



原生支持Spark结构化流中的会话窗口
Apache Spark™结构化流允许用户在事件期间在窗口上进行聚合。在Apache Spark 3.2™之前,Spark支持翻滚窗口和滑动获胜…
在我们进入2022年之际,我们想花点时间回顾一下在这方面取得的巨大进步流媒体在Databricks和Apache Spark™的前端!在2021年,工程团队和开源贡献者在三个目标下取得了一些进展:bob下载地址
最终,这些目标背后的动机是使更多的团队能够在Databricks和Spark上运行流工作负载,使客户更容易在Databricks上操作关键任务的生产流应用程序,同时优化成本效益和资源使用。
有两个新的关键特性专门针对降低有状态操作的延迟,以及对有状态api的改进。第一种方法是针对大型有状态操作的异步检查点,它改进了传统的同步和高延迟设计。
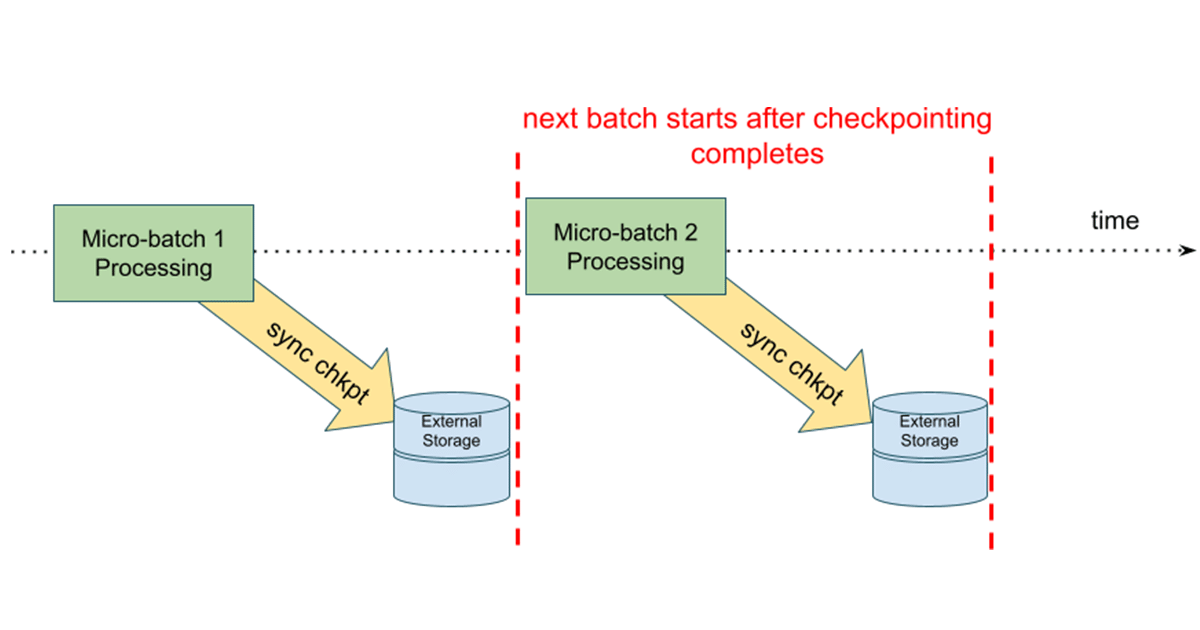
在此模型中,在下一个微批处理开始之前,将状态更新写入云存储检查点位置。这样做的好处是,如果有状态流查询失败,我们可以使用来自最后一个成功完成的批处理的信息轻松地重新启动查询。在异步模型中,下一个微批处理不必等待状态更新被写入,从而提高了整个微批处理执行的端到端延迟。
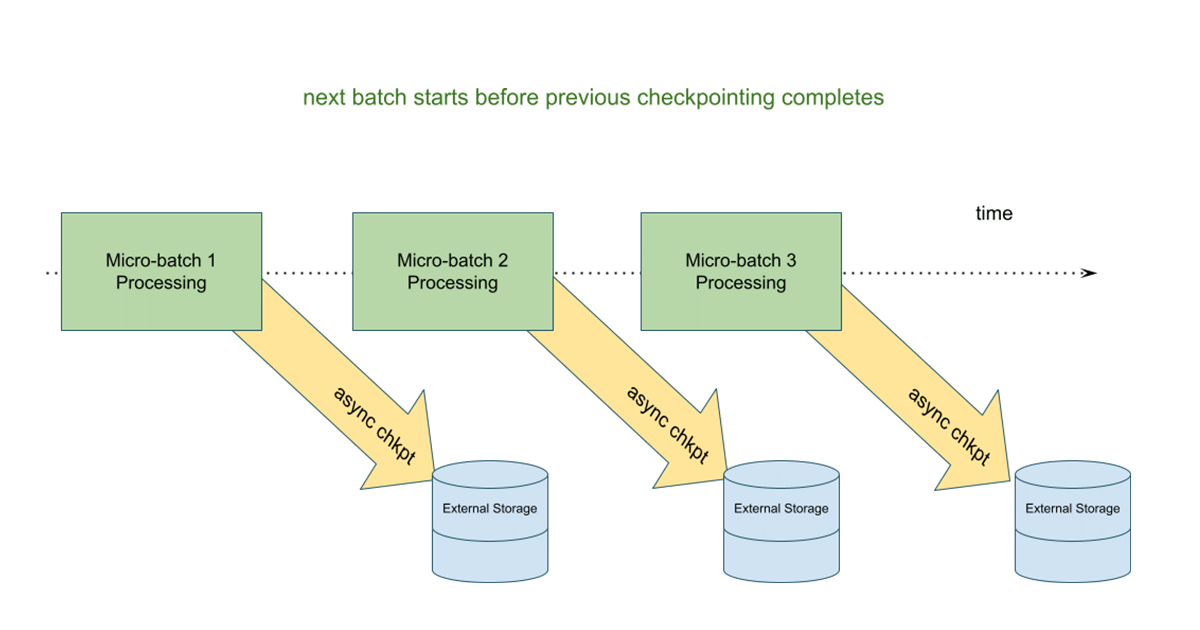
您可以在即将发布BOB低频彩的深入博客文章中了解有关此特性的更多信息,并在Databricks Runtime 10.3及更高版本中尝试使用它。
在很大程度上之前的帖子,我们通过[flat]MapGroupsWithState引入了结构化流中的任意状态处理。这些操作符提供了很大的灵活性,并支持聚合以外的更高级的有状态操作。我们对这些操作符进行了改进:
让我们从以下flatMapGroupswithState操作符开始:
定义flatMapGroupsWithStateU:编码器)(outputMode: outputMode,timeoutConf: GroupStateTimeout,initialState: KeyValueGroupedDataset[K, S])(函数:(K,迭代器[V], GroupState[S]) = >迭代器(U))这个自定义状态函数维护已遇到水果的运行计数。
