





利用地理空间分析扩大对您所在行业的见解
数据科学正变得越来越普遍,大多数公司都在利用分析和商业智能来帮助制定数据驱动的商业决策。但你是否在利用地理空间数据进行分析和决策呢?位置智能,特别是地理空间分析,可以帮助发现影响您业务的重要区域趋势和行为。这不仅仅是通过邮政编码聚合的位置数据,有趣的是,在美国和世界其他地区,邮政编码并不能很好地代表地理边界。
你是一个零售商,试图弄清楚在哪里设立你的下一家店,或了解你的竞争对手在同一社区的客流量吗?或者你正在关注该地区的房地产趋势,以指导你的下一个最佳投资?您是否处理物流和供应链数据,并必须确定仓库和燃料站的位置?或者,您是否需要识别网络或服务热点,以便调整供应以满足需求?这些用例都有一个共同点——您可以运行多边形中点操作,将这些纬度和经度坐标与它们各自的地理几何图形关联起来。
技术实现
实现的常用方法点包容操作将使用来自PostGIS(开源地理信息系统(GIS)项目)的st_intersects或st_contains等SQL函数。您还可以使用一些Apache Spark™包,如Apache Sedona(以前称为Geospark)或Geomesa,它们提供以分布式方式执行的类似功能,但这些功能通常涉及昂贵的地理空间连接,需要一段时间才能运行。在这篇博客文章中,我们将看看H3如何与Spark一起使用来帮助加速大型多边形中点问题,这可以说是最常见的地理空间工作负载之一,许多人将从中受益。
我们介绍了Uber的H3库过去博客文章.回顾一下,H3是一种地理空间网格系统,它用一组固定的可识别的六边形单元来近似地描述地理特征,如多边形或点。这可以帮助扩展大型或计算昂贵的大数据工作负载。
在我们的例子中,WKT我们正在使用的数据集包含的multipolygon可能不能很好地与H3的polyfill实现一起工作。为了确保我们的管道返回准确的结果,我们需要将multipolygon分割成单独的polygon。
% scala进口org.locationtech.jts.geom.GeometryFactory进口scala.collection.mutable.ArrayBufferdef getPolygon = udf((几何:几何)=>{varnumGeometries = geometry.getNumGeometries()varpolygonArrayBuffer =ArrayBuffer(几何)()为(geomIter分割多边形后,下一步是创建为点和多边形定义H3索引的函数。要用Spark扩展它,你需要将Python或Scala函数包装到Spark中UDF年代。
% scalaVal res =7// H3指数分辨率为1.2kmVal点= df.withColumn (“h3index”十六进制(geoToH3(坳(“pickup_latitude”)、坳(“pickup_longitude”),点燃(res))))points.createOrReplaceTempView (“点”)
