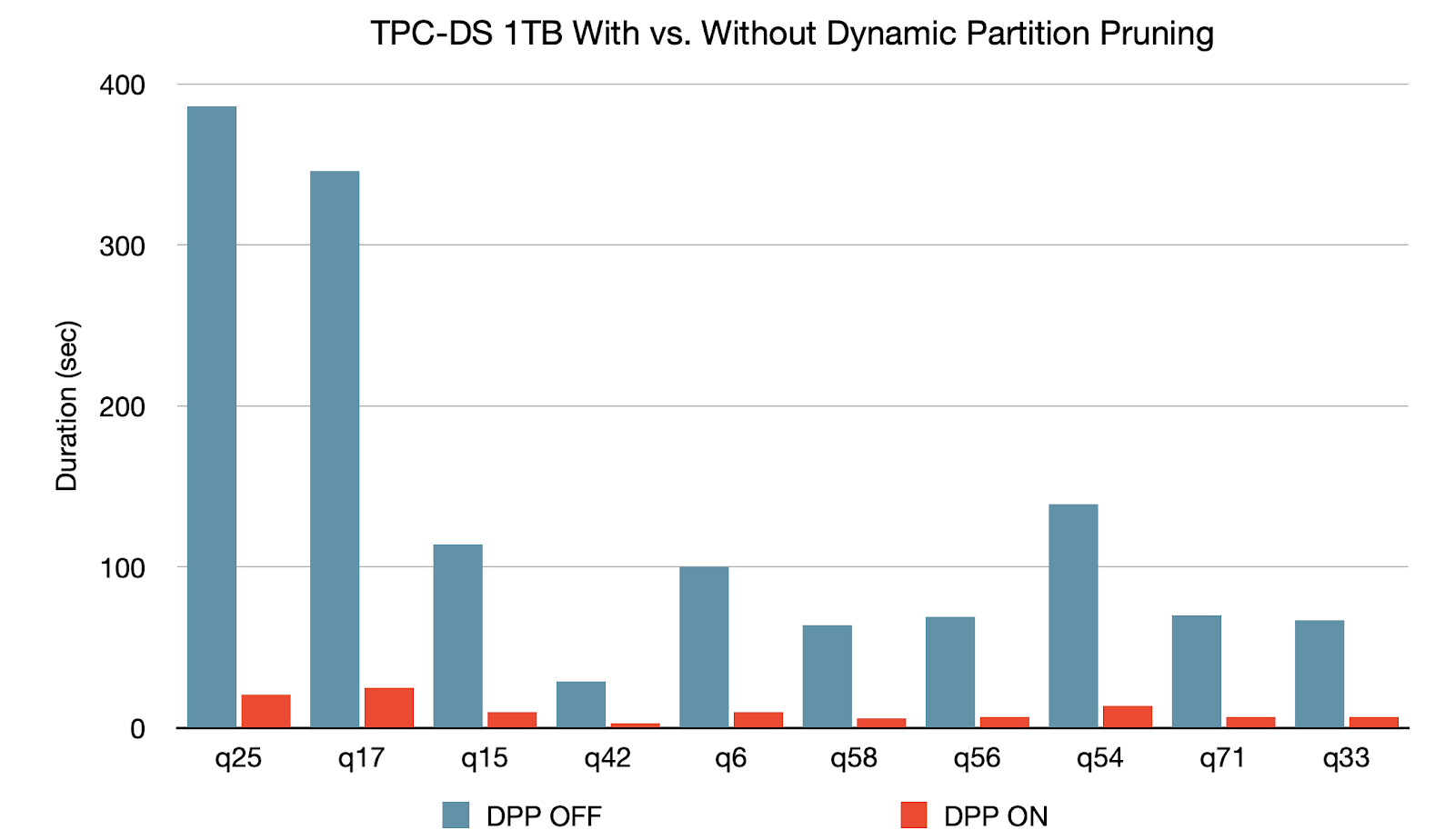
動的パ,ティションプル,ニングは,オプティマ@ @ @ @ @ @ @ @ @ @ @ @ @ @ @ @ただし,スタースキーマにおいては,1つないし複数のファクトテーブルが複数のディメンションテーブルを参照する形になることから,通常はスキップの可否が判別できません。そこで,動的パーティションプルーニングにより,ディメンションテーブルのフィルタ結果からスキップ可能なパーティションを特定し,結合時にファクトテーブルから読み込むパーティションに対してプルーニングを行えるようにしました。TPC-DSベンチマークでは,102件のクエリのうち60件で2倍から18倍へと大きく速度が向上しています。
ANSI SQLに準拠することで,ワ,クロ,ドを他のSQLエンジンからSpark SQLに移行しやすくしました。Spark 3.0では,ANSI SQLに合わせて先発グレゴリオ歴に切り替えています。また,ANSI SQLの予約キーワードを識別子として使用することをユーザーが禁止できるようにしました。さらに,算術演算実行時のオーバーフローチェックや,定義済みスキーマでテーブルにデータを挿入する場合のコンパイル時型適用も導入しています。新たにこれらの検証機能を用意したことで,デ,タの品質が改善されています。
結合ヒント:コンパイラの改善は継続的に行われていますが,どのような場合においても常に最適な決定が行われる確証はありません。結合時のアルゴリズムは,統計と経験則に基づいて設計されています。コンパイラにおいて最適な決定が行われない場合,ユーザーは結合ヒントを使用してオプティマイザの計画選定に関与することができます。火花3.0では,従来の結合ヒントに加え,SHUFFLE_MERGE, SHUFFLE_HASH, SHUFFLE_REPLICATE_NLの3つの結合ヒントを新たに追加しました。
Python APIの強化:PySparkと考拉
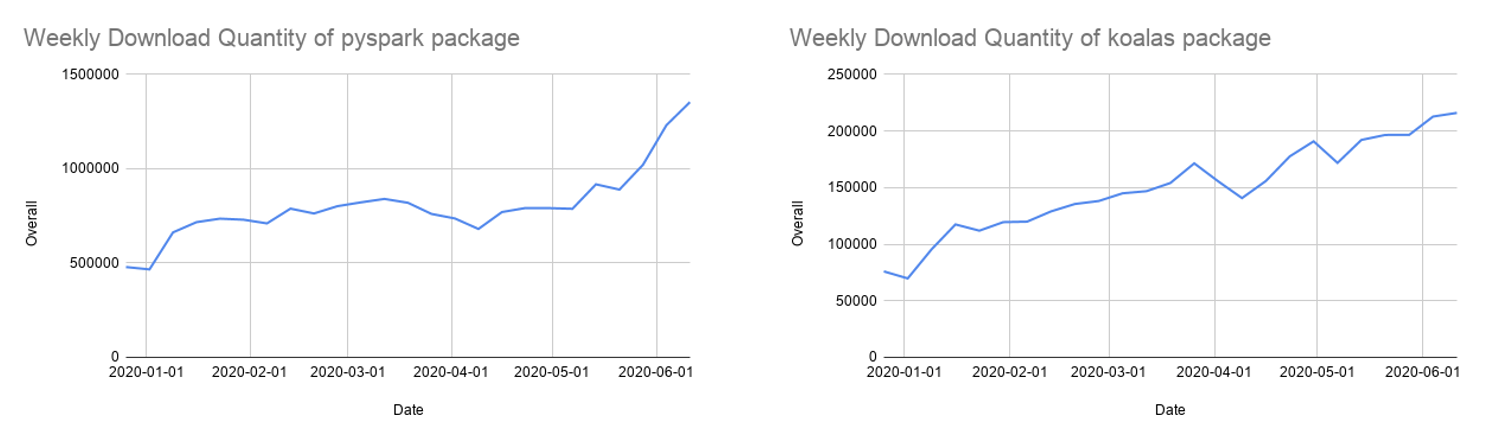
Pythonは火花で最もよく使用される言語であり,Apache火花3.0の開発においても重点項目に挙げられていました。数据库の笔记本コマンドの68%はPythonで記述されており,Apache SparkのPython APIであるPySparkは,PyPI(Python包索引)で毎月500 万回以上ダウンロ,ドされています。

