工程数据
Des dizaine de million de charges de labor de production s 'exécutent quotidiennement sur Databricks


进口及改造设施données法国进口及运输plateforme Databricks Lakehouse.管弦乐队的工作流程,生产的寓言和conffiez à数据系统自动化的基础设施à大échelle。Maximisez la productivité de vos équipes grâce aux test intégrés de qualité des données et à l'implémentation de bonnes pratiques de développement logiciel。
![]()
统一批量et流
Éliminez les silos: grâce à une API unique et unifiée, ingérez, transformmez et traitez les données en lots et en streaming de manière incrémentielle et à grande échelle, au sein d’une même plateforme
![]()
La priorité: créer de La valeur à partir des données
数据库gère自动化votre基础设施等合成物opérationnels de vos生产工作流:vous pouvez vous集中器sur la valeur plutôt que sur les outils。
![]()
Connectez vos outils préférés
La plateforme Lakehouse ouverte connect et exploite vos outils préférés de数据工程pour l'ingestion des données, l'ETL / ELT et l'orchestration。
![]()
Développez sur la plateforme Lakehouse
La plateforme Lakehouse offre La meilleure base pour créer et partager des assets de données fiables et ultra rapides, avec La con未婚夫que donne La centralisation du contrôle。
“对我们来说,Databricks正在成为我们所有ETL工作的一站式商店。我们与Lakehouse平台的合作越多,对用户和平台管理员来说就越容易。bob体育客户端下载”
——Hillevi Crognale,工程经理YipitData

评论ça marche ?

简化摄取données
特质ETL automatisé
可编制工作流
Observabilité et surveillance de bout en bout
行为宣言données新事物génération
Une base robust pour la gouvernance, la fiabilité et la performance
简化摄取données
Ingérez les données dans votreplateforme Lakehousepour alimenter vos应用d'分析,d'IA等流代理une seule等même来源。自动加载程序Traite automatiquement les fichiers au filde leur arrivée dans le stockage cloud, par le biais de tâches planifiées ou继续。Vous n'avez même pas besoin de gérer les information d ' état。Cet out est capable de tracer des milliards de nouveaux fichiers sans avoir à les indexer dans un répertoire。Il sait aussi déduire automatiquement le schéma des données source et l'adapter au fil du temps。Pour les analyses, la command复制到简化大量的食入三角洲湖用SQL。
“我们发现数据工程的生产率提高了40%——将开发新想法所需的时间从几天缩短到几分钟,并提高了数据的可用性和准确性。”
- Shaun Pearce,首席技术官Gousto
![]()

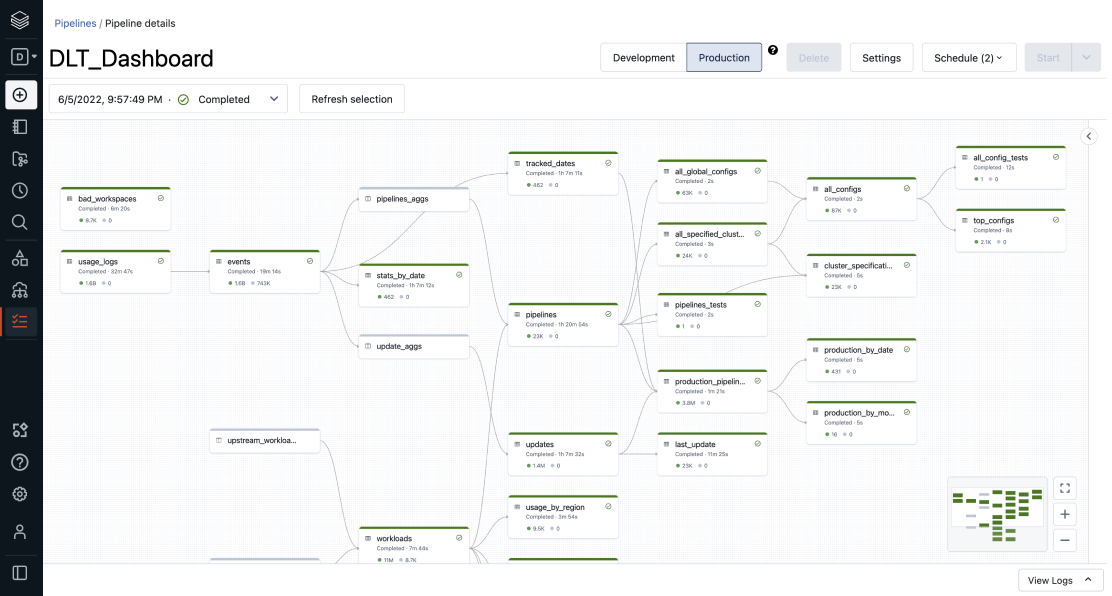
特质ETL automatisé
Une fois ingérées, les données bruutes doivent être transformées pour être exploitables par l'analytique et l'IA。用Delta活动表(DLT), Databricks offre de puissantes fonctionnalités ETL pour les ingénieurs数据,les数据科学家et les分析师。DLT est un框架先锋dans sa catégorie。Il利用une方法déclarative简单倒créer des管道ETL et ML sur des données en lot ou en流媒体.Par ailleurs, il permet de réduire la complexité opérationnelle自动基础设施问题,l'orchestration des tâches, la gestion des errors et reprises 'activité, ainsi que l'optimisation des performance。Grâce à DLT, les ingénieurs peuvent traiter leurs données comme du code et appliquer les bonnes pratiques de génie logiciel, telles que les tests, le monitoring et la documentation, afin de déployer des pipelines fiables à l'échelle。
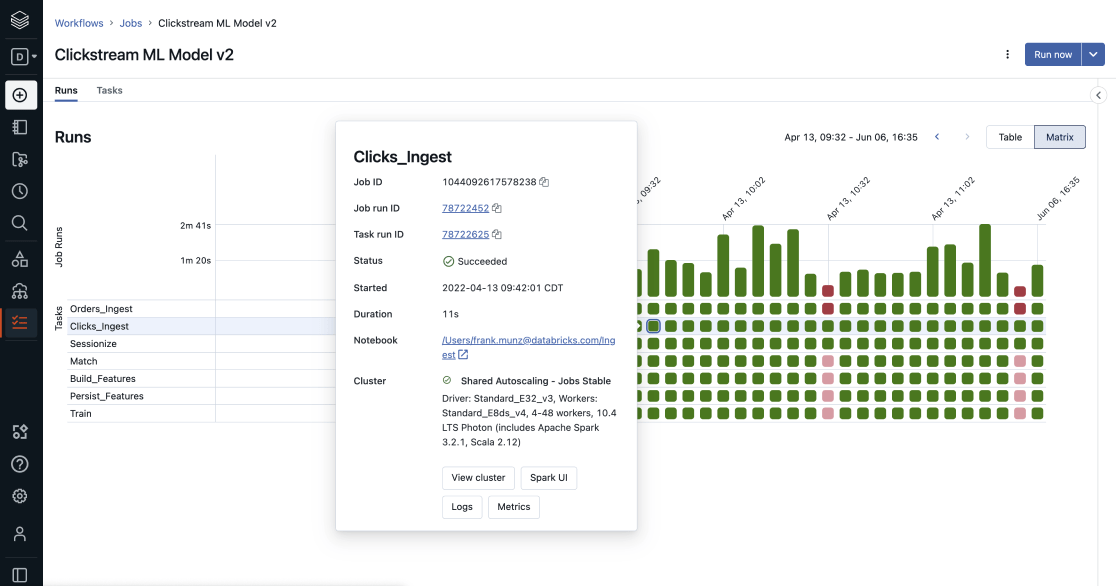
可编制工作流
砖工作流est un service d'orchestration entièrement managé pour tout vos données et applications IA, ainsi que votre analytique。Il provident native de laplateforme Lakehouse.管弦乐队différentes charge de travail couvrant l'intégralité du cycle de vie:Delta活动表等工作将SQL,火花,笔记本,dbt, modèles ML et bien加上安可。Son intégration profonde avec la plateforme Lakehouse sous-jacente vous assure la création et l'exécution de charges fiables en production sur n'importe quel cloud。Les utilisateurs finaux bénéficient en oute d'un monitoring détaillé和centralisé d'une grande simplicité。
“我们的使命是改变我们为地球提供能源的方式。我们在能源领域的客户需要数据、咨询服务和研究来实现这一转变。Databricks的工作流程使我们能够快速和灵活地提供客户所需的见解。”
-数据副总裁吴燕燕Wood Mackenzie
![]()
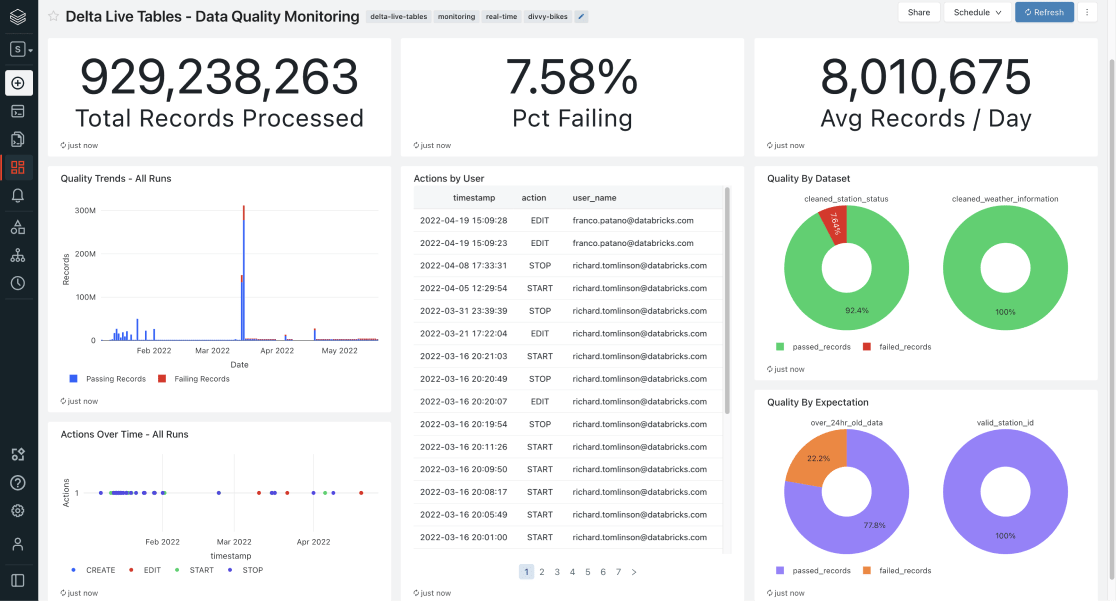
Observabilité et surveillance de bout en bout
La plateforme Lakehouse vous offre une visibilité sur l'ensemble du cycle de vie des données et de l'IA。Elle donne ainsi aux数据工程师et aux équipes opérationnelles une vue de l'état de santé de leurs工作流de生产临时réel, et leur permet de gérer la qualité des données et comprendre les趋向历史。莱斯工作流数据处理à投票处置数据流等数据流的图表和准备工作état等性能tâches生产和管道Delta活动表.Les journaux d ' événements sont également présentés sous forme de tables三角洲湖.Vous pouvez ainsi监视和可视化设施les measurement de performance, de qualité des données et de fiabilité sous n 'importe quel angle。
行为宣言données新事物génération
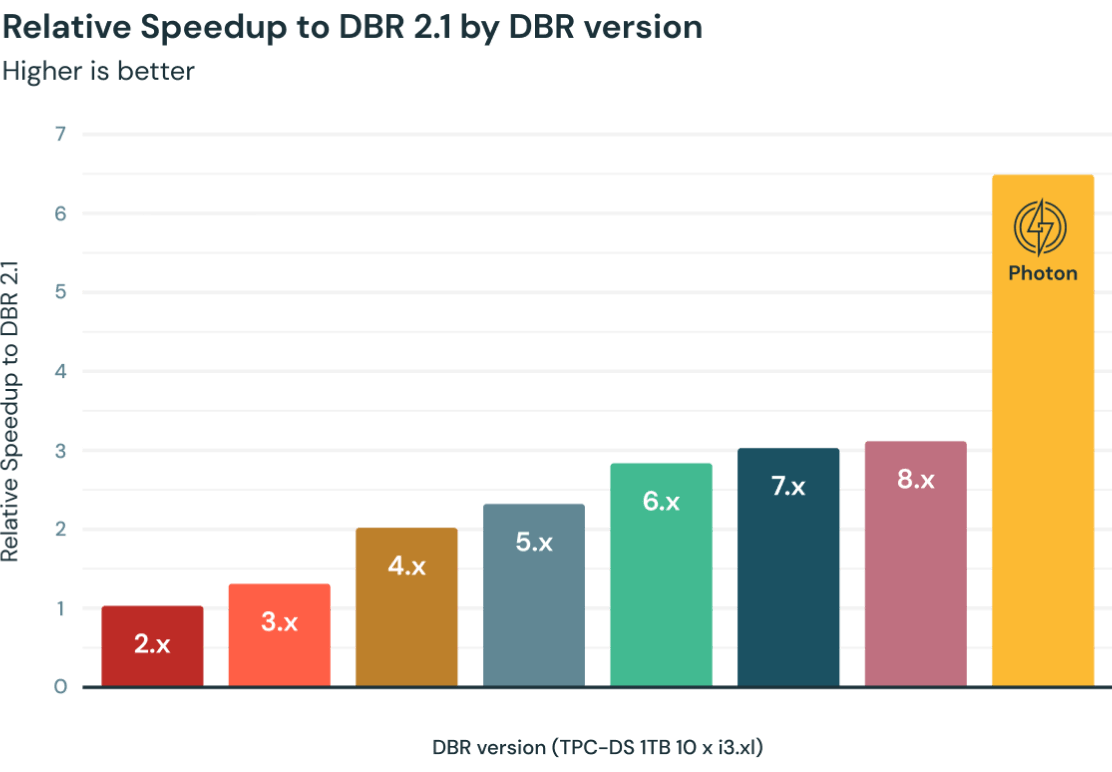
Le数据工程数据库应用程序光子, unmoteur de nouvelle génération兼容avec les API Apache Spark。Il délivre un rapport performance / prix记录Et peut automatiquement prendre en charge des milliers de nounouuds。Spark结构化流提议une API unique et unifiée pour le traitement en lot et en streaming, ce qui permet d'adopter le流过湖屋无修饰符le代码,ni acquérir de nouvelles compétences。

