
使用AutoML工具箱自动化贷款违约预测



这篇文章最初发表于2019年9月10日;2019年10月2日,它已经更新。
在以前的博客和笔记本,与XGBoost贷款风险分析,我们探讨了如何构建一个机器学习的不同阶段的预测模型来提高不良贷款。我们回顾了三个不同的线性回归模型——漠视,GBT, XGBoost——执行耗时的手工优化模型在每个阶段的过程。
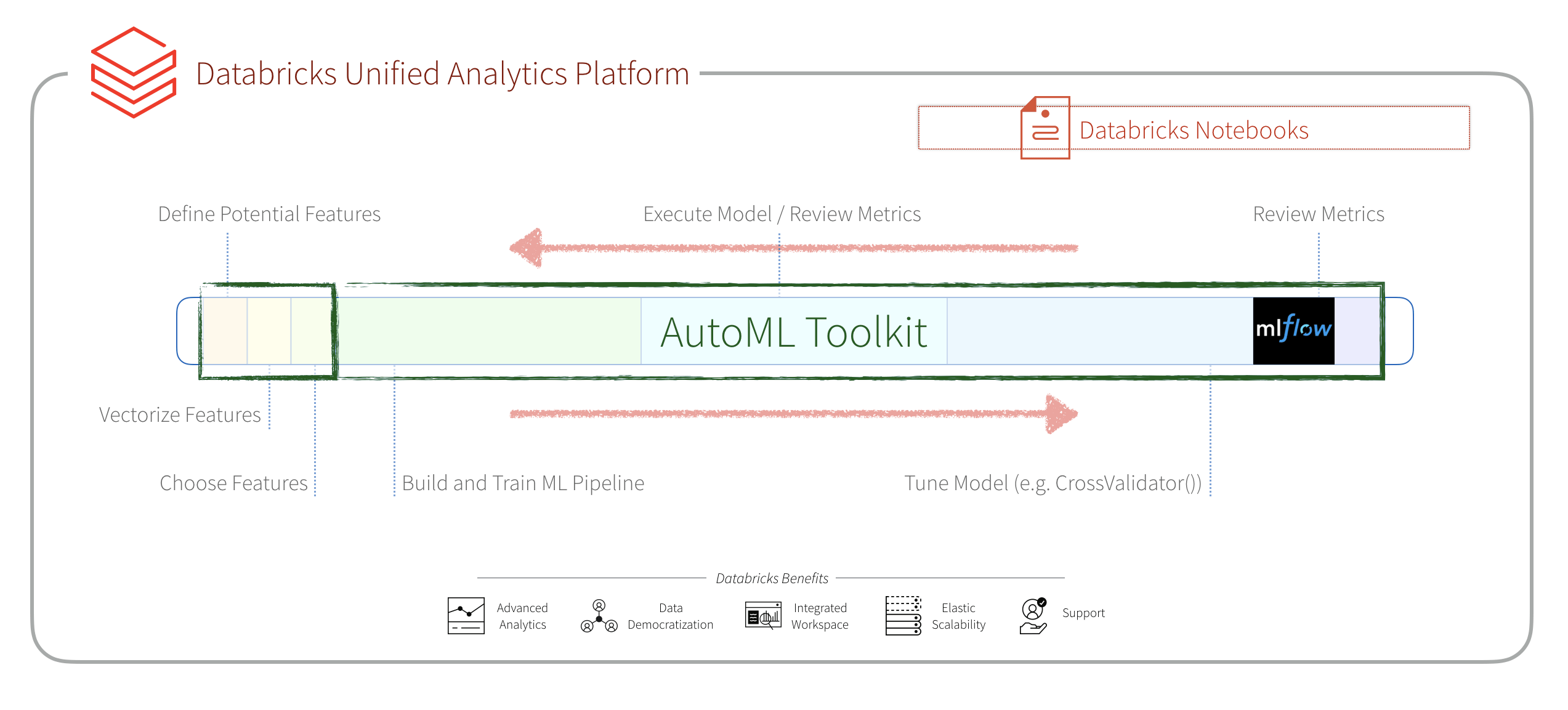
在这篇文章中,我们将展示如何大大简化流程建立,评估和优化利用机器学习模型砖实验室AutoML工具包。使用AutoML工具包也会让你更快地交付成果显著,因为它允许您自动各种机器学习管道阶段。你会观察到,我们将运行相同的贷款风险分析数据集使用XGBoost 0.90,看结果的AUC显著改善使用AutoML工具箱0.6732到0.72。的商业价值(节省的钱防止不良贷款),AutoML工具箱生成的模型可能会节省68.88美元(比23.22美元与原技术)。
这个问题是什么?
对于我们目前的实验中,我们将继续使用贷款俱乐部贷款数据。它包括所有资助贷款从2012年到2017年。每笔贷款包括申请人申请人所提供的信息以及贷款现状(目前,晚了,完全支付,等等)和最新的支付信息。
我们利用申请人信息来确定如果我们可以预测如果贷款是坏的。有关更多信息,请参考贷款风险分析与XGBoost砖运行时机器学习。
让我们开始与结束
的AutoML工具包提供了一种简便的方法来自动化机器学习中的各种任务。在我们的示例中,我们将使用两个组件:功能重要性和自动化跑自动化任务从vectorizing特性的迭代和调优一个机器学习模型。
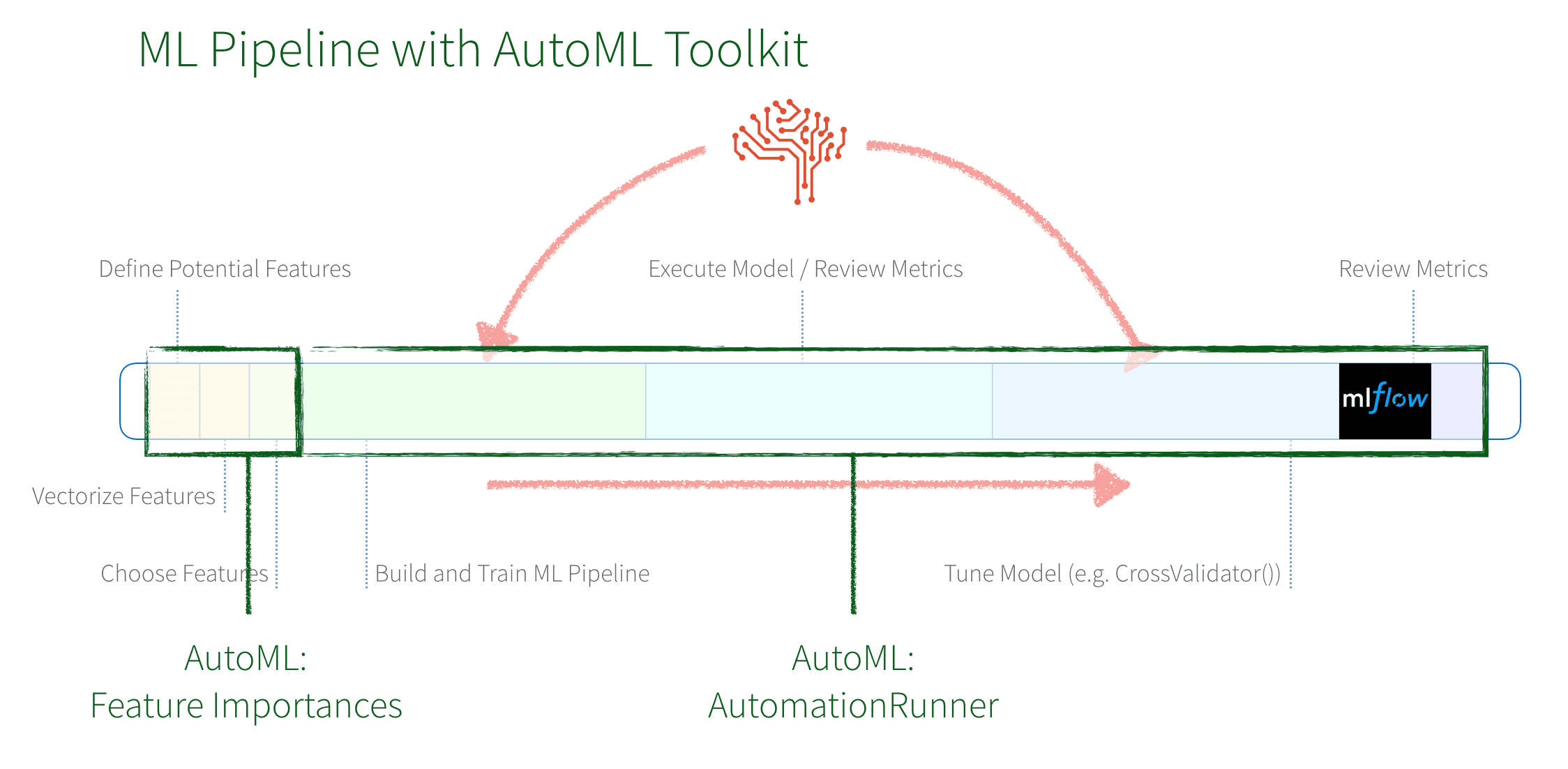
简而言之:
- AutoML的
FeatureImportances自动的发现这档节目的特点就是从数据集(列)很重要,应该包括在创建一个模型。 - AutoML的
AutomationRunner自动化建设、培训、执行、和调优的机器学习管道创造一个最佳的ML模式。
当我们有手动创建了一个新的每毫升模型贷款风险分析与XGBoost砖运行时机器学习使用XGBoost 0.90,我们能够改善AUC从0.6732到0.72 !
我错过了什么?
在传统ML管道,有许多手写组件执行的任务featurization和模型构建和调优。下图提供了这些阶段的图形表示形式。
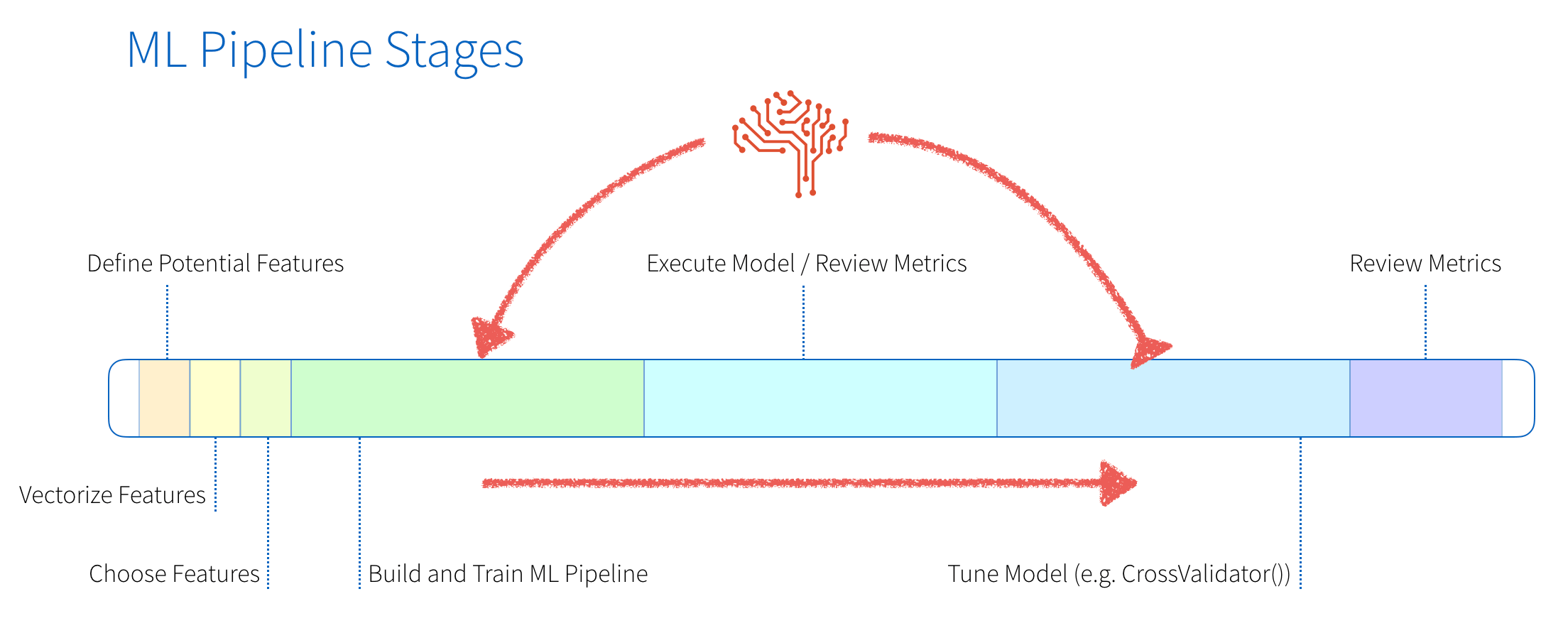
这些阶段包括:
- 工程特性:我们将首先定义潜在功能,vectorize他们(不同的数字和分类数据所需的步骤),然后选择我们将使用的特性。
- 模型建立和优化:这些是建筑的高度重复阶段和培训我们的模型,执行模型和评估指标,优化模型,对模型进行更改和重复这个过程直到最后构建我们的模型。
在接下来的几节中,我们将
- 描述代码提取和可视化这些步骤评估的风险贷款批准使用XGBoost (0.90)笔记本
- 说明这是使用更简单AutoML工具包如上所述的使用AutoML工具包来简化贷款风险分析XGBoost模型优化笔记本。
我们的功能演示
获得可靠的和干净的数据后,数据科学家的第一个步骤是确定哪些列(即。特性)将用于他们的模型。
确定重要功能:传统ML管道
通常有很多的步骤,选择您想要使用哪些特性模型。在我们的示例中,我们创建一个二进制分类器(这是一个不良贷款吗?),我们将需要定义潜在功能,vectorize数字和分类功能,最后选择特性,将用于您的模型的创建。
扩大传统视图识别重要的功能细节
/ /加载贷款风险分析数据集val sourceData = spark.read (“…”)/ /视图数据显示器(sourceData)
可以看到从上面的表中,贷款风险分析数据集包含数字和分类列。这是一个重要的区别,因为会有一组不同的数字和分类的步骤列最终组装一个向量,将被用作毫升模型的输入。
为了更好地理解如果有一个独立变量之间的相关性,我们可以快速检查sourceData使用显示命令来查看这些数据散点图。
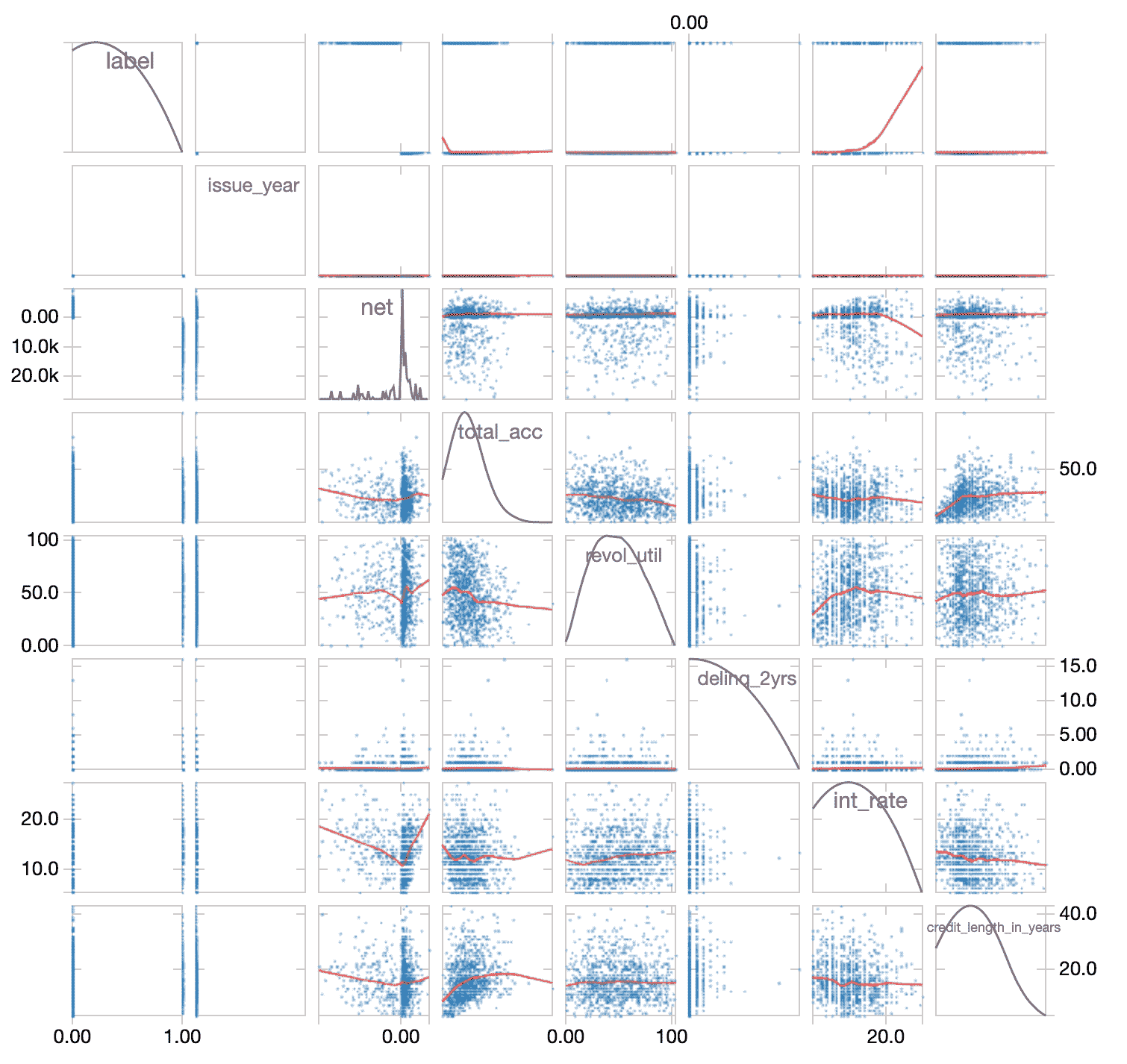
您可以进一步分析这些数据通过计算相关系数;一个受欢迎的方法是使用熊猫载于()。当我们的砖笔记本写在Scala中,我们可以快速、轻松地使用Python熊猫,代码如下。
%python#计算使用熊猫“相关系数”pdf_corr=火花。sql(“选择loan_amnt、emp_length annual_inc, dti, delinq_2yrs, revol_util, total_acc, credit_length_in_years, int_rate,净,issue_year,标签从sourceData”) .toPandas ()。相关系数()#视图相关系数通过loan_amnt显示器(pdf_corr。loc [:,“loan_amnt”]])
正如前面的散点图(扩大这些细节的上面),没有明显的数值变量高度相关。在此基础上评估,我们将继续在创建模型的所有列。
识别重要的特性:AutoML工具包
需要注意的是,这一过程的识别重要的功能可以是一个高度迭代和耗时的过程。有很多不同的技术,可以应用这个过程本身是一本(如。对机器学习功能工程:数据科学家的原则和技术)。
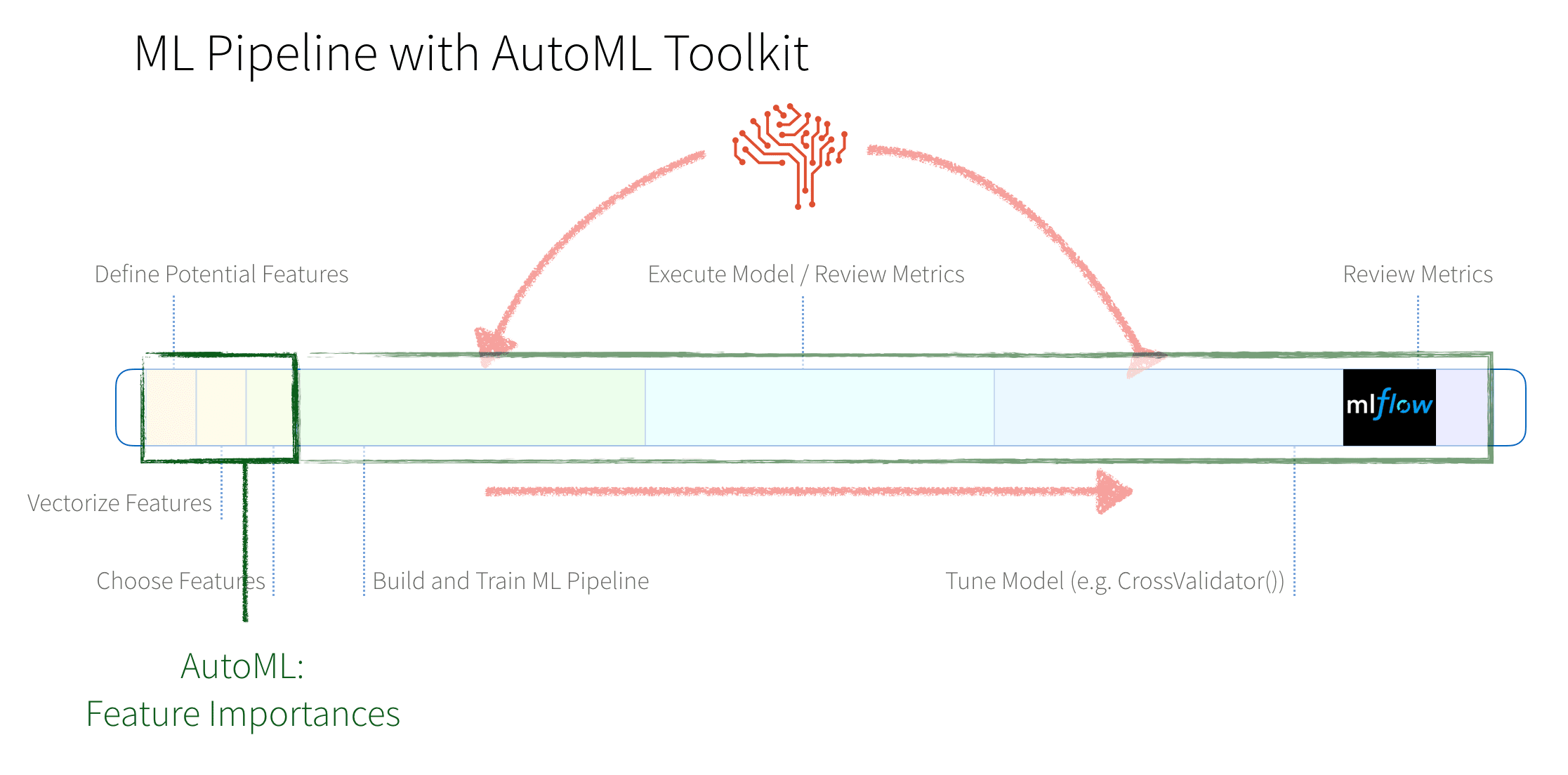
AutoML工具包包括类FeatureImportances自动标识最重要的功能;这是全部完成下面的代码片段。
/ /计算特性的重要性(fi)val fiConfig = ConfigurationGenerator.generateConfigFromMap (“XGBoost”,“分类”genericMapOverrides)/ /因为我们使用XGBoost这里我们不能有并行> 2 x的节点数量fiConfig.tunerConfig。tunerParallelism = nodeCount *2val fiMainConfig = ConfigurationGenerator.generateFeatureImportanceConfig (fiConfig)/ /生成特性的重要性val重要性=新FeatureImportances (sourceData fiMainConfig,“数”,20.0).generateFeatureImportances ()/ /显示功能的重要性显示器(importances.importances)
在这个特定的例子中,三十(30)不同的火花工作找自动生成和执行最重要的特性,需要包括在内。注意,引发工作开始的数量将取决于几个因素。而不是几天或几周的手动探索数据,四行代码,我们确定了这些特性在几分钟内。
让我们构建它!
既然我们已经确定了我们最重要的特性,让我们构建,火车,验证和优化我们的ML管道贷款风险数据集。
传统的模型建立和优化
下面的步骤是删节版的评估的风险贷款批准使用XGBoost (0.90)笔记本电脑代码。
扩大对传统模式构建和优化细节
首先,我们将定义我们的分类和数字列。
//定义我们的分类和数字列val分类=数组(“术语”、“home_ownership”、“目的”,“addr_state”,“verification_status”,“application_type”)val的数字=数组(“loan_amnt”、“emp_length”、“annual_inc”、“唯一”、“delinq_2yrs”,“revol_util”、“total_acc”、“credit_length_in_years”)然后我们将构建我们毫升管道如下提到的代码片段。代码中的注释所指出的,我们的管道有以下步骤:
- VectorAssembler:基于我们的装配特征向量特征列处理以下
- 数据录入员估计完成缺失值为数值型数据
- StringIndexer编码一个数值的字符串值
- OneHotEncoding映射一个分类特征(StringIndexer数值所代表的)一个二进制向量
- LabelIndexer:指定我们的标签是标签(即真实价值)与我们的预测(即坏或好贷款)的预测价值
- StandardScaler:规范化特征向量特征值不同的规模的影响最小化。
注意,这个例子是我们的一个简单的二元分类的例子;有很多方法可以用来提取、转换和选择功能。
进口org.apache.spark.ml.feature.VectorAssembler进口org.apache.spark.ml.feature.StringIndexer/ /归罪估计完成缺失值val numerics_out =数字。地图(_ +“找到”)val imputers =新输入().setInputCols(数字).setOutputCols (numerics_out)/ / StringIndexer申请我们的分类数据val categoricals_idx =直言。地图(_ +“_idx”)val分度器= categoricals.map (x= >新StringIndexer () .setInputCol (x)。setOutputCol (x +“_idx”).setHandleInvalid (“保持”))/ /我们申请我们StringIndexed分类数据val categoricals_class =直言。地图(_ +“_class”)val oneHotEncoders =新OneHotEncoderEstimator ().setInputCols (categoricals_idx).setOutputCols (categoricals_class)/ /设置特性列val featureCols = categoricals_class + + numerics_out/ /为我们的数字列创建汇编程序(包括标签)val汇编=新VectorAssembler ().setInputCols (featureCols).setOutputCol (“特征”)/ /建立标签val labelIndexer =新StringIndexer ().setInputCol (“标签”).setOutputCol (“predictedLabel”)/ /应用StandardScalerval标量=新StandardScaler ().setInputCol (“特征”).setOutputCol (“scaledFeatures”).setWithMean (真正的).setWithStd (真正的)/ /构建管道数组val pipelineAry =索引器+ +数组(oneHotEncoders imputers、汇编、labelIndexer标量)我们的管道和决定使用XGBoost模型(如上所述贷款风险分析与XGBoost砖运行时机器学习),让我们构建、训练、验证我们的模型。
/ /创建XGBoostClassifierval xgBoostClassifier =新XGBoostClassifier (地图(字符串,任何)(“num_round”- >5,“客观”- >“二进制:物流”,“nworkers”- >16,“nthreads”- >4)).setFeaturesCol (“scaledFeatures”).setLabelCol (“predictedLabel”)/ /创建XGBoost管道val xgBoostPipeline =新管道()。setStages (pipelineAry: + xgBoostClassifier)/ /创建XGBoost模型基于训练数据集val xgBoostModel = xgBoostPipeline.fit (dataset_train)/ /测试我们的模型对验证数据集val预测= xgBoostModel.transform (dataset_valid)通过使用BinaryClassificationEvaluator包含在火花MLlib,我们可以评估模型的性能。
/ /包含BinaryClassificationEvaluator进口org.apache.spark.ml.evaluation.BinaryClassificationEvaluator/ /评估val评估者=新BinaryClassificationEvaluator ().setRawPredictionCol (“概率”)/ / AUC计算验证val auc = evaluator.evaluate(预测)/ / AUC值/ / 0.6507AUC值为0.6507,看看我们可以进一步优化这个模型通过设置paramGrid和使用CrossValidator ()。重要的是要注意,您需要理解模型选项(例如XGBoost分类器maxDepth)正确选择参数。
进口org.apache.spark.ml.tuning。{CrossValidator, CrossValidatorModel, ParamGridBuilder}/ /构建参数网格val paramGrid =新ParamGridBuilder ().addGrid (xgBoostClassifier.maxDepth数组(4,7)).addGrid (xgBoostClassifier.eta数组(0.1,0.6)).addGrid (xgBoostClassifier.numRound数组(5,10)).build ()/ /设置BinaryClassificationEvaluator评估者val评估者=新BinaryClassificationEvaluator ().setRawPredictionCol (“概率”)/ /建立CrossValidator ()val简历=新CrossValidator ().setEstimator (xgBoostPipeline).setEvaluator(评估者).setEstimatorParamMaps (paramGrid).setNumFolds (4)/ /运行交叉验证,并选择最好的一组参数。val cvModel = cv.fit (dataset_train)/ /测试我们的模型对cvModel和验证数据集val predictions_cv = cvModel.transform (dataset_valid)/ /计算AUC cvModel验证val cvAUC = evaluator.evaluate (predictions_cv)/ / AUC值/ / 0.6732经过多次迭代,选择不同的参数和测试一箩筐的不同的值参数(扩大更多细节的上面),使用传统的模型构建和优化我们能够改进模型具有一个AUC = 0.6732 (0.6507)。
AutoML模型建立和调优
与所有传统的模型构建和调优步骤以天(或周),我们可以手动建立一个模型比随机AUC值。但随着AutoML工具包,AutomationRunner让我们执行上述步骤几行代码。
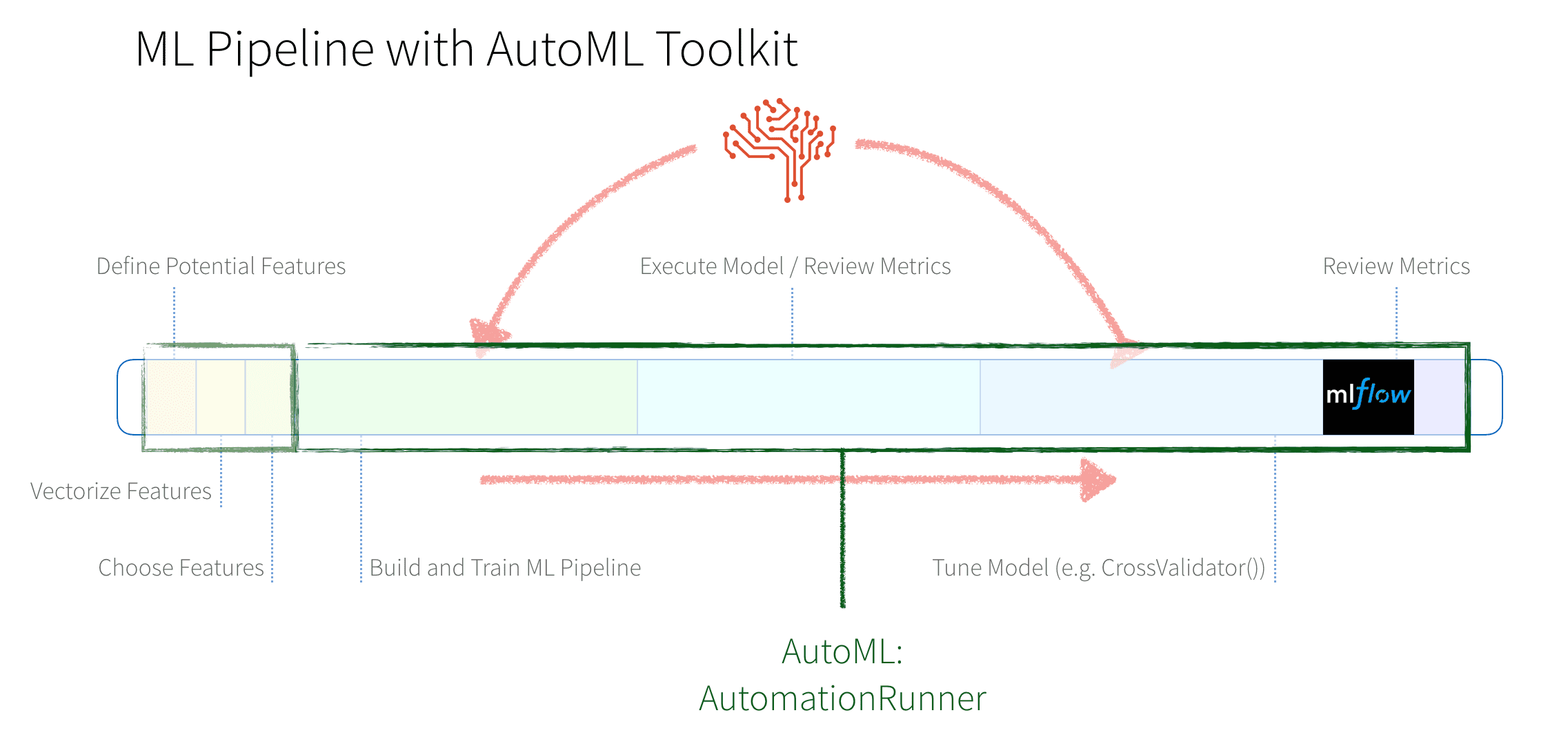
用以下五行代码,AutoML工具包AutomationRunner执行所有前面提到的步骤(建立、培训、验证优化重复)自动。
val modelingType =“XGBoost”val相依= ConfigurationGenerator.generateConfigFromMap (modelingType,“分类”genericMapOverrides)/ /调整模型调谐器配置conf.tunerConfig。tunerParallelism = nodeCount/ /生成配置val XGBConfig = ConfigurationGenerator.generateMainConfig(配置)/ /选择的重要特征val跑=新AutomationRunner (dataset_train。选择(selectionFields: _ *)).setMainConfig (XGBConfig).runWithConfusionReport ()在几个小时内(或分钟),AutoML工具箱发现最好的模型和存储模型和推理数据如上所述的输出之前的代码片段。
…模型将被保存到路径dbfs:/毫升/dennylee / automl /模型/ dl_AutoML_Demo / BestRun classifier_XGBoost_421b6cbe1e954ebba119eb3bfc2997bf / bestModel推理DF将保存到dbfs:/毫升/dennylee / automl /推论/ dl_AutoML_Demo / 3959076 _best / 421 b6cbe1e954ebba119eb3bfc2997bf_bestmodelingType:字符串= XGBoost…因为AutoML工具包使用砖MLflow集成自动登录,所有模型的指标。

正如MLflow细节(前截图),AUC (areaUnderROC值为0.72)有所改善!
AutoML工具包是怎么做的呢?背后的细节如何AutoML工具包能够这样做将讨论在未来的博客。从一个高水平,AutoML工具包能找到更好hyperparameters因为它测试和优化所有修改hyperparameters分布式的方式使用优化算法的集合。合并AutoML工具包内的理解如何使用参数提取算法的源代码(例如XGBoost在这种情况下)。
清理混乱
AUC值显著提高,如何更好的AutoML XGBoost模型相比,执行创建的手吗?因为这是一个二元分类问题,我们可以使用混淆矩阵澄清混乱。手工制作的混淆矩阵模型和AutoML工具包笔记本包括如下。匹配的分析我们所做的在过去(阿拉巴马州贷款风险分析与XGBoost砖运行时机器学习),我们评估贷款规模,2015年之后。
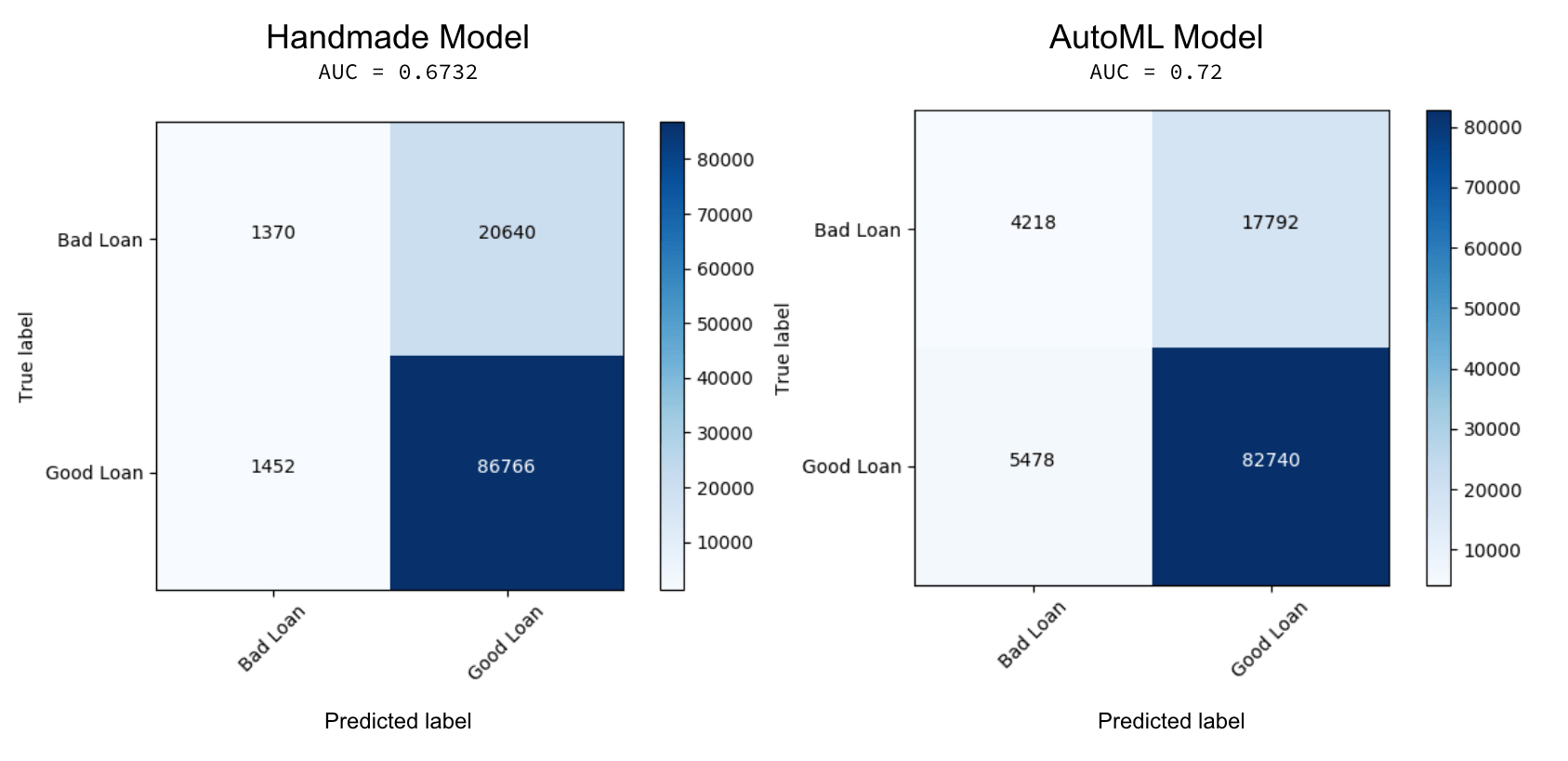
在前面的图形中,左边的混淆矩阵是手工XGBoost模型,而右边的是来自AutoML工具包。虽然两种模型做一个伟大的工作正确地识别优质贷款(真:好,预测:好),AutoML模型上执行更好的识别不良贷款(正确的:不好,预测:坏- 4218与1370)以及防止假阳性(真实:糟糕,预测:好- 17792和20640年)。在这个场景中,这就意味着如果我们使用机器学习模型由AutoML(而不是手工制作的模型),我们可以有可能避免发行2848更多的不良贷款可能会违约和成本钱。同样重要的是,这种模式可能会阻止更头疼,客户体验不好通过降低假阳性错误地预测这是一个好贷款,而实际上它可能是一个糟糕的贷款。
理解业务价值
我们量化这种混淆矩阵业务价值;的定义是:
| 预测 | 标签(不良贷款) | 简短的描述 | 长描述 |
|---|---|---|---|
| 1 | 1 | 避免了损失 | 正确发现不良贷款 |
| 1 | 0 | 利润被没收的 | 不正确的标签不良贷款 |
| 0 | 1 | 损失仍然发生 | 错误地标记好贷款 |
| 0 | 0 | 利润留存 | 正确地找到了好贷款 |
审查相关的美元价值我们的手工制作的混淆矩阵模型,我们将使用下面的代码片段。