多くのPython開発者がデータの構造化と分析に熊猫APIを使用していますが,熊猫APIはシングルノードでの処理しか行えません。そこで,Databricksでは,pandas APIをApache Spark上に実装した考拉の開発も行っています。デタサエンティストが分散環境でビッグデタを扱う際の生産性の向上を目的としたものです。考拉では、プロットサポートなどのために PySpark で多くの関数を作成することなく、クラスタ全体を対象として効率的な処理が行えます。
1 .年以上の開発を経て,考拉は,熊猫APIの80%程度をカバ,するに至りました。2週間に1回の頻度で更新が続けられており,PyPIでの毎月のダウンロード件数も急激に増加して85 万件に達しています。考拉は、シングルノードで動作する pandas API のコードを容易に移行できる API です。一方、同様に多くのユーザーから支持を集めている Python APIとして、PySpark があります。
Apache 3.0火花では,次の複数の項目でPySpark APIを拡充しています。
- 型ヒントを備えた新しいpandas API:熊猫UDFはPySparkのユーザー定義関数のスケーリングや熊猫APIのPySparkアプリケーションへの統合を目的に,火花2.3以降から導入されています。しかし,従来のインターフェイスでは,UDFで新たに型が追加された場合に,その把握が難しいという問題がありました。火花3.0では,大熊猫UDFでの型の増加に対処するため,Pythonの型ヒントを活用する新しい熊猫UDFインターフェイスを導入しています。新しい▪▪ンタ▪▪フェ▪▪スは,よりPythonに近くなり,わかりやすくなっています。
- pandas UDFの新しい型とpandas関数API:Apache 3.0火花では,大熊猫UDFの新しい型が2つ追加されています。「シリズのテレタからシリズのテレタ“と”複数シリズのテレタからシリズのテレタです。これらは,デ,タのプリフェッチや処理負荷の高い初期化を行う場合に有用です。また,新しい熊猫関数APIとして,地图とco-grouped地图が追加されています。詳細にいては,こちらのブログ記事を参照してください。
