
自动化数字病理图像分析和机器学习数据砖


2020年1月31日 在工程的博客
技术进步在成像和新的有效的计算工具的可用性,数字病理舞台的中心在研究和诊断设置。整个幻灯片成像(WSI)一直在这种转变的中心,使我们能够迅速数字化病理幻灯片到高分辨率的图像。通过幻灯片立即共享和可分析的,WSI公司已经改进的再现性和加强教育和远程病理服务启用。
今天,整个幻灯片在高分辨率的数字化可能发生以不到一分钟。因此,越来越多的卫生保健和生命科学组织获得大规模数字化幻灯片的目录。这些大型数据集可以用来构建自动化与机器学习诊断,可以将幻灯片或者段划分为表达一个特定的表型,或直接从幻灯片中提取定量生物标志物。与机器学习的力量和深度学习成千上万的数字幻灯片可以解释在几分钟内。这提出了一个巨大的机会,改善病理部门的效率和有效性,临床医生和研究人员诊断和治疗癌症和传染病。
3共同挑战防止更广泛的采用数字病理工作流
虽然许多卫生保健和生命科学组织认识到人工智能应用的潜在影响整个幻灯片图像,实现一个自动滑动分析管道仍是复杂的。一个操作WSI管道必须能够经常处理高吞吐量的数字化仪幻灯片以较低的成本。我们看到三个共同挑战阻止组织实施自动化数字病理工作流支持数据科学:
- 缓慢而昂贵的数据摄取和工程管道:WSI图像通常是非常大的(通常是0.5每张幻灯片2 GB),需要广泛的图像预处理。
- 麻烦缩放深度学习tb的图片:培训深入学习模型在一个适当大小的数据集和数百名WSIs可以持续数天到数周在单个节点上。这些潜伏状态防止快速实验在大型数据集。虽然可以减少延迟并行深度学习工作负载跨多个节点,这是一个先进技术的一个典型的生物数据的科学家。
- 确保WSI工作流的再现性:小说的见解时根据患者数据,是非常重要的能够繁殖的结果。当前的解决方案大多是特别的和不允许高效的方式跟踪实验和版本的数据中使用机器学习模型的训练。