//价值获得了从实现模型=- - - - - -(避免损失- - - - - -利润丧失)显示器(predictions_cv。groupBy(“预测”、“标签”).agg ((总和(坳(“净”))/(1 e6).alias (“sum_net_mill”)))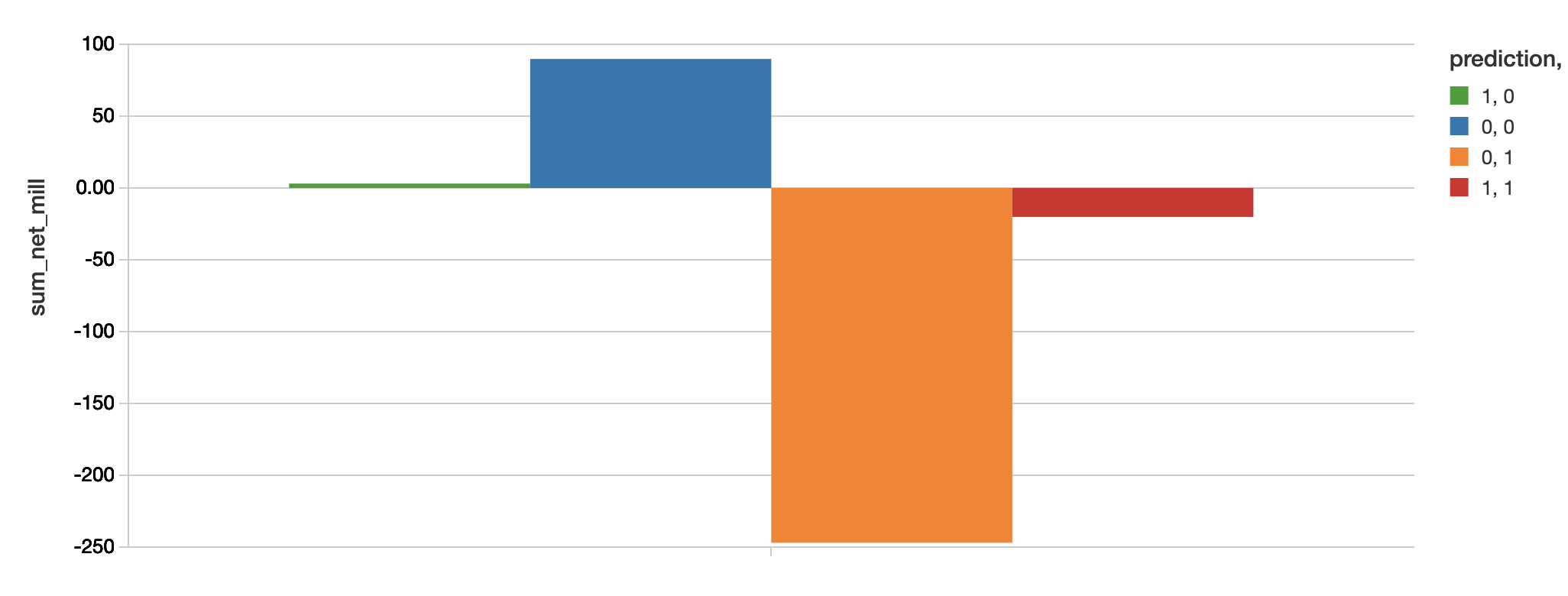
审查相关的美元价值的混淆矩阵AutoML工具包模型将使用下面的代码片段。
//价值获得了从实现模型=- - - - - -(避免损失- - - - - -利润丧失)为2015年数据显示器(cmndf。groupBy(“预测”、“标签”).agg ((总和(坳(“净”))/(1 e6).alias (“sum_net_mill”)))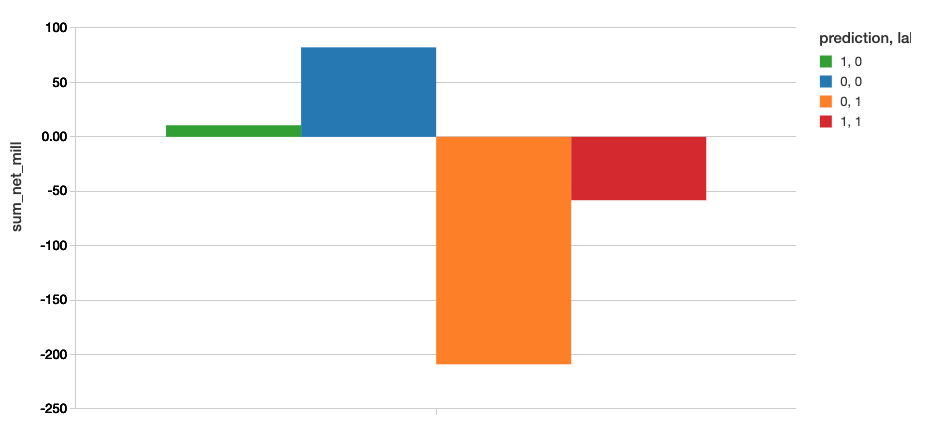
业务价值计算值=(避免损失利润丧失)
| 模型 | 避免了损失 | 利润被没收的 | 价值 |
|---|---|---|---|
| 手工制作的 | -20.16 | 3.06 | 23.22美元 |
| AutoML工具包 | -58.22 | 10.66 | 68.88美元 |
你可以观察,潜在的利润被使用AutoML工具包3 x比我们的手工制作的模型与储蓄68.88美元。
AutoML工具包:更少的代码和更快
与AutoML工具包,您可以编写更少的代码提供更快更好的结果。这个贷款风险分析与XGBoost示例中,我们看到了改善性能的AUC = 0.72和0.6732(68.88美元和23.22美元的潜在储蓄与原技术)。AutoML工具包hyperparameters因为它能找到好多了自动生成、测试和优化算法的所有修改hyperparameters分布式的方式。
尝试的AutoML工具包与使用AutoML工具包来简化贷款风险分析XGBoost模型优化笔记本上砖今天!
修正
以前这个博客已经声明一个由于错误地保持AUC值为0.995净列特征代(它有一个几乎1:1关系贷款预测)。一旦这是纠正,正确的AUC是0.72。多亏了肖恩·欧文,Sanne德罗和Carsten Thone很快识别这一问题。