




自适应查询执行:加速运行时引发的SQL
这是一个联合工程砖Apache引发的工程团队之间的工作——Wenchen粉丝,范龙佩(Herman van Hovell和玛丽安薛——一个……
2020年5月29日 在工程的博客
这是一个联合工程砖Apache引发的工程团队之间的工作——Wenchen风扇,范龙佩(Herman van Hovell和玛丽安薛
多年来,有一个广泛和持续努力改善火花SQL查询优化器和规划师为了生成高质量的查询执行计划。最大的一个改进是基于成本优化的框架,利用各种数据的收集和统计数据(例如,行数,不同值的数量,NULL值,最大/最小值,等等)来帮助火花选择更好的计划。这些基于成本的优化技术的例子包括选择正确的连接类型(广播散列连接与排序合并连接),选择正确的构建方面的散列连接,或调整多路连接的连接顺序。然而,过时的统计和不完美的基数估计值可能导致次优的查询计划。自适应查询执行,在即将到来的新的Apache火花TM3.0版本7.0在砖和可用的运行时,为了解决这样的问题,现在看来重新优化和调整查询计划基于运行时统计数据收集在查询执行的过程。
适应查询执行的一个最重要的问题是什么时候再优化。火花运营商往往管线式和并行执行流程。然而,洗牌或广播交流打破了这种管道。我们称之为实体化点和使用术语“查询阶段”来表示这些物质化点部分有界的一个查询。每个查询阶段实现它的中间结果和以下阶段只能继续如果所有运行实体化的并行过程已经完成。这对于以提供了一种自然的机会,因为这是当数据统计所有分区可用和连续操作还没有开始。
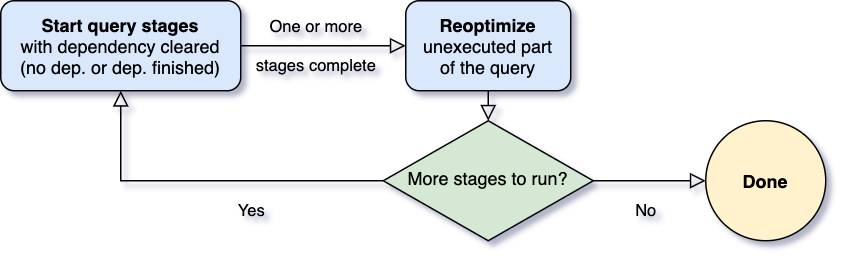
查询开始时,自适应查询执行框架首先开始叶阶段阶段,不依赖于任何其他阶段。当一个或多个阶段完成实体化,框架标志着他们在物理查询计划并更新逻辑完成相应的查询计划,与运行时统计数据从完成检索阶段。框架基于这些新数据,然后运行优化器(逻辑优化规则的选择列表),物理规划,以及物理优化规则,其中包括常规的物理规则和adaptive-execution-specific规则,如合并分区,斜加入处理,等。现在,我们已经有了一个新优化的查询计划的完成阶段,自适应框架将执行搜索并执行新的查询都被物化阶段的儿童阶段,并重复上述execute-reoptimize-execute过程,直到整个查询完成。
在火花3.0中,AQE框架附带三个特点:
下面的部分将详细讨论这三个特性。
运行查询时火花处理非常大的数据,洗牌通常有一个非常重要的对查询性能的影响在许多其他的事情。洗牌是一项昂贵的操作,因为它需要在整个网络中传递数据,以便数据重新分配在下游运营商要求的一种方式。
混乱的一个重要性质是分区的数量。最好的分区数量是数据依赖,但数据大小可能不同不同阶段阶段,查询来查询,让这个数字很难调整:
为了解决这个问题,我们可以设置一个相对大量的洗牌分区开始,然后相邻小分区合并成更大的分区在运行时通过观察洗牌文件数据。
举个例子,假设我们正在运行的查询选择马克斯(i)由j。从资源组输入数据(资源是很小所以分组之前只有两个分区。最初的洗牌分区号设置为5,所以本地分组后,部分分组数据重组成五个分区。没有AQE,火花将五项任务开始做最后的聚合。然而,这里有三个非常小的分区,这将是一个浪费开始对每一个单独的任务。
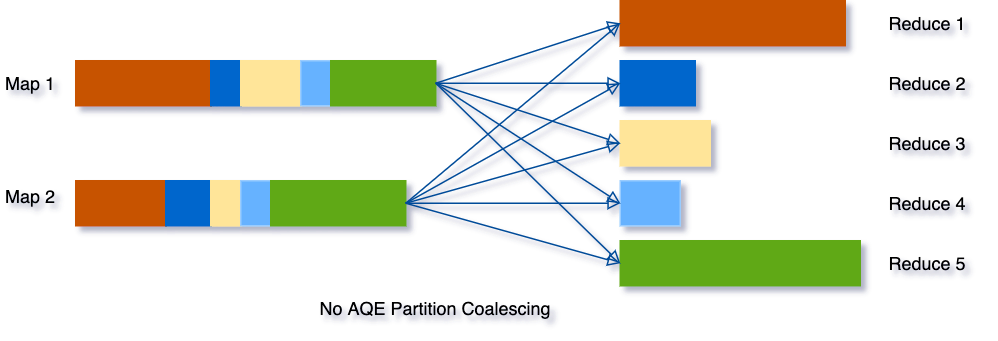
相反,AQE聚集成一个和这三个小分区,因此,最后聚合现在只需要执行三个任务,而不是5个。

火花支持许多连接策略,其中广播散列连接通常是最高效的如果一方加入可以适合在内存中。,出于这个原因,引发计划广播散列连接,如果连接关系的估计规模低于broadcast-size阈值。但是很多事情可以让这个大小估计出错——比如一个选择性滤波器的存在,或者是一系列复杂的连接关系运营商除了扫描。
为了解决这个问题,现在AQE重新计划加入策略在运行时基于最准确的连接关系的大小。在下面的例子中,我们可以看到右边的加入是发现小于估计和广播也足够小,所以AQE后以静态计划排序合并连接现在转换为一个散列连接播放。
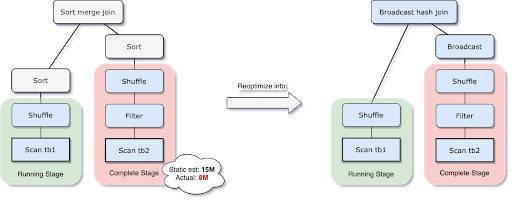
广播的散列连接转换在运行时,我们可以进一步优化常规局部转移(即洗牌。洗牌,读取每个映射器上而不是每个减速器的基础上)来减少网络流量。
