
Apache火花的结构化流到生产



这是第五篇由多部分组成的系列如何你可以执行复杂的流分析使用Apache火花。
在砖,我们我们的生产管道迁移到结构化流过去几个月,想分享我们的开箱即用的部署模型允许我们的客户快速构建生产管道砖。
一个生产应用程序需要监控、报警和自动故障恢复(原生云)方法。这篇文章不仅介绍可用的api解决这些挑战但也将展示如何砖使结构化流在生产运行简单。
度量和监控
结构化流在Apache火花提供了一个简单的编程API来获得当前执行流的信息。有两个关键的命令,您可以运行在当前活动流为了得到相关信息的查询执行进展:获取当前的命令状态查询和命令recentProgress的查询。
状态
你可能会问的第一个问题是,“我现在流执行处理是什么?”The status maintains information about the current state of the stream, and is accessible through the object that was returned when you started the query. For example, you might have a simple counts stream that provides counts of IOT devices defined by the following query.
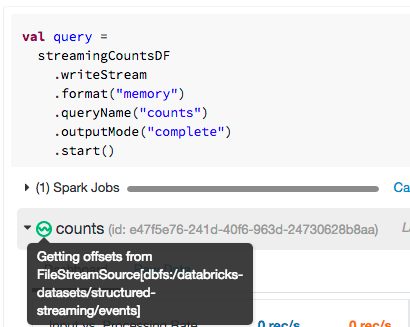
查询= streamingCountsDF \.writeStream \。格式(“记忆”)\.queryName (“计数”)\.outputMode (“完整的”)\.start ()运行query.status将返回流的当前状态。这给了我们的细节发生了什么在那个时间点上的流。
{“消息”:“从FileStreamSource得到补偿(dbfs / databricks-datasets / structured-streaming /事件):“,“isDataAvailable”:真正的,“isTriggerActive”:真正的}砖的笔记本给你一个简单的方法来发现任何流查询的状态。你只需将鼠标停在
最近的进展
虽然查询状态无疑是重要的,同样重要的是一个能够查看查询的历史进步。进步的元数据将使我们能够回答这样的问题“我处理元组以什么速度?”或“元组到达从源的速度有多快?”
通过运行stream.recentProgress你会获得更多的基于时间的信息处理速度和批处理时间。然而,一张图片胜过一千年JSON斑点,所以在砖,我们创建可视化为了方便快速分析的最新进展流。

让我们了解一下为什么我们选择显示这些指标和为什么他们对你理解很重要。
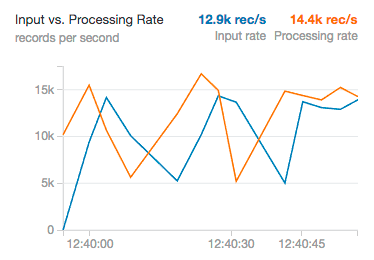
输入速度和处理速度
输入率指定多少数据流入结构化流从一个系统就像卡夫卡或运动。处理速度是多快我们可以分析这些数据。在理想的情况下,这些应该变化始终在一起;然而,他们多少会有所不同根据输入数据处理开始时存在。如果输入速度远远超过的处理速度,我们流将落后,我们需要集群规模更大的大小来处理更大的负载。
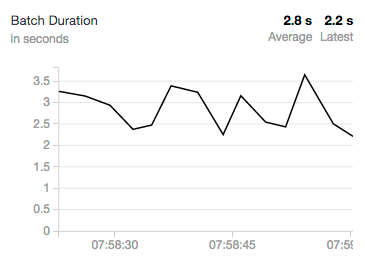
批处理时间
几乎所有的流媒体系统利用批处理操作在任何合理的吞吐量(一些有一个选项高延时,以换取更低的吞吐量)。结构化流实现。运营数据,您可能会看到这个振荡结构化流过程不同数量的事件。这一核心集群在Community Edition中,我们可以看到,我们的批处理时间是振荡持续三秒钟左右。更大的集群自然会有更快的处理速度,以及批处理时间要短得多。
生产报警流工作
度量和监控都是很好,但是为了快速反应出现的任何问题,而无需照顾你流工作一整天,你需要一个健壮的警示故事。砖简化了报警,允许你运行流工作生产管道。
例如,让我们定义一个砖工作以下规格:

注意到我们设置一个电子邮件地址在PagerDuty触发警报。这将触发警报产品(或您指定的级别)当作业失败。
自动故障恢复
同时提醒方便,不得不迫使人类应对停机不方便在最好的情况下,是不可能的。为了真正productionize结构化流,你会希望能够尽快恢复自动失败,同时确保数据一致性和数据丢失。砖使得这种无缝的:只是之前设置重试的次数不可恢复的故障和砖将尝试恢复流自动工作。在每一个失败,你可以触发通知生产中断。
你得到两全其美。系统将尝试自我修复,同时保持员工和开发人员的通知状态。
更新应用程序
有两种情况下,你需要思考当你更新你的流媒体应用程序。在大多数情况下,如果你不改变重要的业务逻辑(如输出模式)您可以简单地重新启动流使用相同的检查站工作目录。新更新的流媒体应用程序将离开,继续运作。
然而,如果你改变状态操作(如聚合或输出模式),更新更多的参与。你必须用一个新的开始一种全新的流检查点目录。幸运的是,很容易启动另一个并行流在砖为了运行时转换到新流。
先进的报警和监控
还有其他几种先进的监测技术,砖支持。例如,您可以使用系统输出的通知Datadog,Apache卡夫卡,或Coda Hale指标。这些先进的技术可以用于实现外部监测和报警系统。
下面是一个例子,您可以创建一个StreamingQueryListener将所有查询进展信息转发给卡夫卡。
类KafkaMetrics(服务器:字符串)扩展StreamingQueryListener{瓦尔kafkaProperties=新属性()kafkaProperties。把(“bootstrap.servers”、服务器)kafkaProperties。把(“key.serializer”,“kafkashaded.org.apache.kafka.common.serialization.StringSerializer”)kafkaProperties。把(“value.serializer”,“kafkashaded.org.apache.kafka.common.serialization.StringSerializer”)瓦尔生产商=新KafkaProducer(字符串,字符串)(kafkaProperties)defonQueryProgress(事件:org.apache.spark.sql.streaming.StreamingQueryListener.QueryProgressEvent):单位= {生产商。发送(新ProducerRecord (“streaming-metrics”,event.progress.json))}defonQueryStarted(事件:org.apache.spark.sql.streaming.StreamingQueryListener.QueryStartedEvent):单位= {}defonQueryTerminated(事件:org.apache.spark.sql.streaming.StreamingQueryListener.QueryTerminatedEvent):单位= {}}结论
在这篇文章中,我们展示了简单的结构化流从原型到生产使用砖。阅读更多关于结构化流的其他方面,阅读我们的一系列的博客: