Les data scientists sont confrontés à de nombreuses difficultés tout au long du workflow de data Science qui entrent leur productivité。Les organizations étant de plus en plus data-driven, il est essentiel de disposer d'un environment collaboratiffacilfacill 'accès aux données et leur visibilité, ainsi que de modèles formés à partir de ces données, d'une reproductibilité et d'insights découverts au sein de ces données。
旅行车

然后
Une plateforme ouverte et unifiée pour exécuter de manière协作tous les类型劳动费用分析,de la préparation des données
à l'analyse exploratoire et à l'analytique prédictive, à grande échelle。








Écrivez du code de manière协作丹斯Python, R, Scala et SQL。Explorez les données grâce à des可视化交互et découvrez de nouveaux insights avec les notebook de Databricks。
翻译代码sécurité grâce à la cocréation,辅助评论,à la自动翻译,辅助intégrations Git et aux contrôles d'accès basés sur les rôles。
Gardez une trace de tous les tests et de tous les modèles à un même安置,捕获la conaissance, publiez de tableaux de bord and facilitez les transferts avec vos homologues et parties prenantes dans l'ensemble du workflow, des données bruts aux insights。
Vous n'êtes + limité par la capacité de stockage de votre ordinateur便携ni par la puissance de calculate not Vous disposez。
米格雷斯快速投票环境本地云grâce à康达的责任,
Et connectez des笔记本à des集群gérés automatiquement pour faire évoluer vos charge de travail analytiques selon vos besoins。
我知道你有多聪明……你的自由之路déjà自由之路和旅行习惯之路。
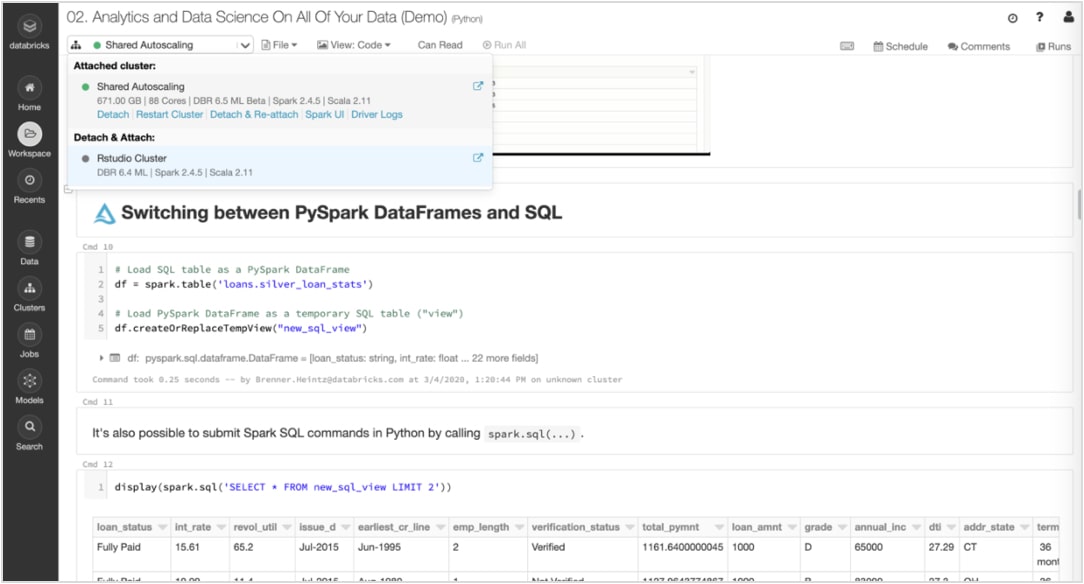
Connectez votre IDE préféré à连续数据库à bénéficier d'un存储de données et d'un计算无限制。Ou utilisez simplement RStudio Ou JupyterLab定向代理Databricks倒une expérience流体。
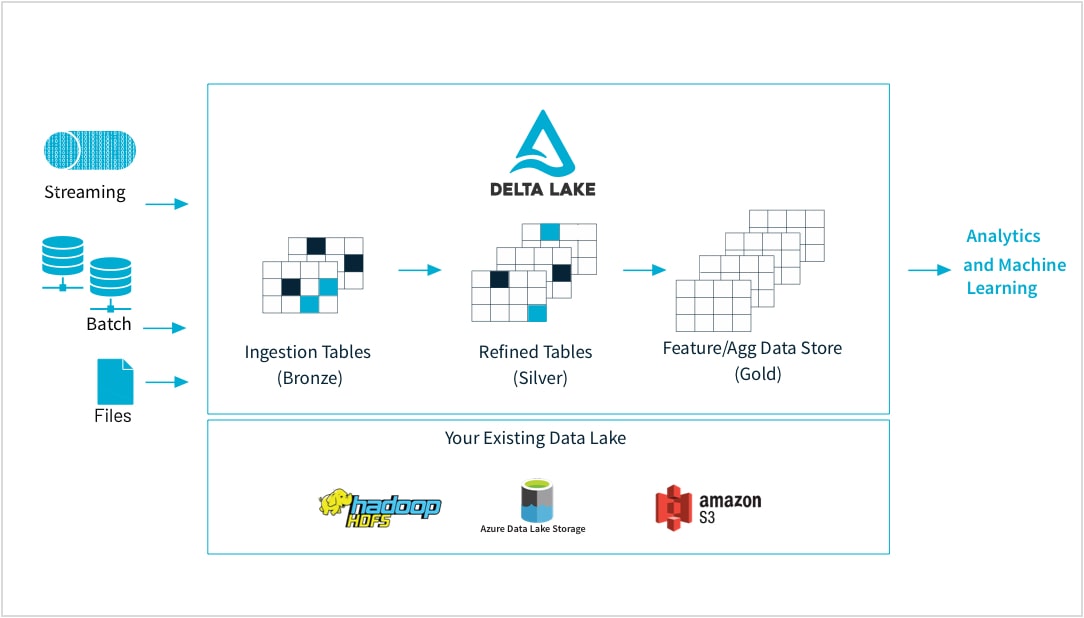