在这个博客,我们将讨论如何使用砖统一数据分析平台应对这些挑战和部署一个端到端的可伸缩的深度学习工作流WSI图像数据。bob体育客户端下载我们将把重点放在一个工作流,火车一个图像分割模型,识别区域转移的幻灯片。在这个例子中,我们将使用Apache火花并行化数据准备在我们收集的图片,使用基于pre-trained熊猫UDF来提取特征模型(转移学习)在许多节点,和MLflow可再生产地追踪我们的模型训练。
WSI公司端到端机器学习
为了演示如何使用砖平台加速WSI公司数据处理管道,我们将使用bob体育客户端下载Camelyon16挑战赛数据集。这是一个开放400全部幻灯片图像的数据集TIFF格式从乳腺癌组织来演示我们的工作流。Camelyon16数据集的一个子集可以直接从砖下的访问/ databricks-datasets / med-images / Camelyon16 / (AWS|Azure)。训练一个图像分类器来检测地区包含癌症转移的幻灯片,我们将执行以下三个步骤,如图1所示:
- 一代补丁:使用坐标标注的病理学家,我们作物图像陷入同样大小的补丁。每个图像能产生成千上万的补丁,并贴上肿瘤或正常。
- 深度学习:我们使用转移学习使用pre-trained模型从图像中提取特征补丁,然后使用Apache火花来训练一个二进制分类器预测肿瘤与正常的补丁。
- 得分:然后我们使用训练模型,记录使用MLflow项目对一个给定概率热图幻灯片。
类似于工作流人类长寿用来预处理放射学图像,我们将使用Apache火花来操纵我们的幻灯片和注释。模型训练中,我们将首先使用pre-trained提取特征InceptionV3从Keras模型。为此,我们利用熊猫udf并行化特征提取。关于这种技术的更多信息参见Featurization转移学习(AWS|Azure)。注意,这种技术并不是特定于InceptionV3和可以应用于其他pre-trained模型。
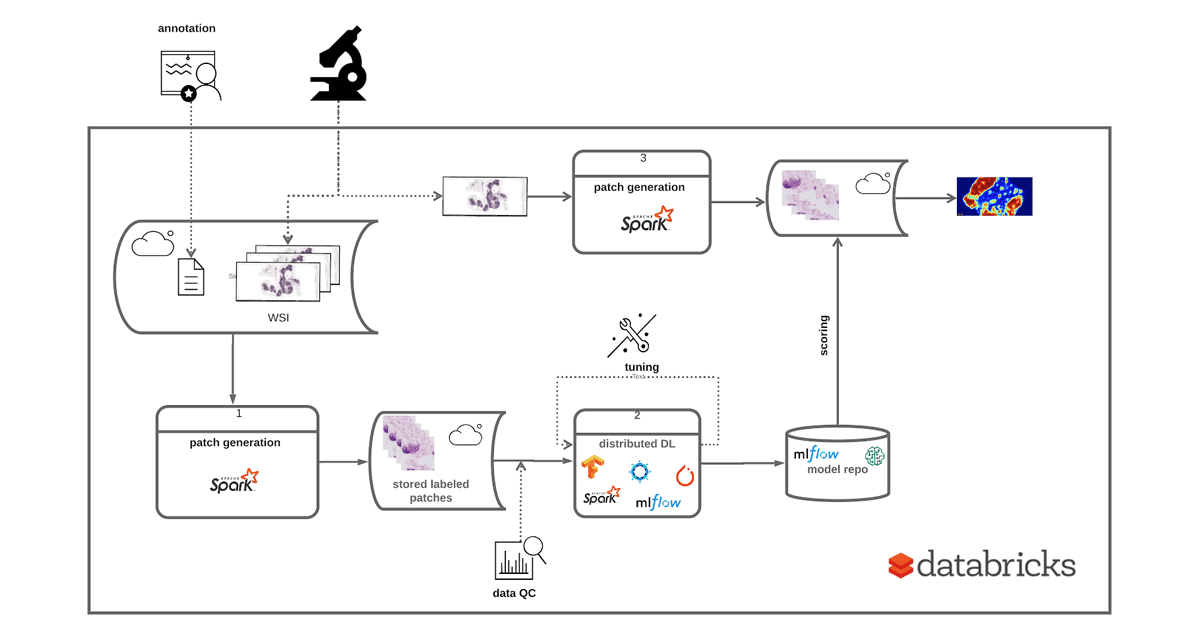
图1:实现端到端解决方案培训和部署基于WSI DL模型数据
图像预处理和ETL
使用开源工具bob下载地址等自动滑动分析平台bob体育客户端下载,病理学家可以导航WSI在非常高的分辨率和注释图像幻灯片标记临床相关的网站。注释可以保存为一个XML文件,与多边形的边缘的坐标包含网站和其他信息,如缩放级别。训练模型,使用注释的地面实况幻灯片,我们需要加载的每个图像注释区域,这些地区加入与我们的图片,并切除带注释的地区。一旦我们完成了这一过程,我们可以使用我们机器学习的图像补丁。
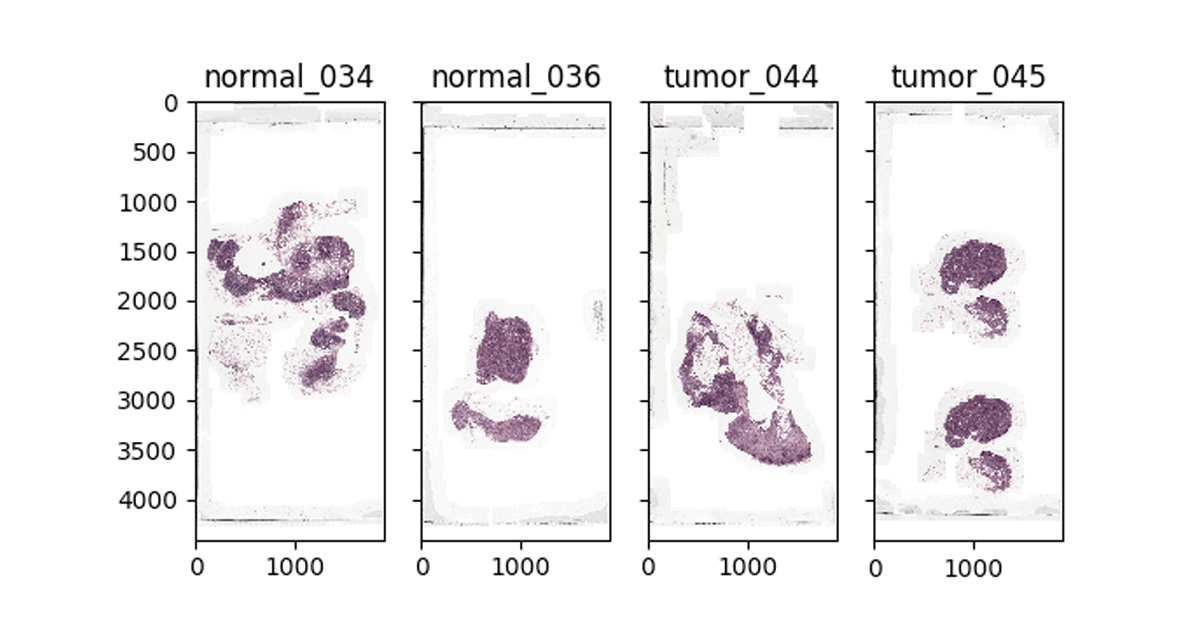
图2:WSI可视化图像数据砖笔记本
虽然这个工作流通常使用注释存储在一个XML文件中,为简单起见,我们使用的预处理注释百度的研究团队,建立了NCRF Camelyon16数据集分类器。这些注释存储CSV编码的文本文件,Apache火花将会被加载进DataFrame。在下面的笔记本电池,我们装载注释对肿瘤和正常的补丁,并分配标签0到正常片和1肿瘤切片。然后,我们到单个DataFrame工会的坐标和标签。
虽然许多基于sql的系统限制你内置操作,Apache火花有丰富的支持用户定义函数(udf)。udf允许您调用一个定制的Scala, Java、Python或R函数对数据在任何Apache DataFrame火花。在我们的工作流程中,我们将定义一个Python UDF使用OpenSlide图书馆从一个图像特许权给定的补丁。我们定义了一个python函数需要处理WSI公司的名称,补丁的X和Y坐标中心,和标签的补丁并创建瓷砖后将用于培训。
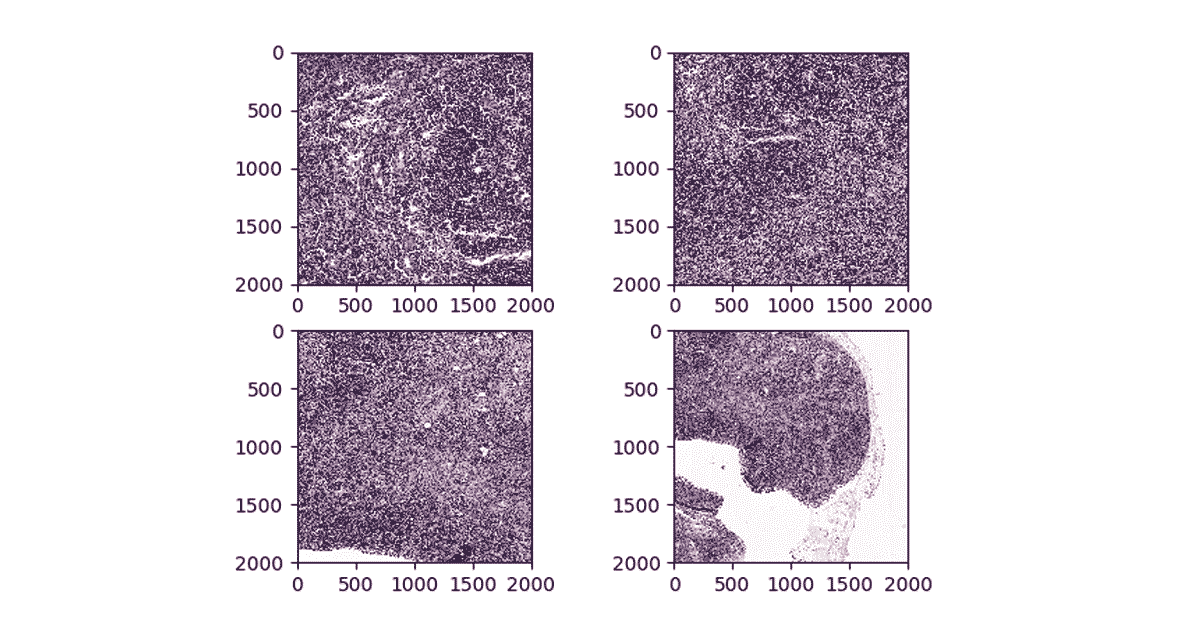
图3。在不同的缩放级别可视化补丁
然后我们使用OpenSlide库载入图像云存储,并切出给定坐标范围。虽然OpenSlide本身并不了解如何读取数据Amazon S3或Azure湖数据存储,砖文件系统(DBFS)融合层允许OpenSlide直接访问数据存储在这些blob存储没有任何复杂的代码更改。最后,我们的函数编写补丁使用DBFS融合层。
这个命令生成需要大约10分钟~ 174000补丁Camelyon16砖数据集的数据集。一旦我们的命令已经完成,我们可以加载补丁备份和显示他们直接嵌套在我们的笔记本。
正常训练肿瘤/病理学分类器使用学习和MLFlow转移
在前面的步骤中,我们生成补丁和相关的元数据,并使用云存储存储生成的图像块。现在,我们已经准备好训练二元分类器预测一段幻灯片是否包含一个肿瘤转移。要做到这一点,我们将使用学习转移到从每个补丁使用pre-trained深度提取特征神经网络然后使用sparkml分类任务。这种技术常常优于从头训练对于许多图像处理应用程序。我们将开始与InceptionV3架构,使用从Keras pre-trained权重。
Apache火花的DataFrames提供一个内置的图像模式,我们可以直接加载所有补丁DataFrame。然后使用熊猫udf将图像转换为功能基于使用Keras InceptionV3。一旦我们featurized每个图像,我们使用spark.ml以适应之间的逻辑回归特性和每个补丁的标签。我们与MLFlow日志逻辑回归模型,这样我们以后可以访问模型服务。
砖上毫升工作流运行时,用户可以利用MLFlow管理。用的笔记本和每一次的培训,MLFlow自动日志参数,指标和任何指定的工件。此外,它存储的训练模型后可以用于预测标签数据。我们感兴趣的读者参考这些文档要更多地了解如何利用MLFlow管理完整的砖的ML工作流。