- エラ,処理の改善:PySparkのエラー処理は,Pythonユーザーにとって少しわかりにくいものになっていました。火花3.0では,PySparkの例外を簡略化し,不要なJVMスタックトレースを表示させないようにして,よりPythonに近づけました。
Pythonのサポ,トの改善とSparkのユ,ザビリティ向上は,今後も最優先の開発項目です。
氢气プロジェクトにおけるストリ,ミング機能と拡張性の改善
火花3.0では,氢プロジェクトにおける主要コンポーネントが完了し,ストリーミングと拡張性を改善する新機能が導入されています。
- アクセラレ,タ対応スケジュ,リング:氢プロジェクトは,深層学習と火花でのデータ処理をより適切に統合するための取り組みです。GPUとその他のアクセラレータは,深層学習ワークロードのアクセラレーションに広く使用されています。ハードウェアアクセラレーションの効果をターゲットプラットフォームに反映させるため,火花3.0では既存のスケジューラを強化し,クラスタマネージャをアクセラレータに対応させました。ユ,ザ,は,検出スクリプトを使用して設定を行い,構成を介してアクセラレータを指定することができ,新しい抽样APIを呼び出してそれらのアクセラレータを利用できます。
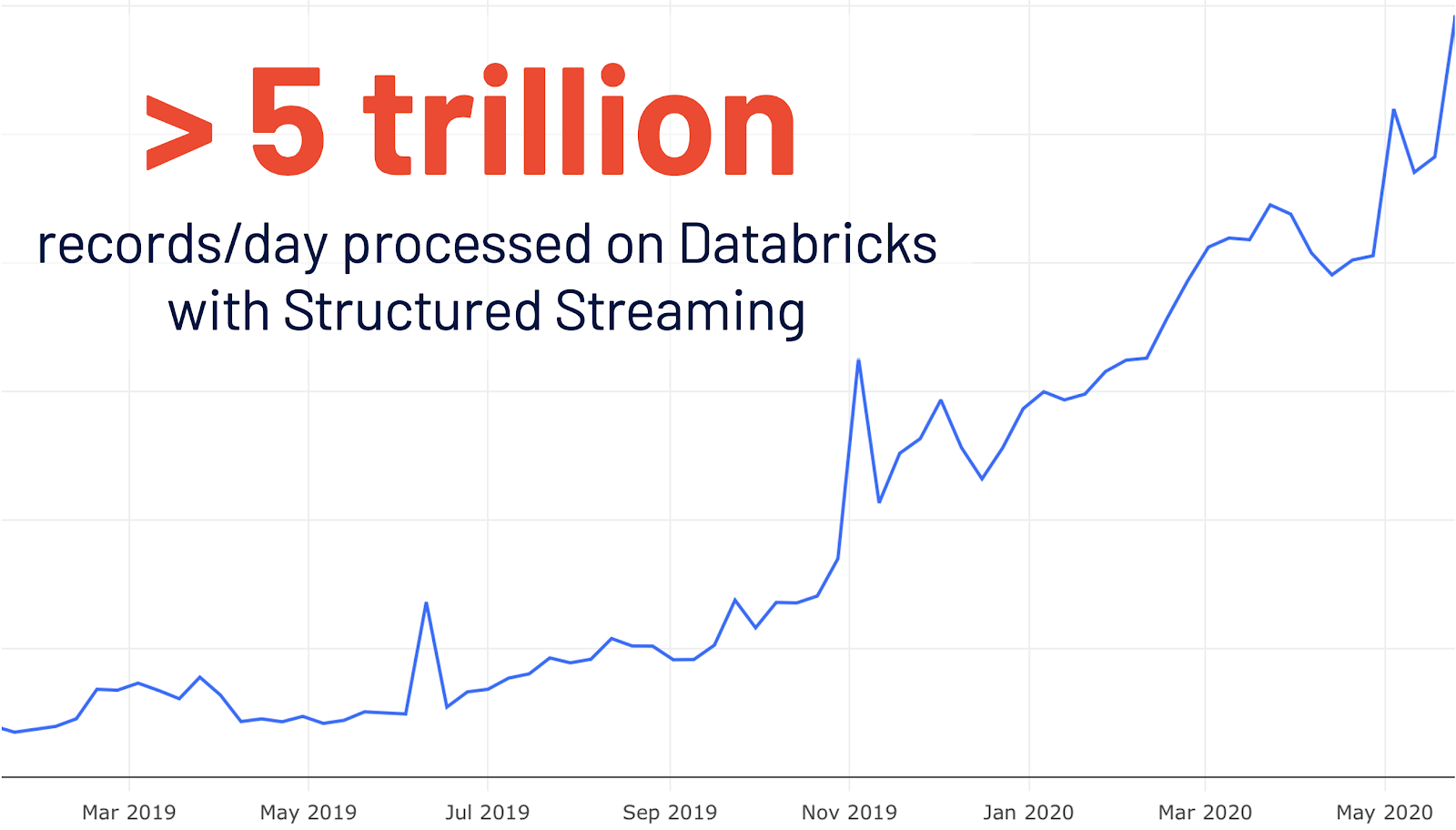
- 構造化ストリ,ミング用の新しいSpark UI:構造化ストリ,ミングは,Spark 2.0で初めて導入されました。データブリックスでの構造化ストリーミングの使用は対前年比で4倍に伸び,1日で5兆件以上が処理されています。Spark 3.0では,これらのストリ,ミングジョブの詳細を把握するために,専用の新しいSpark UIが追加されました。また,1)完了したクエリジョブのストリーミングに関する集約情報と,2)ストリーミングクエリに関する詳細な統計情報の2つの統計セットが提供されています。