Nettoyez et catalogez toutes vos données au même endroit grâce à三角洲湖,qu'elles soient en batch, en streaming, structurées ou non structurées, et renz -les access à toute votre organisation via UN magasin de données centralisé。
Quand les données arrival, des contrôles de qualité garantissent qu'elles sont prêtes pour l'analytique。Au fur et à测量方式données sont alimentées新鲜事物entrées et et qu elles sont transformées,永久事物répondre aux besoins de conformité。
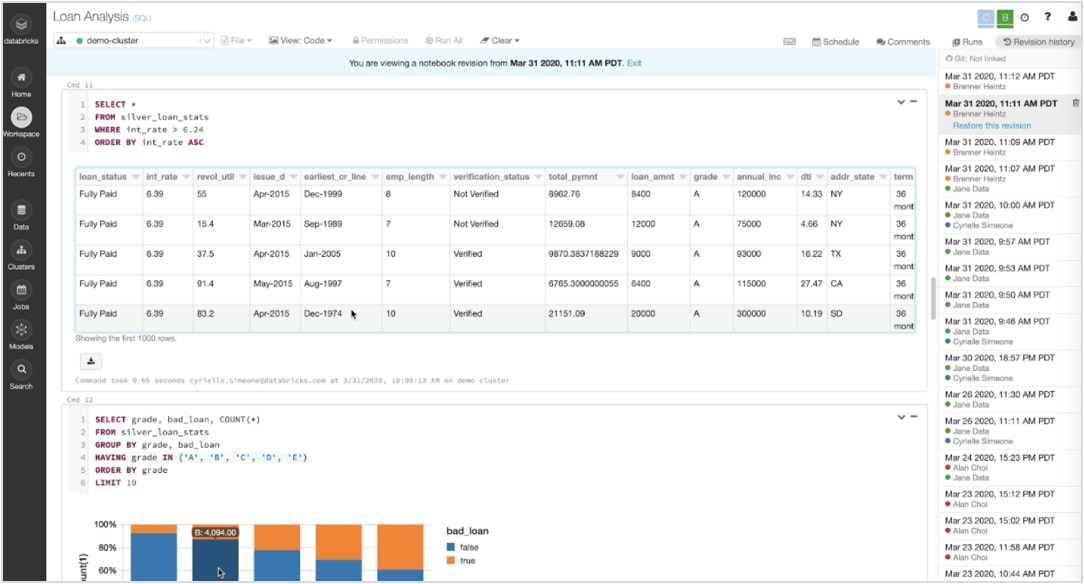
Vous avez fait tout le travail et identifié de nouveaux insights, avec des可视化交互intégrées ou toute autre bibliothèque prise en charge, comme matplotlib ou ggplot。
Partagez et export facility vos résultats转换加速votre analysis on table de bord dynamicque。旅行场景à旅行场景également exécuter des requêtes互动。
Les cellules, Les visuements ou Les笔记本peuvent également être partagés avec un contrôle d'accès basé sur Les rôles et exportés dans plusieurs格式,标注HTML et IPython笔记本。
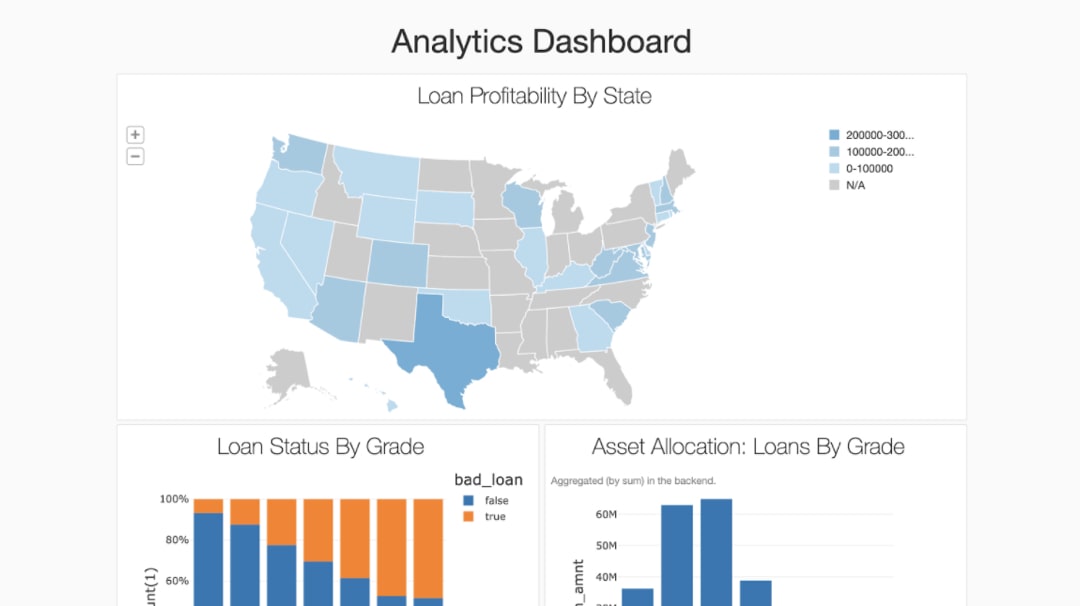

Accédez en unclic à des environments de Machine Learning prêts à l’employi et optimisés, y包括les框架les plus populaires comme scikit-learn, XGBoost, TensorFlow, Keras等。Ou migrez et personnel isez facilities des environment de ML avec Conda。La mise à l'échelle simplifiée sur Databricks vous permet de passer sans effort du small au大数据pour ne plus être limité par La quantité de données que votre ordinateur便携式peut stocker。
Le ML运行时提供des fonctionnalitésAutoMLIntégrées, notamment le réglage des hyperparamètres, la recherche de modèles et bien d'autres éléments encore, afin d'accélérer le workflow de数据科学。例如,accélérez la durée de formation avec des optimologies intégrées sur les algorithmes et frameworks les plus courants, notamment la régression logistique, les modèles basés sur l’arborescence et GraphFrames。
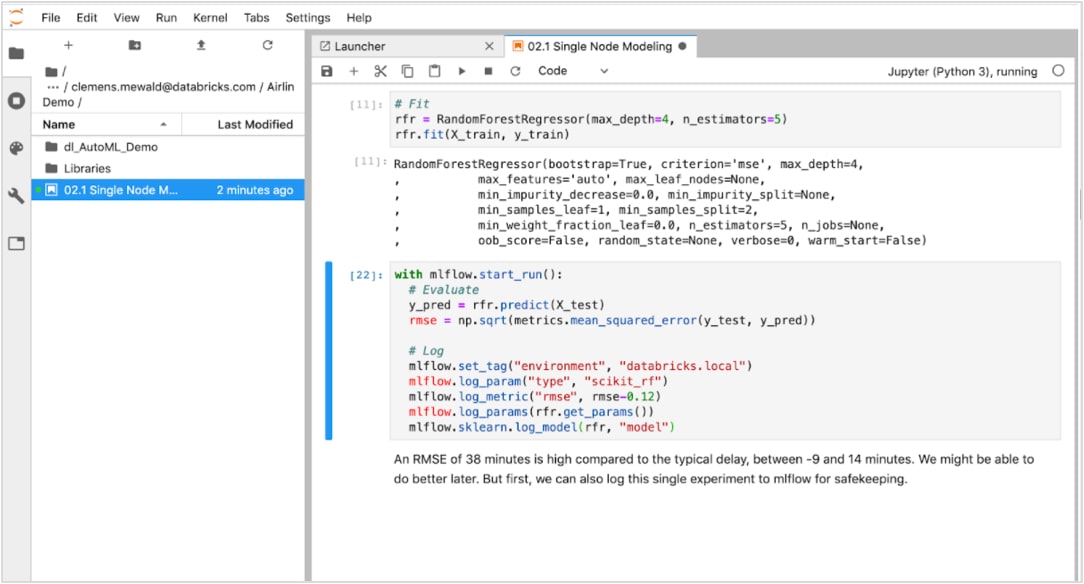
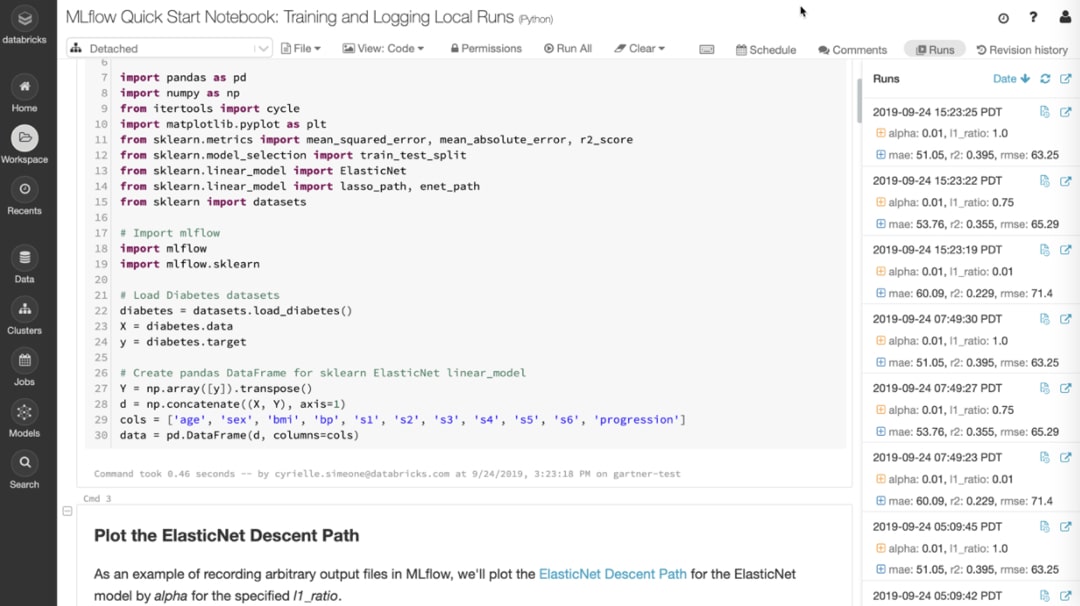
Suivez自动化les测试à partir de n'importe quel framework et enregistrez les paramètres, les résultats et la version du code pour chque exécution avecMLflow管理。
Partagez, découvrez和可视化的工作sécurité综合测试的工作空间,工程和笔记spécifiques à工作人员'exécutions和工作人员的贡献。
Comparez les résultats à l'aide de功能de研究,de trii, de过滤和可视化avancées pour trouver la meilleure版本de votre modèle et revenir rapidement à la bonne版本de votre代码pour cette exécution。
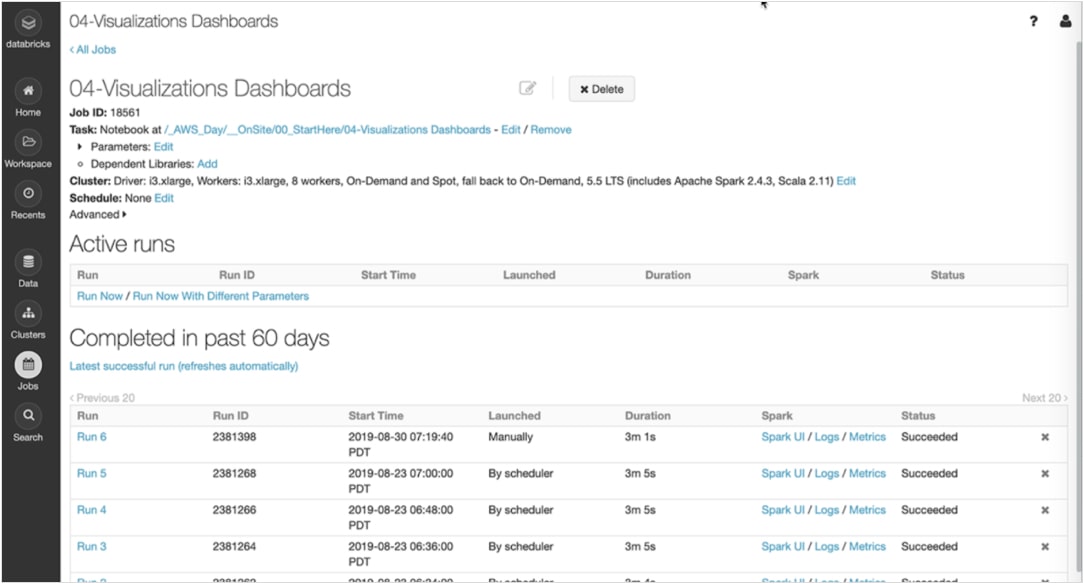
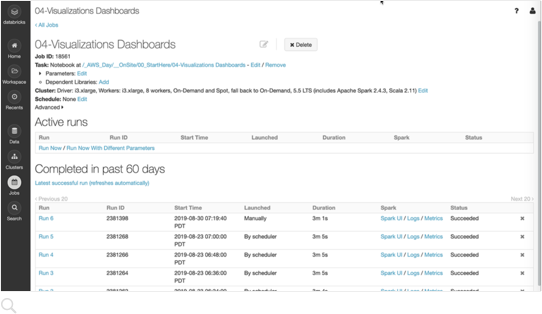
Planifiez des笔记本倒exécuter自动des转换de données et des modélisations, tout en partageant des résultats actualisés。
Paramétrez报警等accédez快速审计及监控等dépannage simplifiés

![]()
Shell a déployé un outil de数据科学au niveau mondial pour mieux gérer et optimiser le stock de pièces détachées d'une valeur d'un million ard de dollar qu'elle détient en cas de rupture de ses资产。
Prêt à démarrer ?