


每天运行一次流作业,节省10倍的成本
这是关于如何使用Apache Spark执行复杂流分析的系列文章的第6篇。传统上,当人们…
这是第六篇文章由多部分组成的系列如何使用Apache Spark执行复杂的流分析。
传统上,当人们想到流媒体时,脑海中会出现“实时”、“全天候”或“始终在线”等术语。您可能遇到数据只在固定的时间间隔到达的情况。也就是说,数据每小时或每天显示一次。对于这些用例,对这些数据执行增量处理仍然是有益的。但是,为了每天执行少量的处理而让集群全天候运行是一种浪费。
幸运的是,通过使用Spark 2.2中结构化流中新增的Run Once触发器特性,您将获得催化剂优化器增加您的工作负载,以及没有空闲集群所节省的成本。在这篇文章中,我们将研究如何使用触发器来实现这两个目标。
在结构化流中,触发器用于指定流查询产生结果的频率。一旦触发器触发,Spark将检查是否有新的可用数据。如果有新数据,则对自上一个触发器以来到达的任何数据增量地执行查询。如果没有新数据,则流休眠,直到下一个触发器触发。
结构化流的默认行为是以尽可能低的延迟运行,因此触发器在前一个触发器完成后立即触发。对于延迟需求较低的用例,结构化流支持ProcessingTime触发器,该触发器将触发每个用户提供的间隔,例如每分钟。
虽然这很棒,但仍然需要集群保持24/7运行。相反,RunOnce触发器只触发一次,然后将停止查询。正如我们将在下面看到的,这使您可以有效地利用外部调度机制,如Databricks Jobs。
触发器是在启动流时指定的。
(code_tabs)
#加载流数据帧sdf = spark.readStream.load(path=" / /路径”,格式=“json”、模式= my_schema)#执行转换,然后写…sdf.writeStream.trigger(一旦=真正的=) .start(路径/ /路径”,格式=“铺”)进口org.apache.spark.sql.streaming.Trigger//加载流数据帧val sdf = spark.readStream.format(“json”. schema (my_schema) .load ()" / /路径”)//执行转换,然后写入…sdf.writeStream.trigger Trigger.Once .format (“铺”) .start (/ /路径”)[/ code_tabs]
您可能会问,这与简单地运行批处理作业有什么不同?让我们回顾一下在批处理作业上运行结构化流的好处。
在运行执行增量更新的批处理作业时,通常必须弄清楚哪些数据是新的,哪些应该处理,哪些不应该处理。结构化流已经为你做了所有这些。在编写一般的流应用程序时,您应该只关心业务逻辑,而不是底层的簿记。
大数据处理引擎最重要的特征是它能够容忍故障和失败。ETL作业可能(在实践中,经常会)失败。如果作业失败,那么您需要确保作业的输出应该被清理,否则在下一次成功运行作业之后,您将得到重复或垃圾数据。
在使用结构化流写出基于文件的表时,结构化流在每次成功触发后将作业创建的所有文件提交到日志中。当Spark回读该表时,它使用该日志来确定哪些文件是有效的。这确保了由失败引起的垃圾不会被下游应用程序消耗。
如果您的数据管道有可能生成重复的记录,但您只需要一次语义,那么如何使用批处理工作负载实现这一点呢?有了结构化流,它就像设置水印和使用一样简单dropDuplicates ().通过配置足够长的水印以包含流作业的几次运行,您将确保不会获得重复的数据在运行。
运行全天候的流媒体工作是一项代价高昂的折磨。您可能有一些用例,其中延迟数小时是可以接受的,或者数据以小时或每天为单位。为了获得上面描述的结构化流的所有好处,您可能认为需要一直保持集群正常运行。但是现在,有了“执行一次”触发器,你就不需要这样做了!
在Databricks,我们有一个两阶段的数据管道,由一个增量作业组成,该作业将提供最新的数据,而在一天结束时,另一个作业将处理一整天的数据,执行重复数据删除,并覆盖增量作业的输出。第二个作业将使用比第一个作业大得多的资源(4倍),并且运行的时间也更长(3倍)。我们能够在许多管道中省去第二份工作,这相当于节省了10倍的总成本。使用新的execute once触发器,我们还能够清理代码库中的大量代码。这些节省下来的成本让财务经理和工程经理都很高兴!
