
使用AutoML工具包的FamilyRunner管道api来简化和自动化贷款违约预测



介绍
在《华盛顿邮报》使用AutoML工具箱自动化贷款违约预测,我们已经展示了如何砖实验室的AutoML工具包简化的机器学习模型特性工程和模型建立优化(MBO)。它也提高了曲线下的面积(AUC)从0.6732(手工XGBoost模型)到0.723 (AutoML XGBoost模型)。AutoML工具包的释放0.6.1,我们已经升级到MLflow版本1.3.0并介绍了一个新的管道API,简化了特征生成和推理。
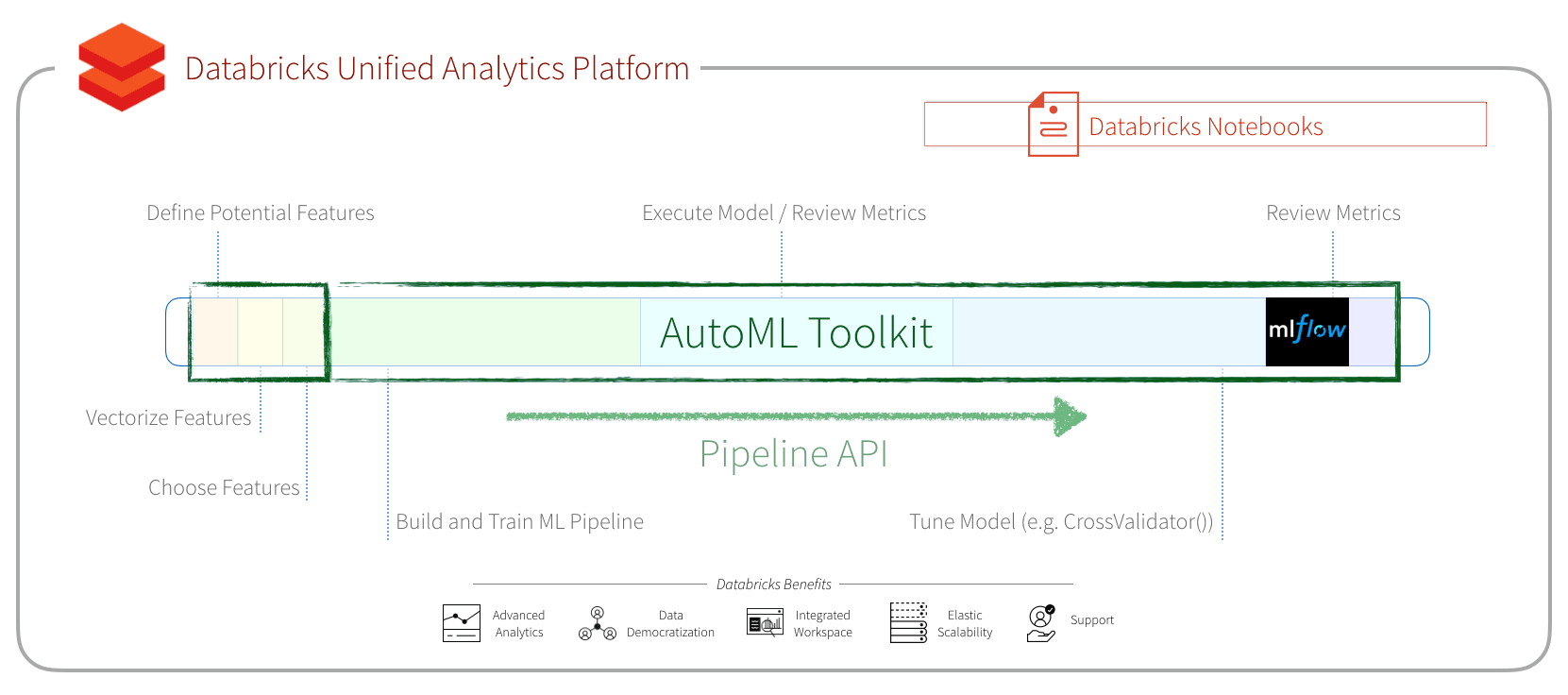
在这篇文章中,我们将讨论:
- 家庭跑步API,使您可以轻松地尝试不同的家庭模式确定最佳模型
- 简化推理与管道API
- 简化API特性与管道工程
都是在家庭中……跑
原文中提到贷款风险分析与XGBoost砖运行时机器学习,我们试过三个不同的模型:家庭的漠视,GBT, XGBoost。没有深入了解,这由数百行代码为每个模型类型。

正如使用AutoML工具箱自动化贷款违约预测,我们降低了这几行代码为每个模型类型。AutoML工具包FamilyRunner API,我们简化这进一步通过允许您使用它来运行多个并发模型类型分布在集群的节点数据砖。以下是所需的三行代码运行两个模型(逻辑回归和XGBoost)。
val xgBoostConfig = ConfigurationGenerator.generateConfigFromMap (“XGBoost”,“分类”xgBoostOverrides)val logisticRegressionConfig = ConfigurationGenerator.generateConfigFromMap (“LogisticRegression”,“分类”logisticRegOverrides)val跑= FamilyRunner (datasetTrain,数组(xgBoostConfig logisticRegressionConfig)) .executeWithPipeline ()细胞内输出的代码片段中,您可以观察FamilyRunner API执行多个任务,每个努力寻找最好的hyperparameters模型类型的选择。
= = = AutoML管道阶段:类com。砖。实验室。automl。管道。MlFlowLoggingValidationStageTransformer日志= = >艺名:MlFlowLoggingValidationStageTransformer_18aeadd79de9总执行时间阶段:194年女士Params阶段:{automlInternalId:automl_internal_id,isDebugEnabled:真正的,mlFlowAPIToken(修订):,mlFlowExperimentName:/用户/(电子邮件保护)/ AutoML / Jas_AutoML_Demo / runXG_1,mlFlowLoggingFlag:真正的,mlFlowTrackingURIhttps:/ / demo.cloud.www.neidfyre.com,pipelineId: 290 b3c8d - 8 dbc - 4 - b1b a9da ec602——8807153}输入数据集数:547821年输出数据集计数:547821年…AutoML工具包的释放0.6.1,我们已经升级到使用最新版本的MLflow (1.3.0)。下面的视频展示了结果AutoML FamilyRunner MLflow内实验记录允许您比较逻辑回归模型的结果(AUC = 0.716)和XGBoost (AUC = 0.72)。
https://www.youtube.com/watch?v=3mgLronGsdI
简化推理与管道API
管道在FamilyRunner api允许运行的功能使用一个MLflow运行ID或推理PipelineModel对象。这些管道包含一系列的阶段,直接由AutoML的主要配置。通过运行推理其中一个方面,它确保预测数据集经过相同的一组特性工程步骤,用于培训。这使得完全控制、便携和可串行化的管道,可以导出,对独立的需求,而不需要手动应用特性的工程任务。下面的代码提供了运行一个推理的一个片段。
使用MLflow运行ID
当你用MLFlow AutoML运行时,您可以运行推理仅仅通过使用MLFlow运行ID (MLFlow配置),正如下面的代码片段。
val bestMlFlowRunId = runner.bestMlFlowRunId (“XGBoost”)val bestPipelineModel = PipelineModelInference。getPipelineModelByMlFlowRunId (bestMlFlowRunId xgBoostConfig.loggingConfig)val inferredDf = bestPipelineModel.transform (datasetValid)作为细胞的输出中可以看到,AutoML管道API执行所有训练数据创建的最初阶段,现在应用于验证数据集。在这个例子中,下面是删减管道API细胞显示输出阶段执行。
= = = AutoML管道阶段:类com。砖。实验室。automl。管道。ZipRegisterTempTransformer日志= = >艺名:ZipRegisterTempTransformer_a88351e04577总执行时间阶段:57女士…= = = AutoML管道阶段:类com。砖。实验室。automl。管道。MlFlowLoggingValidationStageTransformer日志= = >艺名:MlFlowLoggingValidationStageTransformer_18aeadd79de9总执行时间阶段:233年女士…= = = AutoML管道阶段:类com。砖。实验室。automl。管道。CardinalityLimitColumnPrunerTransformer日志= = >艺名:CardinalityLimitColumnPrunerTransformer_e8aede7e3f4d总执行时间阶段:1女士…= = = AutoML管道阶段:类com。砖。实验室。automl。管道。DateFieldTransformer日志= = >艺名:DateFieldTransformer_5ec5e2680828总执行时间阶段:7女士…
= = = AutoML管道阶段:类com。砖。实验室。automl。管道。DropColumnsTransformer日志= = >艺名:DropColumnsTransformer_1859c7895f19总执行时间阶段:4女士…= = = AutoML管道阶段:类com。砖。实验室。automl。管道。ColumnNameTransformer日志= = >艺名:ColumnNameTransformer_d727a713897e总执行时间阶段:3女士…= = = AutoML管道阶段:类com。砖。实验室。automl。管道。DropColumnsTransformer日志= = >艺名:DropColumnsTransformer_a3160a31ec07总执行时间阶段:3女士…= = = AutoML管道阶段:类com。砖。实验室。automl。管道。DataSanitizerTransformer日志= = >艺名:DataSanitizerTransformer_a9866eaba0de总执行时间阶段:1.79秒…= = = AutoML管道阶段:类com。砖。实验室。automl。管道。VarianceFilterTransformer日志= = >艺名:VarianceFilterTransformer_63da1ccb67fe总执行时间阶段:4女士…= = = AutoML管道阶段:类com。砖。实验室。automl。管道。DropColumnsTransformer日志= = >艺名:DropColumnsTransformer_d239d19c60e6总执行时间阶段:12女士…= = = AutoML管道阶段:类com。砖。实验室。automl。管道。DropColumnsTransformer日志= = >艺名:DropColumnsTransformer_54010312beee总执行时间阶段:5女士…
bestPipelineModel: org.apache.spark.ml。PipelineModel= final_linted_infer_pipeline_25618e0d3e91inferredDf: org.apache.spark.sql。DataFrame =[术语:字符串,home_ownership:字符串…20.多个字段)正如前面的代码片段(扩大审查它),推断DataFrameinferredDf管道生成的API包含验证数据集包括预测计算(如下截图中指出)。
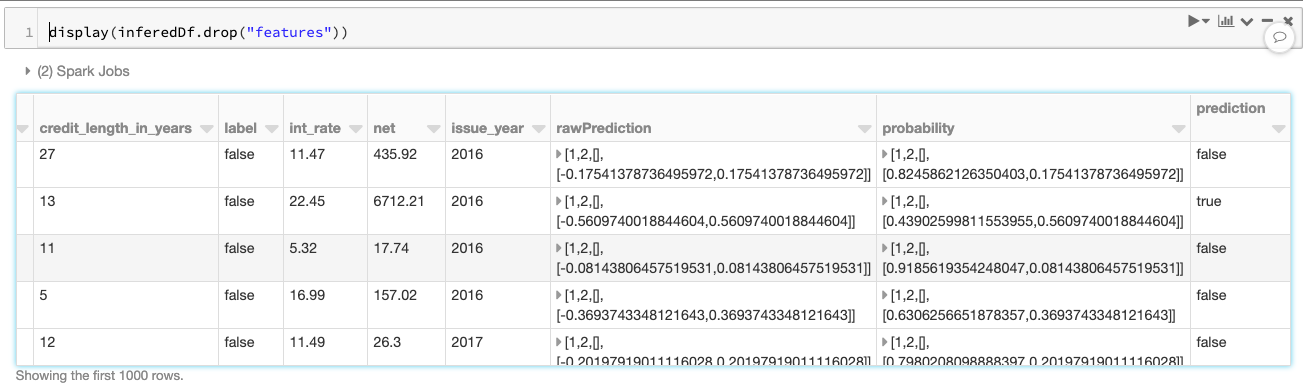
可以看到,只需要获取管道MLflow运行ID并运行一个推理。这是由于管道内部api日志所有工件在MLflow下运行一个实验项目。的笔记本使用AutoML工具包的FamilyRunner管道api来简化和自动化贷款违约预测进一步展示了所有的标签添加到MLflow运行。
使用PipelineModel手动保存和加载AutoML管道
即使没有启用MLflow, PipelineModel提供了灵活性,手动保存这些管道模型自定义路径下。
/ /保存它val pipelinePath =“tmp / predict-pipeline-lg-1”runner.bestPipelineModel (“LogisticRegression”).write.overwrite () .save (pipelinePath)/ /加载它val pipelineModel = PipelineModel.load (pipelinePath)val inferredDf = pipelineModel.transform (datasetValid)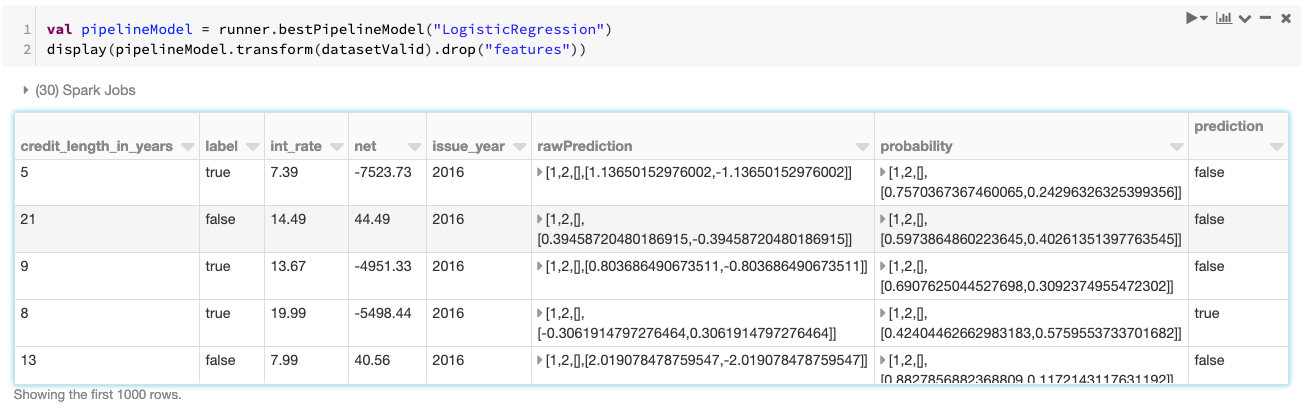
简化API特性与管道工程
除了完整的推理管道,FamilyRunner也公开API只运行特性工程步骤,没有执行特征选择和计算功能重要性。需要AutoML主要配置对象和转换成一个管道。这可以用于做工程数据分析功能,无需手动应用皮尔逊过滤器、协方差,离群值过滤器,基数限制等等。它使模型的使用,尚未AutoML工具包的一部分,但仍利用AutoML高级特性的工程阶段。
val featureEngPipelineModel = FamilyRunner (datasetTrain,数组(xgBoostConfig logisticRegressionConfig)) .generateFeatureEngineeredPipeline (verbose =真正的)(“XGBoost”)val featuredData = featureEngPipelineModel.transform (datasetTrain)显示器(featuredData)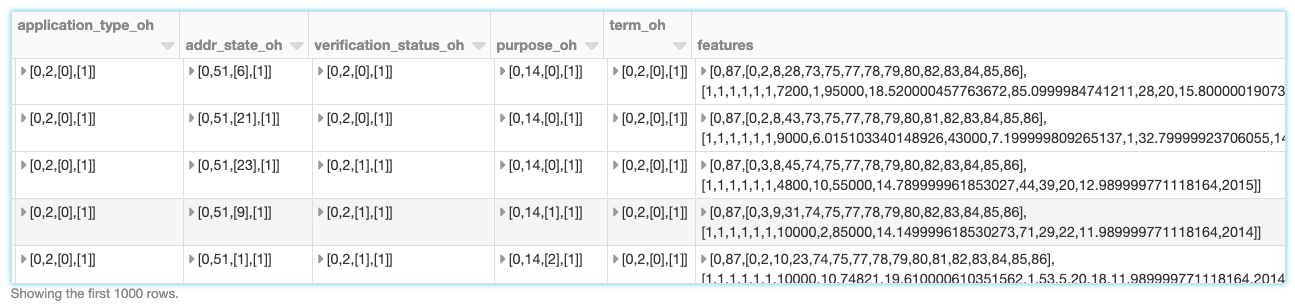
讨论
和家人跑API,您可以运行多个并发模型类型,找到最好的模型及其hyperparameters跨多个模型。AutoML工具包的释放0.6.1,我们已经升级到MLflow1.3.0并引入了一个新的管道API,大大简化了功能生成和推理。试AutoML工具包和使用AutoML工具包的FamilyRunner管道api来简化贷款风险分析今天笔记本!
贡献
我们想感谢肖恩·欧文,本·威尔逊布鲁克身上,姆Kovacevic这个博客为他们的贡献。