val polygons = wktDF.withColumn (“h3index”, multiPolygonToH3(坳(“the_geom”),点燃(res))).withColumn (“h3”爆炸(美元)“h3index”)).withColumn (“h3”十六进制(美元)“h3”))polygons.createOrReplaceTempView (“多边形”)H3支持决议0 ~ 15, 0为长约1107公里的六边形,15为长约50厘米的细粒六边形。您应该选择一个分辨率,理想情况下是数据集中唯一多边形数量的倍数。在这个例子中,我们使用分辨率7。
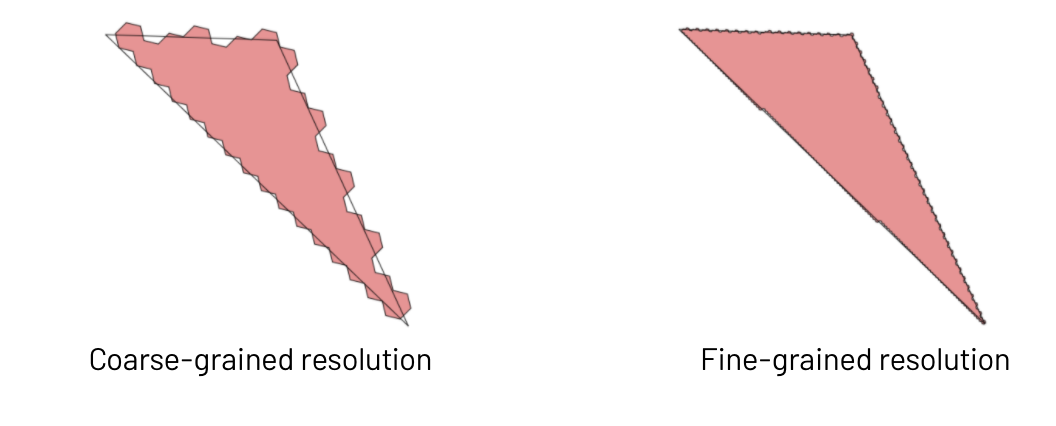
这里需要注意的一点是,使用H3进行多边形中的点操作将给出近似的结果,我们基本上是在用精度换取速度。选择粗粒度分辨率可能意味着在多边形边界上失去一些准确性,但查询将运行得非常快。选择细粒度分辨率将为您提供更好的准确性,但也将增加即将到来的连接查询的计算成本,因为您将有更多唯一的六边形要连接。选择正确的分辨率有点像一门艺术,你应该考虑你需要的结果有多精确。考虑到你的GPS点可能不是那么精确,也许为了速度而放弃一些精度是可以接受的。
用H3索引了点和多边形之后,就可以运行连接查询了。您现在可以在H3索引列上运行一个简单的Spark内部连接,而不是在这里运行像st_intersects或st_contains这样的空间命令,这会触发一个昂贵的空间连接。您的多边形中的点查询现在可以在几分钟内运行数十亿个点和数千或数百万个多边形。
%sql选择*从点p内心的加入多边形年代在p.h3=s.h3如果您需要更高的准确性,这里的另一种可能的方法是利用H3索引来减少传递到地理空间连接的行数。您的查询将看起来像这样,其中您的st_intersects()或st_contains()命令将来自第三方包,如Geospark或Geomesa:
%sql选择*从点p内心的加入形状的年代在p.h3=s.h3在哪里st_intersects (st_makePoint (p。Pickup_longitude, p.pickup_latitude), s.the_geom);潜在的优化
在地理空间数据中遇到数据倾斜是很常见的。例如,与人口稀少地区相比,城市地区可能会收到更多的手机GPS数据点。这意味着某些H3索引可能拥有比其他索引更多的数据,这在我们的Spark SQL连接中引入了倾斜。对于我们的数据集也是如此笔记本的例子与纽约其他地区相比,我们可以看到曼哈顿有大量的出租车接送点。我们可以利用这里的倾斜提示来帮助提高连接性能。
首先,确定您的顶级H3指标是什么。
显示器(points.groupBy (h3)。数() .orderBy(美元“数”。desc))然后,使用为顶部索引定义的倾斜提示重新运行连接查询。如果多边形表足够小,可以放入工作节点的内存中,您还可以尝试广播它。
选择/*+ SKEW('points_with_id_h3', 'h3', ('892A100C68FFFFF')), BROADCAST(多边形)*/*从点p内心的加入多边形年代在p.h3=s.h3另外,不要忘记在连接的左侧有更多行的表。这减少了连接期间的洗牌,可以极大地提高性能。
注意到Spark 3.0的新特性吗自适应查询执行(AQE),手动广播或优化倾斜的需求可能会消失。如果您最喜欢的地理空间软件包现在支持Spark 3.0,那么一定要看看如何利用AQE来加速您的工作负载!
数据可视化
一个可视化H3六边形的好方法是使用Kepler.gl这款软件也是优步开发的。开普勒有一个PyPi库。gl,你可以利用你的Databricks笔记本。请参考这个笔记本的例子如果你有兴趣试一试。
开普勒。Gl库运行在一台机器上。这意味着在可视化之前,您需要对大型数据集进行采样。你可以创建一个随机的多边形点连接结果样本,并将其转换为Pandas数据框架,并将其传递给Kepler.gl。
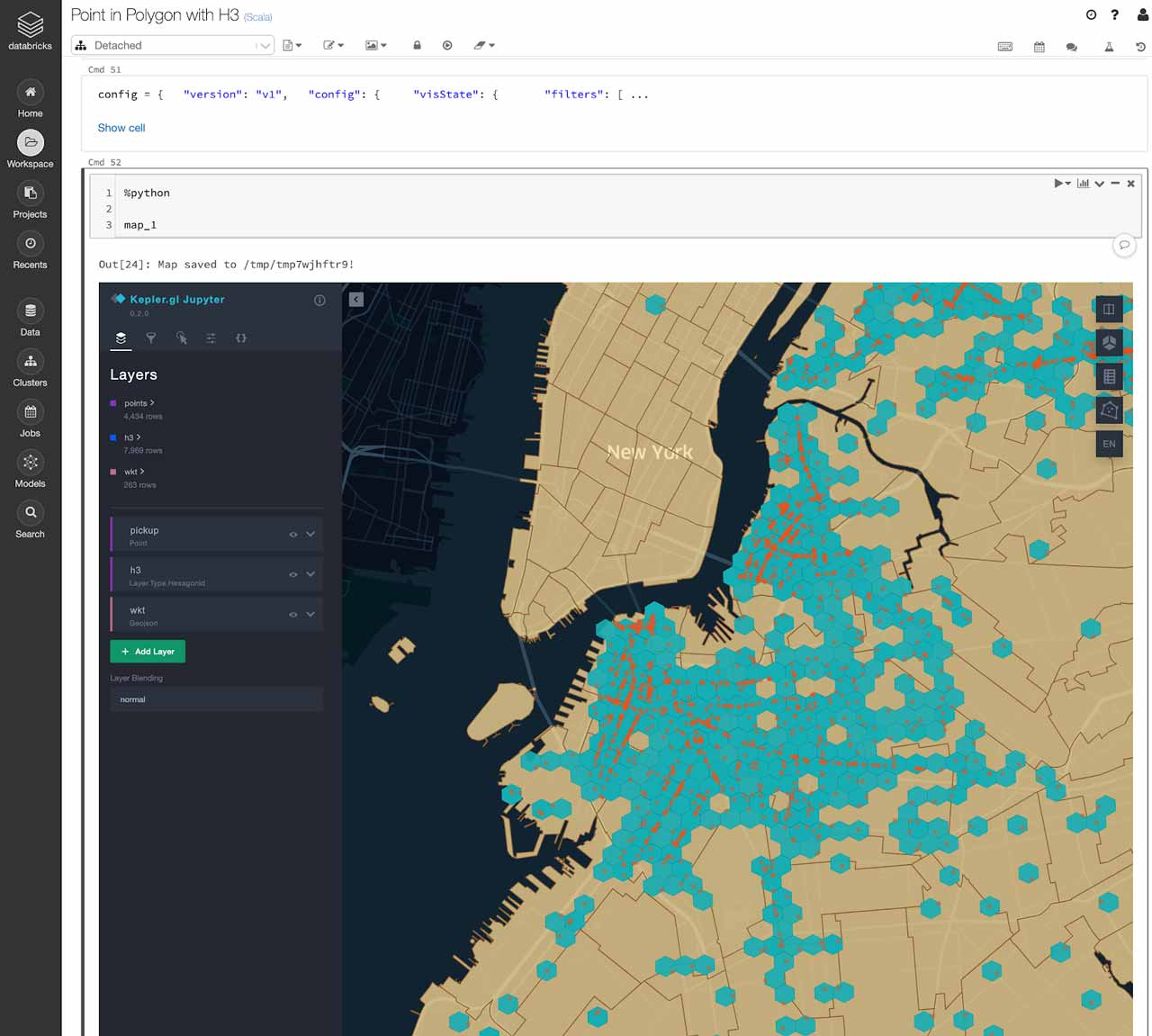
现在,您可以在Databricks笔记本电脑的地图上探索您的点、多边形和六边形网格。这也是验证多边形中点映射结果的好方法!
请注意:笔记本电脑在浏览器中浏览时可能无法正确显示。为获得最佳效果,请下载并在您的Databricks工作区中运行。
免费试用Databricks
相关的帖子