数据倾斜时数据集群分区的分布是不均匀的。严重的倾斜可以显著降低查询性能,尤其是连接。AQE倾斜连接优化检测这种倾斜自动从洗牌文件数据。然后将分区分成小subpartitions倾斜,将加入到相应的分区分别从另一侧。
让我们把这个表联接表B的例子,在这表有一个分区A0显著大于其他分区。
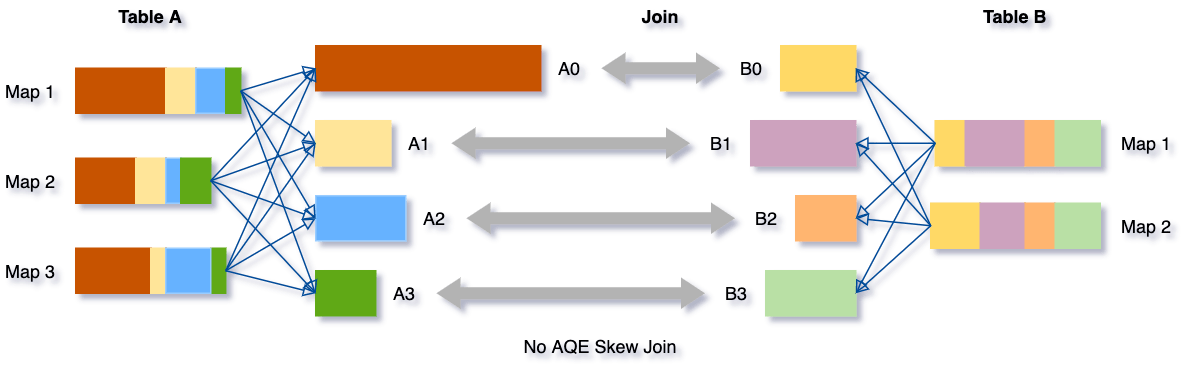
倾斜连接优化将因此分裂A0分割成两个subpartitions并加入他们每个人相应的分区表B的B0。
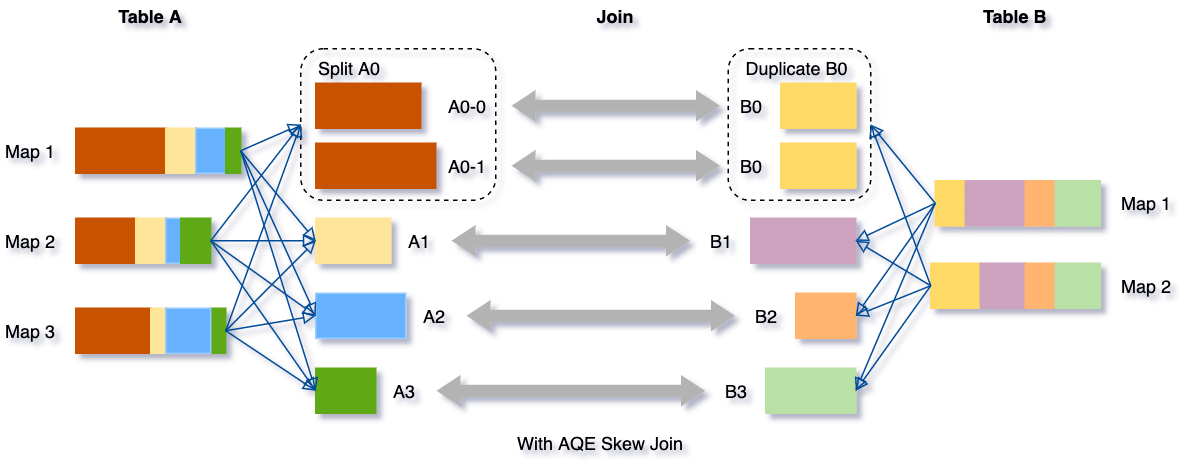
没有这种优化,会有四个任务排序合并连接一个任务将运行更长的时间。这种优化后,会有五个任务运行加入,但每个任务需要大致相同的时间,导致整体更好的性能。
在我们的实验中使用TPC-DS数据和查询,适应了一个8 x加速查询执行的查询性能和32查询有超过1.1倍加速下面的图10 TPC-DS查询拥有最AQE性能改进。
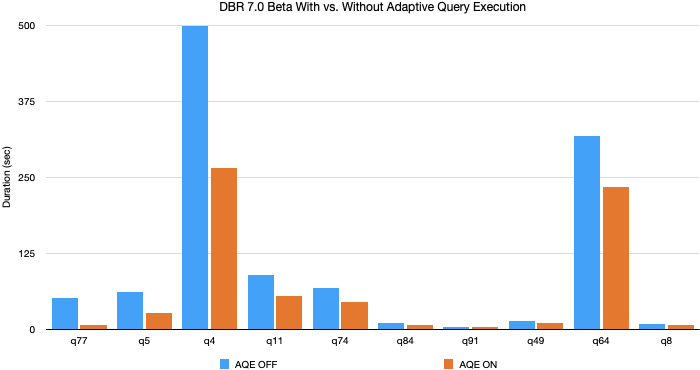
大多数这些改进来自动态分区合并和动态连接策略切换自随机生成TPC-DS数据没有倾斜。然而我们看到更大的改进在生产工作负载AQE是杠杆的所有三个特征。
可以通过设置启用SQL配置spark.sql.adaptive AQE。启用为true(默认错误引发3.0),并应用如果查询符合下列标准:
通过查询优化较少依赖静态统计,AQE解决了一个最伟大的斗争引发基于成本的优化——之间的平衡数据收集开销和估计精度。达到最好的估计精度和计划的结果,通常是需要保持详细的,最新的统计数据和一些昂贵的收集,如列直方图,可以用于提高选择性和基数估计或检测数据倾斜。AQE在很大程度上消除这种统计的必要性以及手工调优工作。最重要的是,AQE也使SQL查询优化更有弹性的存在任意udf和不可预测的数据集的变化,例如,数据大小的突然增加或减少,频繁和随机数据倾斜等等。没有必要提前“知道”你的数据。AQE将算出的数据,提高查询计划的查询运行时,速度分析和系统性能提高查询性能。
BOB低频彩在我们了解更多关于火花3.0预览网络研讨会。今天尝试AQE火花3.0免费砖7.0作为我们的砖运行时的一部分。