



新砖为Jupyter桥梁集成本地和远程的工作流
2019年12月3日
通过Bernhard沃尔特
在
工程的博客
介绍许多年了,数据科学家开发出特定的工作流前提使用本地文件系统层次结构,源代码修改系统和CI / CD……
2019年12月3日 在工程的博客
多年以来,数据科学家开发出具体的工作流前提使用本地文件系统层次结构,源代码修改系统和CI / CD流程。
另一方面,可用的数据呈指数级增长和新功能需要进行数据分析和建模,例如,轻易可伸缩的存储、分布式计算等新技术系统或特殊硬件gpu深度学习。
这些功能是很难提供在一个灵活的前提。所以企业越来越多的利用云解决方案和数据科学家们挑战结合当地现有的工作流与这些新的基于云的能力。
这个项目JupyterLab集成发表在砖实验室,这两个世界的桥梁。数据科学家可以利用他们熟悉当地环境和JupyterLab工作与远程数据和远程集群只需选择一个内核。
示例场景通过从当地JupyterLab JupyterLab集成:
这篇文章从一个快速概述如何使用远程数据砖集群从当地JupyterLab样子。然后提供一个端到端处理JupyterLab集成的例子解释的差异砖连接。如果你想试一试自己,最后一节解释了安装。
JupyterLab集成遵循Jupyter / JupyterLab的标准方法和允许您创建Jupyter内核为远程数据砖集群(这在下一节中解释)。工作与你开始JupyterLab JupyterLab集成标准命令:
美元jupyter实验室在笔记本上,从菜单中选择远程内核连接到远程砖集群和火花的会话与Python代码如下:
从databrickslabs_jupyterlab.connect进口dbcontextdbcontext ()下面的视频展示了这个过程的一些特点JupyterLab集成。
https://www.youtube.com/watch?v=VUqA8hp9bnk
集群配置数据砖JupyterLab集成之前,让我们了解如何识别:砖集群运行在云砖数据科学的工作区。这些工作可以从本地终端的维护砖CLI。砖CLI存储URL和个人访问令牌在本地工作区配置文件在一个可选择的配置文件名。JupyterLab集成使用这个配置文件名称来引用数据砖工作区,e。g演示工作区demo.cloud.www.neidfyre.com。
假设JupyterLab集成已经安装和配置镜像远程集群命名bernhard - 5.5毫升(安装在这篇博客的详细信息)。
第一步是创建一个内核Jupyter规范远程集群,例如在工作区配置文件名演示:
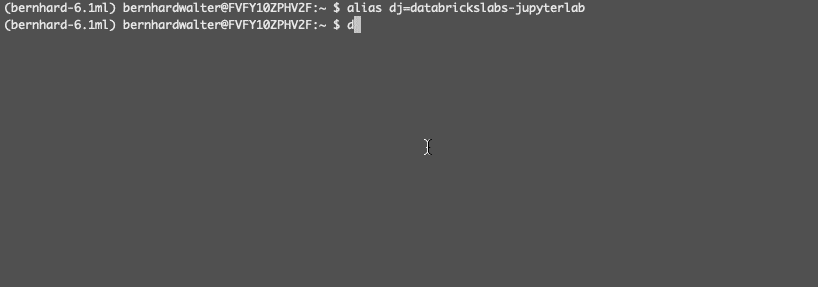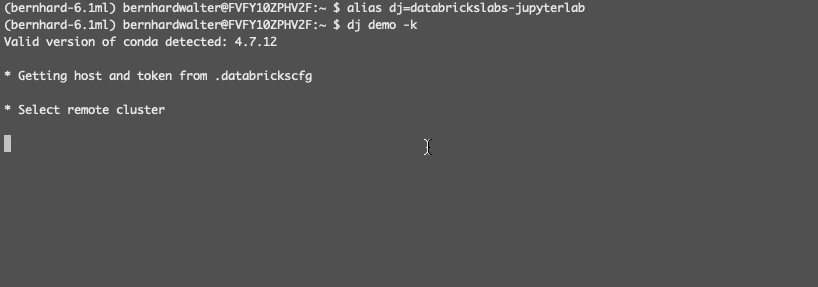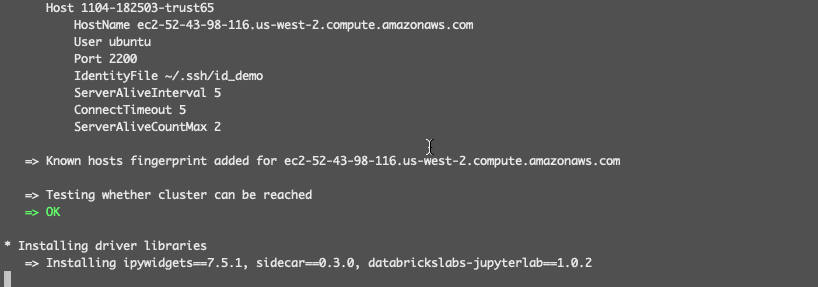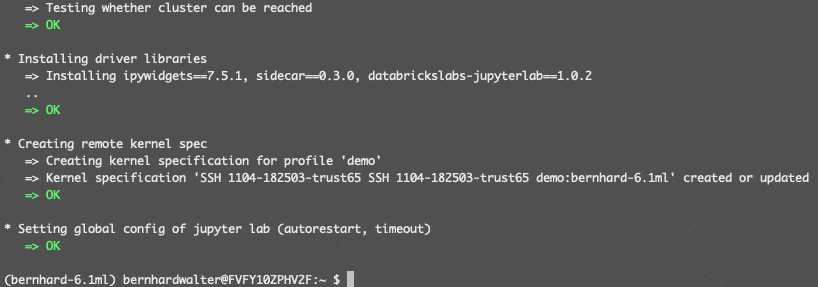
(bernhard - 6.1毫升)别名dj = databrickslabs-jupyterlab美元(bernhard - 6.1毫升)dj演示- k美元以下向导允许您选择工作区中的远程集群演示时,司机IP地址存储在本地ssh配置文件和安装一些必要的运行时库在远程司机:
结束时,一个新的内核SSH 1104 - 182503 trust65演示:bernhard - 6.1毫升可用在JupyterLab(远程集群id的名称是一个组合1104 - 182503 trust65砖CLI配置文件名演示,远程集群名称bernhard - 6.1毫升,选择当地conda环境名称)。
现在我们有两个选择JupyterLab开始,第一个通常的方式:
(bernhard - 6.1毫升)美元jupyter实验室这将工作完美,当远程集群已经启动并运行及其本地配置是最新的。然而,首选的方式开始JupyterLab JupyterLab集成
美元(bernhard - 6.1毫升)dj演示- l - c这个命令将自动启动远程集群(如果终止),安装运行时库“ipykernel”和“ipywidgets”司机和保存远程本地司机的IP地址。作为一个副作用,国旗- c的个人访问令牌自动复制到剪贴板。你需要笔记本的令牌在下一步来验证远程集群。重要的是要注意,个人访问令牌将不会存储在远程集群。
创建一个火花会话的Jupyter笔记本连接到这个远程内核,输入以下两行成一个笔记本电池:
从databrickslabs_jupyterlab.connect进口dbcontext, is_remotedbcontext ()这将要求输入个人访问令牌(上面是复制到剪贴板),然后将笔记本电脑连接到远程火花上下文。
下面的代码将运行在本地Python内核和远程数据砖内核。在本地运行,它将使用GridSearchCVscikit-learn小hyperparameter空间。远程数据砖内核上运行,它将杠杆spark-sklearn在火花执行人分发hyperparameter优化。对本地和远程环境不同的设置(如数据路径),函数is_remote()可以使用从JupyterLab集成。
如果is_remote ():从functools进口部分从spark_sklearn进口GridSearchCVGridSearchCV =部分(GridSearchCV, sc)#添加火花上下文data_path =“/ dbfs / bernhard / digits.csv”其他的:从sklearn.model_selection进口GridSearchCVdata_path = (“/用户/ bernhardwalter /数据/数字/ digits.csv”)进口熊猫作为pd数字= pd。read_csv (data_path index_col =没有一个)X, y = digits.iloc [:,1:-1],digits.iloc [:,1]从sklearn.ensemble进口RandomForestClassifier如果is_remote ():param_grid = {“max_depth”:【3,5,10,15),“max_features”:【“汽车”,“√”,“log2”,没有一个),“min_samples_split”:【2,5,10),“min_samples_leaf”:【1,3,10),“n_estimators”:【10,15,25,50,75年,One hundred.]}# 864的选项其他的:param_grid = {“max_depth”:【3,没有一个),“max_features”:【1,3),“min_samples_split”:【2,10),“min_samples_leaf”:【1,10),“n_estimators”:【10,20.]}# 32选项简历= GridSearchCV (RandomForestClassifier ()、param_grid简历=3)cv.fit (X, y)最好= cv.best_index_cv_results = cv.cv_results_打印(“mean_test_score”,cv_results [“mean_test_score”(最好的),“std_test_score”,cv_results [“std_test_score”最好][])cv_results [“参数”)(最好的)下面是一个视频演示对本地和远程运行:
https://www.youtube.com/watch?v=Dih6RcYS7as
砖连接允许你连接你最喜欢的IDE,笔记本电脑服务器和其他自定义应用程序数据砖集群。它提供了一个特殊的地方引发环境基本上是一个代理到远程火花上下文。只有火花将远程集群上执行代码。这意味着,例如,如果你开始一个GPU节点在砖一些深度学习的实验中,与砖连接您的代码将在笔记本电脑上运行,不会利用GPU的远程机器:
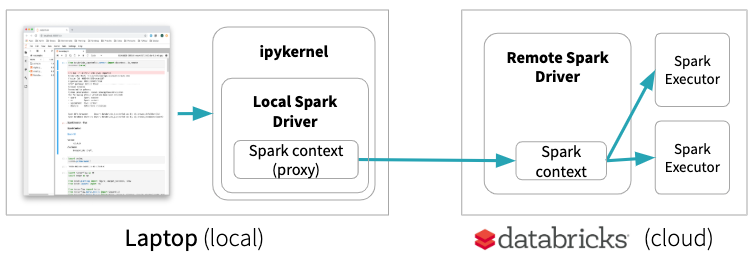
JupyterLab集成,另一方面,使笔记本电脑本地但远程集群上运行所有代码如果远程内核被选中。这使得当地JupyterLab运行单独的节点数据科学笔记本(使用熊猫,scikit-learn等)在远程环境由砖或运行维护您的深度学习远程砖GPU的机器上的代码⓶。
你当地JupyterLab也可以执行分布式火花工作砖集群⓵进度条提供火花的状态工作。
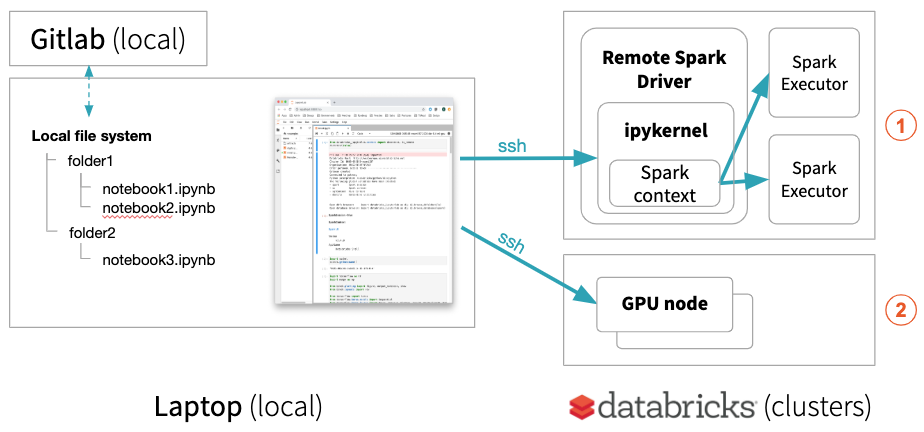
此外,您可以设置本地conda环境镜子远程集群。你可以在本地建立了你的实验,你有完全控制您的环境,流程和容易接近所有的日志文件。当代码是稳定的,可以使用远程集群应用到完整的远程数据集或远程集群上进行分布式hyperparameter优化与每次运行没有上传数据。
注意:如果一个笔记本是连接到一个远程集群,其Python内核运行在远程集群和本地配置文件和本地数据可以通过Python和火花。当地的笔记本电脑和DBFS之间交换文件在远程集群,使用砖CLI来回复制数据:
美元砖——概要美元的概要文件fs cp /数据/ abc。csv dbfs: /数据因为例如熊猫不能访问文件通过DBFS DBFS: /,有一个挂载点/ DBFS /允许访问数据DBFS(如/ DBFS /数据/ abc.csv) Python标准库。
之后,我们已经看到了JupyterLab集成的作品,让我们来看看如何安装它。
JupyterLab集成将竞选砖AWS和Azure砖。的设置是基于砖CLI的配置和假设:
注:目前只有MacOS和Linux上运行和测试数据砖运行时5.5,6.0和6.1(标准和ML)。

公约是SSH密钥对的名称命名的砖CLI配置文件名。的先决条件的更多细节,请参阅“先决条件”部分的文档。
(基地)conda美元创建- - - - - -n db- - - - - -jlab python=3.6(基地)美元conda激活数据库- - - - - -jlab(db- - - - - -jlab)美元pip安装——升级databrickslabs-jupyterlab前缀(db-jlab)美元在这篇博文显示命令的例子conda环境db-jlab被激活。
终端命令名databrickslabs-jupyterlab很长,所以让我们创建一个别名
(db-jlab)别名dj = databrickslabs-jupyterlab美元(db-jlab) dj - b美元(db-jlab)美元dj美元的概要文件- m在这篇文章里,我们展示了如何JupyterLab一体化集成了远程数据砖集群到本地建立工作流运行Python砖集群通过ssh的内核。这允许数据科学家在他们的工作熟悉当地环境与JupyterLab和访问远程数据和远程集群以一致的方式。我们已经表明,JupyterLab集成遵循不同的方法砖使用ssh连接。科学工作区和砖砖数据连接相比,这使得一组额外的用例。
https://github.com/databrickslabs/Jupyterlab-Integration