Databricks的Jobs调度器允许用户通过简单的点击来安排生产作业。作业调度器非常适合调度使用execute once触发器运行的结构化流作业。
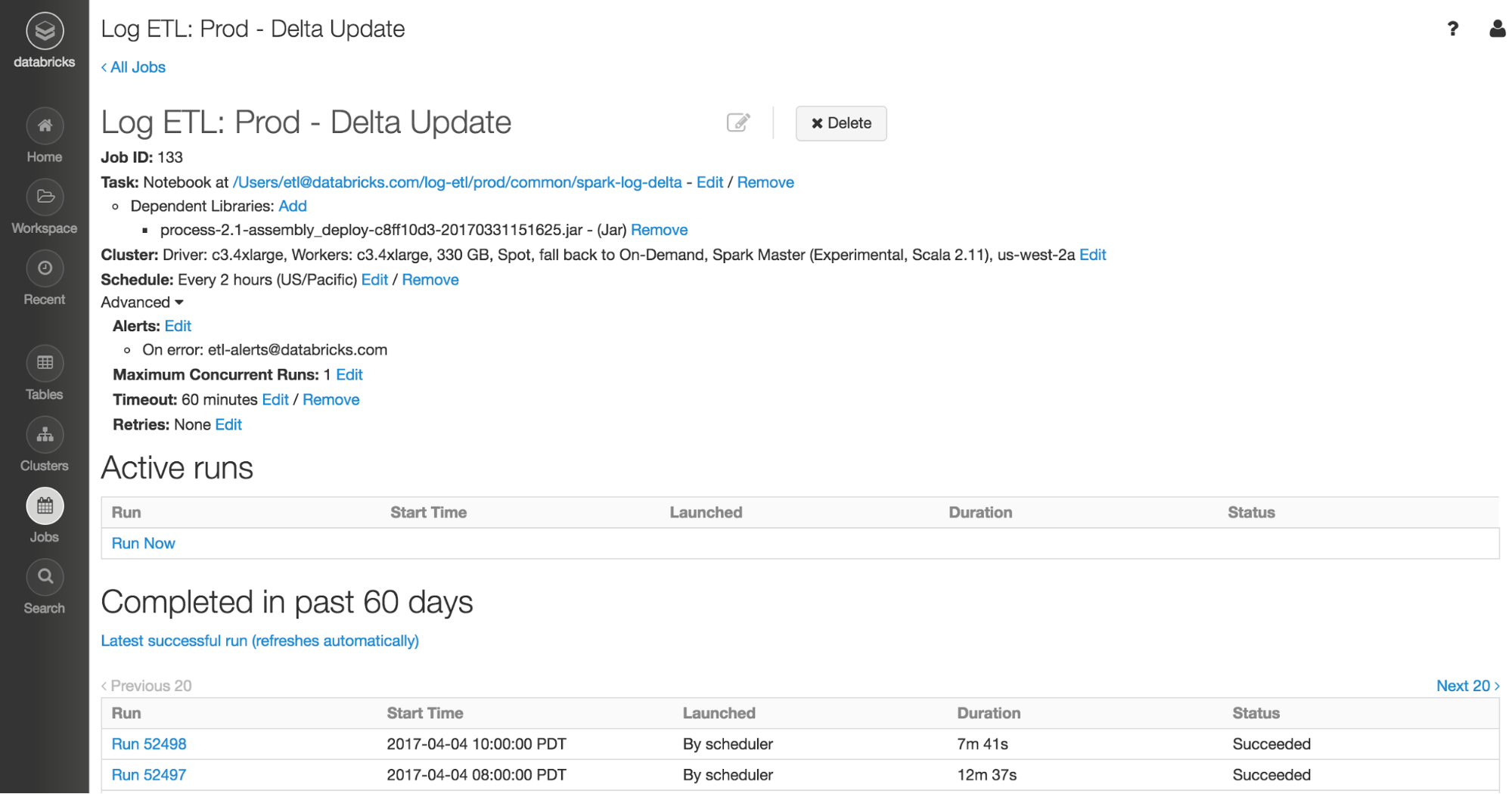
在Databricks,我们使用Jobs调度器来运行所有的生产作业。作为工程师,我们确保ETL作业中的业务逻辑经过了良好的测试。我们将代码作为库上传到Databricks,并设置笔记本以设置ETL作业的配置,例如输入文件目录。剩下的部分由Databricks来管理集群、调度和执行作业,以及Structured Streaming来确定哪些文件是新的,并处理传入的数据。最终的结果是一个端到端(从数据源到数据仓库,而不仅仅是在Spark中)的数据管道。看看我们的文档关于如何最好地运行结构化流与工作。
在这篇博文中,我们介绍了结构化流的新“执行一次”触发器。虽然execute once触发器类似于运行批处理作业,但我们讨论了它相对于批处理作业方法的所有优点,具体来说:
除了批处理的所有这些好处之外,您还可以节省成本,因为不需要为不定期的流作业启动和运行一个空闲的24/7集群。批处理和流处理的两个世界的最好的现在在您的指尖。
试试结构化流今天在Databricks by注册一个14天的免费试用.
本博客系列的其他部分也解释了其他好处: