


在Apache Spark 2.1中使用结构化流处理复杂数据格式
可伸缩数据@数据的第2部分
在第1部分在这个关于结构化流的系列博客文章中,我们演示了使用结构化流编写端到端流ETL管道是多么容易,它将JSON CloudTrail日志转换为Parquet表。该博客强调,构建此类管道的主要挑战之一是读取和转换来自各种来源和复杂格式的数据。在这篇博客文章中,我们将进一步详细地研究这个问题,并说明如何进行Apache火花SQL的内置函数可用于解决所有数据转换挑战。
具体来说,我们将讨论以下内容:
- 不同的数据格式和它们之间的权衡是什么
- 如何使用Spark SQL轻松地与他们合作
- 如何为您的用例选择正确的最终格式
数据源和格式
数据有无数种不同的格式。电子表格可以用XML、CSV、TSV表示;应用程序指标可以以原始文本或JSON形式编写。每个用例都有为其量身定制的特定数据格式。在大数据的世界里,我们经常会遇到Parquet、ORC、Avro、JSON、CSV、SQL和NoSQL数据源以及纯文本文件等格式。我们可以将这些数据格式大致分为三类:结构化、半结构化和非结构化数据。让我们试着了解每种类别的优点和缺点。
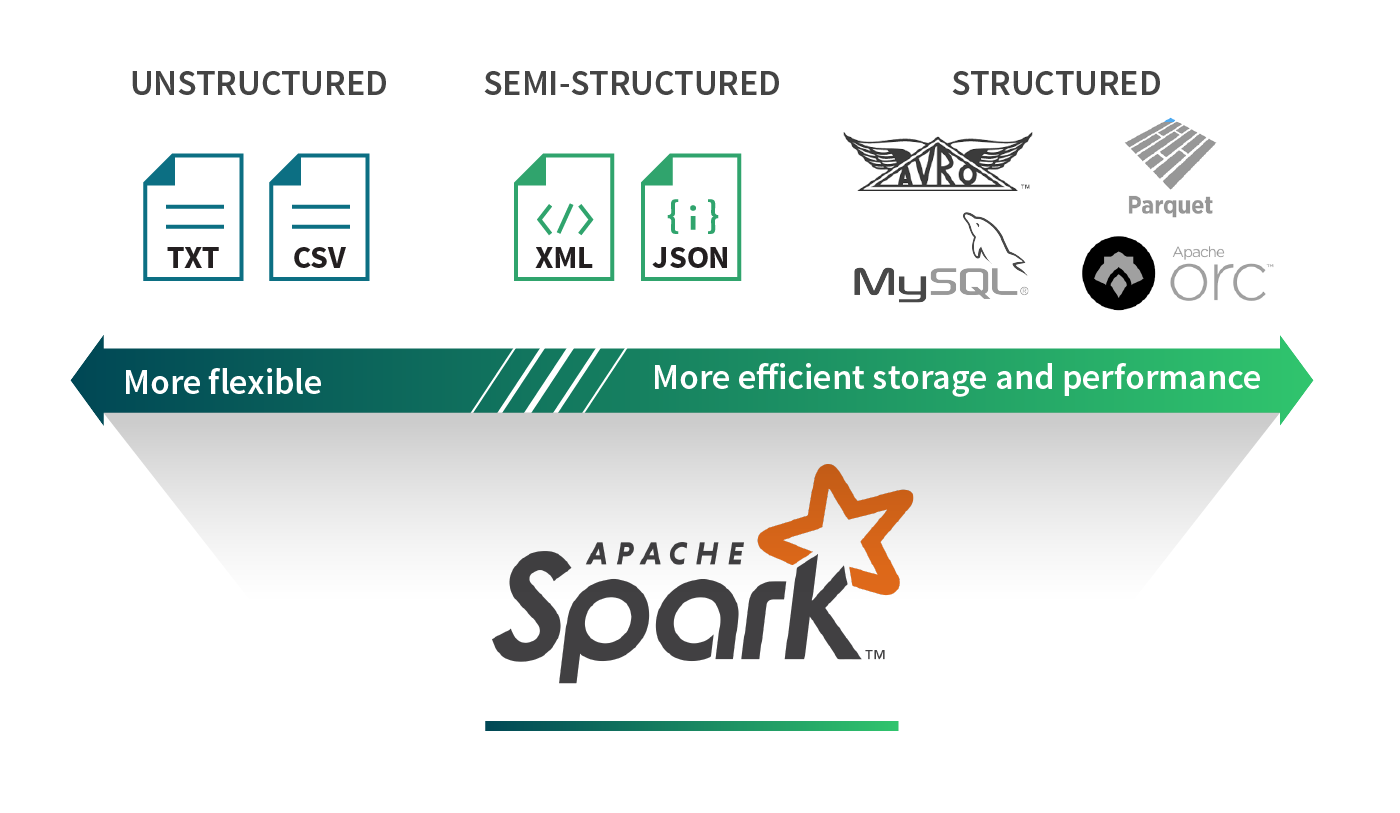
结构化数据
结构化数据源在数据上定义了一个模式。有了这些关于底层数据的额外信息,结构化数据源就能提供高效的存储和性能。例如,Parquet和ORC等柱状格式使从列子集提取值变得更加容易。首先逐行读取每个记录,然后从感兴趣的特定列中提取值,这样可以读取比查询只对一小部分列感兴趣时所需的数据多得多的数据。基于行的存储格式(如Avro)可以有效地序列化和存储数据,从而提供存储优势。然而,这些优势往往是以灵活性为代价的。例如,由于结构的刚性,发展模式可能具有挑战性。
非组织性数据
相比之下,非结构化数据源通常是不包含标记或元数据(例如,CSV文件中的逗号)的自由形式的文本或二进制对象,以定义数据的组织。报纸文章、医疗记录、图像斑点、应用程序日志通常被视为非结构化数据。这些类型的源通常要求数据周围的上下文是可解析的。也就是说,您需要知道该文件是图像还是报纸文章。大多数数据源是非结构化的。使用非结构化格式的代价是,从这些数据源中提取价值变得很麻烦,因为需要许多转换和特征提取技术来解释这些格式数据集.
半结构化数据
半结构化数据源是按每条记录结构化的,但不一定具有跨越所有记录的定义良好的全局模式。因此,每个数据记录都增加了它的模式信息。JSON和XML是比较流行的例子。半结构化数据格式的好处是,它们在表示数据时提供了最大的灵活性,因为每个记录都是自描述的。这些格式在许多应用程序中非常常见,因为存在许多用于处理这些记录的轻量级解析器,而且它们还具有人类可读的优点。然而,这些格式的主要缺点是它们会产生额外的解析开销,并且不是专门为特别查询而构建的。
使用Spark SQL交换数据格式
在我们的上一篇博文,我们讨论了如何将Cloudtrail Logs从JSON转换为Parquet,从而将临时查询的运行时间缩短10倍。Spark SQL允许用户从这些数据源类中摄取数据,包括批处理查询和流查询。它本身支持以Parquet、ORC、JSON、CSV和文本格式读取和写入数据,并且还存在大量其他连接器火花包.您还可以使用JDBC数据源连接到SQL数据库。
Apache Spark可以用于轻松地交换数据格式:
事件=火花。readStream \.格式(“json”) \#或拼花,卡夫卡,兽人….option () \#格式指定选项. schema (my_schema) \#需要.load (“路径/ /数据”)输出=…#执行你的转换输出。writeStream \#写出你的数据.格式(“铺”) \.start (“路径/ /写”)无论是批处理数据还是流数据,我们都知道如何读写不同的数据源和格式,但是不同的数据源支持不同类型的模式和数据类型。传统的数据库只支持基本数据类型,而像JSON这样的格式允许用户在列中嵌套对象,有一个值数组或表示一组键-值对。用户通常必须在这些数据类型之间进行切换,以有效地存储和表示他们的数据。幸运的是,Spark SQL可以轻松处理基本数据类型和复杂数据类型。现在让我们快速浏览一下如何从复杂数据类型转换为基本数据类型,反之亦然。
转换复杂数据类型

在使用半结构化格式时,通常会有复杂的数据类型,如结构、映射和数组。例如,您可能会将API请求记录到web服务器。这个API请求将包含HTTP Headers,这将是一个字符串-字符串映射。请求有效负载可以包含JSON形式的表单数据,表单数据可以包含嵌套字段或数组。一些数据源或格式可能支持也可能不支持复杂的数据类型。在以特定数据类型存储数据时,某些格式可能会提供性能优势。例如,当使用Parquet时,所有结构列都将接受与顶级列相同的处理。因此,如果在嵌套字段上使用筛选器,您将获得与顶级列相同的好处。但是,映射被视为两个数组列,因此您不会收到有效的过滤语义。
让我们看一些例子,看看Spark SQL如何允许您使用一些数据转换技术随意地塑造数据。
从嵌套列中选择
点(.)可以用来访问结构和映射的嵌套列。
/ /输入{“一个”: {“b”:1}}Python: events.select (“a.b”)Scala: events.select (“a.b”)SQL:选择a.b从事件/ /输出{“b”:1}扁平化结构
一颗星(*)可以用来选择struct中的所有子字段。
/ /输入{“一个”: {“b”:1,“c”:2}}Python: events.select (“。*”)Scala: events.select (“。*”)SQL:选择*从事件/ /输出{“b”:1,“c”:2}嵌套列
可以使用SQL中的struct函数或括号来创建新的struct。
/ /输入{“一个”:1,“b”:2,“c”:3.}Python: events.select (struct(坳(“一个”) .alias (“y”) .alias (“x”))Scala: events.select(结构体(“a as”y)作为“x)SQL: select named_struct("y", a) as x from events/ /输出{" x ": {“y”:1}}嵌套所有列
星星(*)也可以用于包含嵌套结构中的所有列。
/ /输入{“一个”:1,“b”:2}Python: events.select(结构体(“*”) .alias (“x”))Scala: events.select(结构体(“*”)作为“x)SQL: select struct(*) as x from events/ /输出{" x ": {“a”: 1、“b”:2}}选择单个数组或映射元素
getItem ()或方括号(即[])可用于从数组或映射中选择单个元素。
/ /输入{“一个”:【1,2]}Python: events.select(坳(“一个”) .getItem (0) .alias (“x”))Scala: events.select ('a.getItem(0) as 'x)SQL: select a[0]作为x从事件/ /输出{“x”:1}/ /输入{“一个”: {“b”:1}}Python: events.select(坳(“一个”) .getItem (“b”) .alias (“x”))Scala: events.select (a.getItem("b") as 'x)SQL: select a[“b”]作为x从事件/ /输出{“x”:1}为每个数组或映射元素创建一行
爆炸()可用于为数组中的每个元素或每个键-值对创建新行。这类似于HiveQL中的LATERAL VIEW explosion。
/ /输入{“一个”:【1,2]}Python: events.select(爆炸(“一个”) .alias (“x”))Scala: events.select(爆炸(a) asx)SQL:选择爆炸(a)作为x从事件/ /输出[{“x”:1},{“x”:2})/ /输入{“一个”: {“b”:1,“c”:2}}Python: events.select(爆炸(“一个”) .alias (“x”,“y”))Scala: events.select(爆炸(’a) as Seq(“x”,“y”))SQL:从事件中选择爆炸(a) as (x, y/ /输出[{"x": "b", "y": 1}, {"x": "c", "y": 2}]将多行收集到一个数组中
collect_list ()而且collect_set ()可用于将项聚合到数组中。
/ /输入[{“x”:1},{“x”:2})Python: events.select (collect_list (“x”) .alias (“x”))Scala: events.select (collect_list ('x) as 'x)SQL: select collect_list(x)作为x从事件/ /输出{“x”:【1,2]}/ /输入[{“x”:1,“y”:“一个”},{“x”:2,“y”:“b”})Python: events.groupBy (“y”) .agg (collect_list (“x”) .alias (“x”))Scala: events.groupBy (“y”) .agg (collect_list ('x) as 'x)SQL: select y, collect_list(x)作为x从事件按y分组/ /输出[{“y”:“一个”,“x”:【1}, {“y”:“b”,“x”:【2]}]从数组中的每个项中选择一个字段
当你在数组上使用点表示法时,我们会返回一个新数组,其中的字段是从每个数组元素中选择的。
/ /输入{“一个”:【{“b”:1},{“b”:2}]}Python: events.select (“a.b”)Scala: events.select (“a.b”)SQL:选择a.b从事件/ /输出{“b”:【1,2]}to_json()和from_json()的功能
如果您确实希望保存列的复杂结构,但又需要将其编码为字符串来存储它,该怎么办?你完蛋了吗?当然不是!Spark SQL提供了如下函数to_json ()将结构体编码为字符串和from_json ()检索作为复杂类型的结构。在像Kafka这样的流数据源中,使用JSON字符串作为列是非常有用的。每个Kafka键值记录都将增加一些元数据,比如输入Kafka的时间戳,Kafka中的偏移量等等。如果包含数据的“value”字段是JSON格式的,则可以使用from_json ()提取你的数据,丰富它,清理它,然后把它推到下游Kafka再次或写出来到一个文件。
将结构体编码为json
to_json ()可以用来将结构转换为JSON字符串。当你想把数据写入Kafka时,把多个列重新编码成一个列时,这个方法特别有用。此方法目前在SQL中不可用。
/ /输入{“一个”: {“b”:1}}Python: events.select (to_json (“一个”) .alias (“c”))Scala: events.select (to_json (a) asc)/ /输出{“c”:“{\ b \”:1}”}将json列解码为struct
from_json ()可用于将带有JSON数据的字符串列转换为结构体。然后,您可以像上面描述的那样将结构平展为单独的列。此方法目前在SQL中不可用。
//输入{“一”:“{\ b \”:1}”}
Python:模式=StructType()。添加(“b”,IntegerType ())events.select (from_json (“一个”,模式).alias("c"))Scala:薇尔模式=新StructType()。添加(“b”,IntegerType)events.select (from_json ('a, schema) as 'c)//输出{" c ": {“b”:1}}有时,您可能希望保留JSON字符串的一部分,以避免模式过于复杂。
//输入{“一”:“{\ b \”:{\“x \”:1,\“y \”:{\“z \”:2}}}”}
Python:模式=StructType()。添加(“b”,StructType()。添加(“x”,IntegerType ()).添加(“y”,StringType ()))events.select (from_json (“一个”,模式).alias("c"))Scala:薇尔模式=新StructType()。添加(“b”,新StructType()。添加(“x”,IntegerType).添加(“y”,StringType))events.select (from_json ('a, schema) as 'c)//输出{" c ": {" b ": {“x”:1,“y”:“{\“z \”:2}”}}}从包含JSON的列中解析一组字段
json_tuple ()可用于提取JSON数据字符串列中的可用字段。
/ /输入{“一个”:“{\ b \”:1}”}Python: events.select (json_tuple (“一个”,“b”) .alias (“c”))Scala: events.select (json_tuple ('a, ' b ') as 'c)SQLselect json_tuple(a,“b”)作为c从事件/ /输出{“c”:1}有时一个字符串列可能不是自描述为JSON,但可能仍然有一个格式良好的结构。例如,它可以是使用特定Log4j格式生成的日志消息。Spark SQL可以用来构造这些字符串为您轻松!
解析一个格式良好的字符串列
regexp_extract ()可用于使用正则表达式解析字符串。
/ /输入[{“一个”:“x: 1”},{“一个”:“杨:2”})Python: events.select (regexp_extract (“一个”,”([a - z]):“,1) .alias (“c”))Scala: events.select (regexp_extract (a, "([a-z]):", 1) as "c)SQL: select regexp_extract(a,”([a - z]):“,1)作为c从事件/ /输出[{“c”:“x”},{“c”:“y”})这是很多的转换!现在让我们看看一些真实的用例,以充分利用所有这些数据格式和数据操作功能。
利用所有这些力量
在Databricks,我们从我们的服务中收集日志,并使用它们执行实时监控,以在客户受到影响之前发现问题。日志文件是非结构化文件,但它们是可解析的,因为它们具有定义良好的Log4j格式。我们运行一个日志采集器服务,将每个日志条目和关于该条目的附加元数据(例如源)以JSON形式发送到Kinesis。然后这些JSON记录作为文件批量上传到S3。查询这些JSON日志以回答任何问题都是乏味的:这些文件包含重复项,要回答任何查询,即使只涉及一个列,整个JSON记录都可能需要反序列化。
为了解决这个问题,我们运行一个管道来读取这些JSON记录,并对元数据执行重复数据删除。现在我们只剩下原始的日志记录,它可能是JSON格式,也可能是非结构化文本。如果我们处理JSON,我们使用from_json ()以及上面描述的几种转换来格式化数据。如果是文本,则使用regexp_extract ()将Log4j格式解析为更结构化的形式。一旦我们完成了所有的转换和重构,我们将记录按日期分区保存在Parquet中。这可以让我们在回答诸如“在10:00-10:30之间,我们为这个特定的服务看到了多少条ERROR消息”这样的问题时加速10-100倍?加速可以归因于:
- 我们不再为反序列化JSON记录付出代价
- 我们不必对原始日志消息执行复杂的字符串比较
- 我们只需要在查询中提取两列:时间和日志级别
以下是我们在客户中看到的一些更常见的用例:
“我想用我的数据运行一个机器学习管道。我的数据已经进行了预处理,我将在整个流程中使用我的所有功能。”
当您要访问整行数据时,Avro是一个很好的选择。
“我有一个物联网用例,我的传感器向我发送事件。对于每个事件,重要的元数据都是不同的。”
如果您希望模式具有灵活性,则可以考虑使用JSON存储数据。
“我想训练一种针对报纸文章的语音识别算法,或者对产品评论进行情感分析。”
在数据可能没有固定模式或固定模式/结构的情况下,将其存储为纯文本文件可能更容易。你也可以有一个管道对这些非结构化数据执行特征提取,并将其存储为Avro,为你的机器学习管道做准备。
结论
在这篇博文中,我们讨论了Spark SQL如何允许您使用来自多种来源和格式的数据,并轻松地在这些数据格式之间执行转换和交换。我们分享了我们如何在Databricks中管理数据,并考虑了您可能希望以不同方式做事的其他生产用例。
Spark SQL为您提供了必要的工具来访问您的数据,无论它可能在哪里,以任何格式,并为下游应用程序做好准备,无论是流数据的低延迟还是旧历史数据的高吞吐量!
在本系列的后续博客文章中,我们将介绍更多内容:
- 监控流媒体应用程序
- 集成结构化流与Apache Kafka
- 使用结构化流计算事件时间聚合
如果你想了解更多关于结构化流的BOB低频彩知识,这里有一些有用的链接。
- 之前的博客文章解释了结构化流的动机和概念:
- 在Apache Kafka中使用结构化流处理数据
- 结构化流媒体节目指南
- 在2017年Spark峰会上的演讲-为生产和未来方向准备结构化流媒体
最后,尝试我们的示例笔记本,演示在Python、Scala或SQL中转换复杂的数据类型砖:
免费试用Databricks
相关的帖子