val fruitCountFunc =(关键:字符串,值:迭代器[字符串,状态:GroupState[RunningCount]) = >{val count = state.getOption.map(_.count).getOrElse(0L) + valList.sizestate.update (新RunningCount(计数)迭代器(关键,count.toString))}在这个例子中,我们通过为某些水果设置起始值来指定this操作符的初始状态:
val fruitCountInitialDS:数据集[(字符串, RunningCount)] = Seq((“苹果”,新RunningCount (1)),(“橙色”,新RunningCount (2)),(“芒果”,新RunningCount (5)),) .toDS ()val fruitCountInitial = initialState.groupByKey(x= >x._1) .mapValues (_._2)
fruitStream.groupByKey (x= >x).flatMapGroupsWithState(更新GroupStateTimeout。NoTimeout fruitCountInitial) (fruitCountFunc)您现在还可以使用TestGroupState API测试状态更新。
进口org.apache.spark.sql.streaming._进口org.apache.spark.api.java.Optional测验("flatMapGroupsWithState的状态更新函数"){varprevState = TestGroupState.create[UserStatus](optionalState = Optional.empty[用户状态],timeoutConf = GroupStateTimeout。EventTimeTimeout,batchProcessingTimeMs = 1LeventTimeWatermarkMs = Optional.of(1L),hasTimedOut =假)val标识:字符串=……val actions:迭代器[UserAction] =…
断言(prevState.hasUpdated !)
updateState(userId, actions, prevState)
断言(prevState.hasUpdated)
}你可以找到这些,以及更多的例子砖的文档.
结构化流介绍的能力基于事件时间的Windows上的聚合使用翻转或滑动窗口,两者都是固定长度的窗口。在Spark 3.2中,我们引入了的概念会话窗口,允许动态窗口长度。这在历史上需要使用flatMapGroupsWithState自定义状态操作符。
一个使用动态间隙的例子:
#定义会话窗口有动态间隙持续时间在eventTypesession_window expr=session_window(事件。时间戳,\当(events.eventType=="type1", "5秒")\.当(events.eventType=="type2", "20秒")\.otherwise(5分钟)#集团的数据通过会话窗口而且用户标识,而且计算计数的每一个集团windowedCountsDF=事件\.withWatermark("timestamp", "10分钟")\.groupBy(事件。userID, session_window_expr) \.数()而StreamingQueryListenerAPI允许您异步监视SparkSession中的查询,并为查询状态、进度和终止事件定义自定义回调函数,了解反压力并推理微批处理中的瓶颈位置仍然具有挑战性。从Databricks Runtime 8.1开始,StreamingQueryProgress对象报告数据源特定的背压指标卡夫卡,运动,三角洲湖而且自动加载程序流源。
Kafka提供的指标示例:
{“源”: [{“描述”:“KafkaV2订阅(主题)”,“指标”: {“avgOffsetsBehindLatest”:“4.0”,“maxOffsetsBehindLatest”:“4”,“minOffsetsBehindLatest”:“4”,“estimatedTotalBytesBehindLatest”:“80.0”},})}Databricks Runtime 8.3引入了实时度量来帮助理解数据库的性能RocksDB状态存储并调试状态操作的性能。这些也有帮助确定目标工作负载对于异步检查点。
一个新的状态存储度量的例子:
{“id”:“6774075 e - 8869 - 454 b - ad51 - 513 be86cfd43”,“runId”:“3 d08104d-d1d4-4d1a-b21e-0b2e1fb871c5”,“batchId”:7,“stateOperators”: [{“numRowsTotal”:20000000,“numRowsUpdated”:20000000,“memoryUsedBytes”:31005397,“numRowsDroppedByWatermark”:0,“customMetrics”: {“rocksdbBytesCopied”:141037747,“rocksdbCommitCheckpointLatency”:2,“rocksdbCommitCompactLatency”:22061,“rocksdbCommitFileSyncLatencyMs”:1710,“rocksdbCommitFlushLatency”:19032,“rocksdbCommitPauseLatency”:0,“rocksdbCommitWriteBatchLatency”:56155,“rocksdbFilesCopied”:2,“rocksdbFilesReused”:0,“rocksdbGetCount”:40000000,“rocksdbGetLatency”:21834,“rocksdbPutCount”:1,“rocksdbPutLatency”:56155599000,“rocksdbReadBlockCacheHitCount”:1988,“rocksdbReadBlockCacheMissCount”:40341617,“rocksdbSstFileSize”:141037747,“rocksdbTotalBytesReadByCompaction”:336853375,“rocksdbTotalBytesReadByGet”:680000000,“rocksdbTotalBytesReadThroughIterator”:0,“rocksdbTotalBytesWrittenByCompaction”:141037747,“rocksdbTotalBytesWrittenByPut”:740000012,“rocksdbTotalCompactionLatencyMs”:21949695000,“rocksdbWriterStallLatencyMs”:0,“rocksdbZipFileBytesUncompressed”:7038}}),“源”: [{}),“沉”: {}}在去年的数据+人工智能峰会上,我们宣布Delta活动表,这是一个允许您以声明方式构建和编排数据管道的框架,并在很大程度上抽象了配置集群和节点类型的需求。我们更进一步,为流媒体管道引入了一种智能自动伸缩解决方案,改进了现有的流媒体管道优化的自动缩放.这些好处包括:
新算法利用新的背压指标来调整集群大小,以更好地处理流工作负载波动的场景,这最终会导致更好的集群利用率。
现有的自动伸缩解决方案仅在节点空闲时才会让它们退役,而新的DLT自动缩放程序将在利用率低时主动关闭选定的节点,同时保证不会因关闭而导致任务失败。
在撰写本文时,此功能目前正在进行私人预览.请联系您的客户团队了解更多信息。
在结构化流中,触发器允许用户定义流查询数据处理的时间。这些触发类型可以是微批处理(默认)、固定间隔微批处理(触发器。ProcessingTime(“
Databricks运行时10.1介绍了一种新型触发器;触发器。AvailableNow,类似于Trigger。但是提供了更好的可伸缩性。像Trigger Once一样,所有可用的数据都将在查询停止之前被处理,但是是多个批次而不是一个批次。支持Delta Lake和Auto Loader流媒体源。
例子:
spark.readStream.format(“δ”).option(“maxFilesPerTrigger”,“1”).load (inputDir)之类.writeStream.触发(Trigger.AvailableNow)checkpointDir .option(“checkpointLocation”).开始()随着我们进入2022年,我们将继续加速结构化流媒体的创新,进一步提高性能,减少延迟,并实现新的令人兴奋的功能。请继续关注今年更多的信息!