- モニタリング指標:データパイプラインを管理するうえで,データの品質に影響する変更を継続的にモニタリングすることが必要です。Apache火花3.0 では、バッチ処理アプリケーションとストリーミングアプリケーションのモニタリング機能であるモニタリング指標を導入しました。モニタリング指標は、DataFrame のクエリで自由に定義できる集約関数です。バッチクエリが終了、またはストリーミング期限に到達するなどして DataFrame の実行が完了するとすぐに、前回完了時以降のデータ処理について、各指標が名前付きイベントに格納されて送信されます。
- 新しいカタログプラグerepンapi:既存のデタソスAPIでは,外部デタソスのメタデタへのアクセスや操作が行えません。Apache火花3.0 では、機能を強化したデータソース APIのバージョン 2 を用意し、新しいカタログプラグイン API を導入しました。外部データソースにカタログプラグイン API とデータソース API バージョン 2 を実装すると、対応する外部カタログの登録後に、ユーザーがマルチパート識別子を通じて外部テーブルのデータとメタデータの両方を直接操作できるようになります。
Apache Spark 3.0の最新情報をさらに詳しく
火花3.0はオープンソースコミュニティにおいて3400件以上のJiraチケットが解決されたメジャーリリースです。個人だけでなく,データブリックス,谷歌、微软、英特尔、IBM、阿里巴巴、Facebook、英伟达,Netflix, Adobeなどの企業も加えた440以上のコントリビュータが開発に貢献しました。このブログ記事では,火花3.0におけるPython API、ANSI SQL準拠,ストリーミング,パーティション・プルーニングなどについて説明しましたが,他にも紹介できていない多くの機能があります。詳細にいては,リリ,スノ,トをご覧ください。デ,タソ,ス,エコシステム,モニタリングなどのSparkの他の改善事項をご覧ください。
Apache Spark 3.0を使ってみる
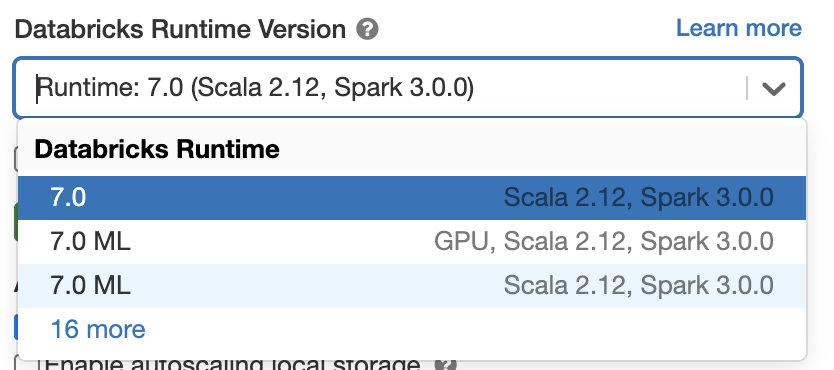
Databricks Runtime 7.0でApache Spark 3.0をお試しいただけます。無料トラ@ @アルアカウントを取得してください。すぐに使用を開始できます。クラスタを起動させる際に,バージョン7.0を選択するだけで火花3.0が使用できます。
機能とリリスの詳細にいてはこらをご覧ください。