表1显示了时间的不同部分的工作流程。我们注意到,模型训练~ 170 k样本只需要不到25分钟的准确性达87%。
| 工作流 | 时间 |
| 补丁的一代 | 10分钟 |
| 工程特点和培训 | 25分钟 |
| 得分(每个单张幻灯片) | 15秒 |
表1:运行时不同的工作流步骤使用2 - 10 r4.4xlarge工人使用砖毫升6.2运行时,从幻灯片中提取包含在databricks-datasets 170000补丁
因为可以有更多的补丁在实践中,使用深层神经网络可以显著提高分类精度。在这种情况下,我们可以使用分布式训练技巧培训规模的过程。在砖平台上,我们打包了bob体育客户端下载HorovodRunner工具箱,将培训任务分布在大型集群很小对ML代码的修改。这篇博客提供了一个很好的背景如何规模毫升工作流砖。
推理
现在我们已经训练分类器,我们将使用分类器项目的转移概率的热图幻灯片。要做到这一点,首先,我们应用一个网格在感兴趣的领域在幻灯片上然后我们生成patches-similar训练程序中获得数据到火花DataFrame可用于预测。然后我们使用MLflow加载训练模型,它们可以应用作为转换的DdataFframe计算预测。
重建图像,我们使用python的公益诉讼库修改每个瓷砖颜色根据包含的概率转移网站和补丁一起瓷砖。下面的图4显示了结果的概率预测肿瘤的一个部分。请注意,红色代表的密度高概率转移在幻灯片上。
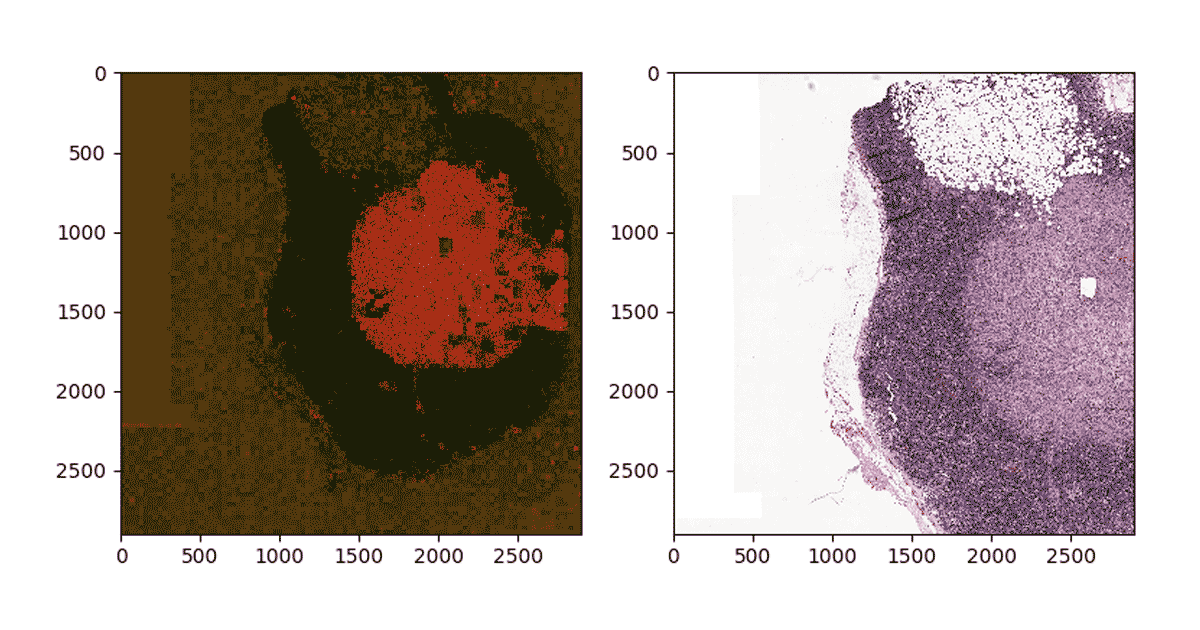
图4:WSI的预测映射到一个给定的部分
开始使用机器学习在病理图像
在这个博客中,我们展示了砖连同火花的SQL, SparkML MLflow,可以用来构建一个可扩展的和可再生的机器学习框架病理图像。更具体地说,我们使用大规模转移学习训练分类器预测概率一段幻灯片包含肿瘤细胞,然后用训练模型检测和地图癌生长在一个给定的幻灯片。