Gouvernance, fiabilité et performance des données à la pointe
法国数据工程咨询公司,vous bénéficiez法国复合材料公司plateforme Lakehouse:统一目录和三角洲湖。沃斯données野兽sont optimisées avec三角洲湖, unformat de stockage开源bob下载地址à la fiabilité assurée par les transactions ACID, qui réunit une gestion évolutive des métadonnées et des性能超快速。Cet outil se combine à统一目录pour vous donner les moyens d'appliquer une stewardance fine à toutes vos données et assets d 'IA,简化行政管理。Un même modèle cohérent permet de découvrir, consulter et partager des données entre les clouds统一目录fournit également une prise en charge本地de三角洲分享, le premier protocole ouvert du secur pour UN partage de données simple et sécurisé avec d ' aures organisations。



Migrer vers Databricks
Vous en avez assez des silos de données, de la lenteur des performance et des coûts élevés associés aux anciens systèmes comme Hadoop et aux entrepôts de données d' enterprise ?Migrez vers Databricks Lakehouse: la plateforme modern pour tous vos as d' use de données, d'analyses et d'IA。
集成
Offrez un maximum de flexibilité à vos équipes de données: appuyez-vous sur合作伙伴联系Et notre écosystème departenaires technologiques倒intégrer de manière透明les outils les加上répandus de数据工程。Vous pouvez par example ingérer les données stratégiques avec Fivetran, les变压器在原地avec dbt et管风琴vos管道avec阿帕奇气流。
摄取de données et ETL
+ tout autre客户端兼容Apache Spark™
Témoignages de clients


En savoir +
Contenu associe

资源是宝贵的。Réunies au même endroit。
电子书
博客
- Disponibilité générale de Databricks Delta Live Tables (DLT)
- Découvrez les工作流数据
- Un aperçu de tout les nouvelles fonctionnalités de streaming structuré développées en 2021 pour Databricks et Apache Spark
- 10 fonctionnalités puissantes qui simplified la geestion des données semi-structurées dans le Lakehouse de Databricks