








改进供应链需求预测的新方法
带因果因素的细粒度需求预测
组织正在迅速接受细粒度需求预测
零售商和消费品制造商越来越多地寻求改善其供应链管理,以降低成本,释放流动资金,并为全渠道创新奠定基础。消费者购买行为的变化给供应链带来了新的压力。通过需求预测更好地了解消费者需求被认为是大多数这些工作的良好起点,因为对产品和服务的需求推动了有关劳动力、库存管理、供应和生产计划、货运和物流以及许多其他领域的决策。
在来自AI Frontier的注释麦肯锡公司强调,零售供应链预测精度提高10 - 20%,可能会使库存成本降低5%,收入增加2% - 3%。传统的供应链预测工具未能提供预期的结果。索赔行业平均不准确性为32%在零售商供应链需求预测中,即使是适度的预测改进,对大多数零售商的潜在影响也是巨大的。因此,许多组织正在远离预包装的预测解决方案,探索将需求预测技能引入内部的方法,并重新审视过去的实践,这些实践影响了预测准确性和计算效率。
这些工作的一个重点是在更细的时间和(位置/产品)层次粒度上生成预测。精细需求预测有可能捕捉到影响需求的模式,使其更接近必须满足的需求水平。在过去,零售商可能会在市场层面或分销层面预测一类产品的短期需求,为期一个月或一周,然后使用预测值来分配在给定的商店和一天中应该放置的一类特定产品的单位,细粒度需求预测允许预测者建立更多的本地化模型,反映特定产品在特定位置的动态。
精细谷物需求预测面临挑战
尽管精细需求预测听起来令人兴奋,但它也面临许多挑战。首先,通过远离总体预测,必须生成的预测模型和预测的数量会激增。所需的处理水平要么是现有预测工具无法达到的,要么是它大大超出了这些信息有用的服务范围。这种限制导致公司在处理的类别数量或分析中的谷物水平上做出权衡。
正如先前检查过的博客可以使用Apache Spark来克服这一挑战,允许建模人员并行化工作,以实现及时、高效的执行。当部署在Databricks等原生云平台上时,可以快速分配和bob体育客户端下载释放计算资源,将这项工作的成本控制在预算之内。
要克服的第二个更困难的挑战是理解在更细的粒度级别上检查数据时,总体上存在的需求模式可能不存在。用亚里士多德的话来说,整体往往大于各部分之和。当我们在分析中转向更低的细节级别时,在更高粒度级别上更容易建模的模式可能不再可靠地呈现,使得使用适用于更高级别的技术生成预测更具挑战性。在预测的背景下,这个问题被许多从业者注意到,一直追溯到亨利·赛尔在20世纪50年代。
当我们接近事务粒度级别时,我们还需要考虑影响个别客户需求和购买决策的外部因果因素。总的来说,这些可能反映在组成时间序列的平均值、趋势和季节性中,但在更细的粒度级别上,我们可能需要将这些直接纳入我们的预测模型中。
最后,移动到更细的粒度级别增加了数据结构不允许使用传统预测技术的可能性。我们越接近事务粒度,就越有可能需要处理数据中的不活动时期。在这种粒度级别上,我们的因变量,特别是在处理销售单位等计数数据时,可能会出现不适合简单转换的倾斜分布,这可能需要使用许多数据科学家所不熟悉的预测技术。
访问历史数据
为了研究这些挑战,我们将利用纽约市自行车共享计划的公共旅行历史数据Citi Bike NYC.Citi Bike NYC是一家承诺帮助人们“解锁自行车”的公司。解锁纽约。”他们的服务可以让人们去纽约市850多个不同的租赁地点中的任何一个地方租自行车。该公司有超过1.3万辆自行车库存,并计划将数量增加到4万辆。Citi Bike拥有超过10万名订户,每天骑行近1.4万次。
Citi Bike NYC将自行车从停放的地方重新分配到他们预计未来需求的地方。纽约市Citi Bike面临的挑战与零售商和消费品公司每天面临的挑战类似。我们如何最好地预测需求,将资源分配到正确的领域?如果我们低估了需求,就会错失盈利机会,并可能损害客户的信心。如果我们高估了需求,我们就有多余的自行车库存没有使用。
这个公开的数据集提供了从上月末到2013年年中该项目开始时的每一次自行车租赁信息。行程历史数据确定了从特定出租站租用自行车的确切时间,以及将自行车归还到另一个出租站的时间。如果我们将Citi Bike NYC项目中的站点视为门店位置,并将租赁的开始视为交易,那么我们就有了一个非常接近于长期而详细的交易历史的东西,我们可以根据它进行预测。
作为这个练习的一部分,我们将需要识别外部因素,并将其纳入我们的建模工作中。我们将利用假日事件以及历史(和预测的)天气数据作为外部影响因素。对于假日数据集,我们将简单地使用假期图书馆在Python中。对于天气数据,我们将使用每小时提取的视觉交叉是一个流行的天气数据聚合器。
Citi Bike NYC和Visual Crossing数据集有条款和条件,禁止我们直接共享他们的数据。那些希望重现我们结果的人应该访问数据提供商的网站,查看他们的条款和条件,并以适当的方式将他们的数据集下载到他们的环境中。我们将提供将这些原始数据资产转换为我们分析中使用的数据对象所需的数据准备逻辑。
检查事务数据
截至2020年1月,Citi Bike NYC自行车共享计划包括864个活跃的站点,在纽约市大都市区运营,主要在曼哈顿。仅在2019年,客户发起的独立租赁次数就略高于400万次,高峰日的租赁次数多达近1.4万次。
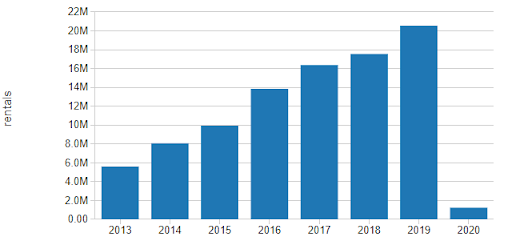
自该计划启动以来,我们可以看到出租的数量逐年增加。这种增长部分可能是由于自行车利用率的增加,但大部分似乎与整个车站网络的扩张有关。
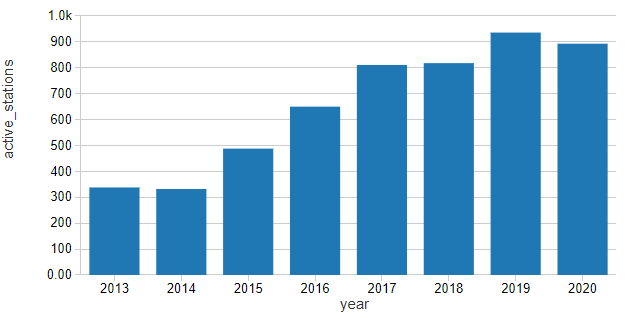
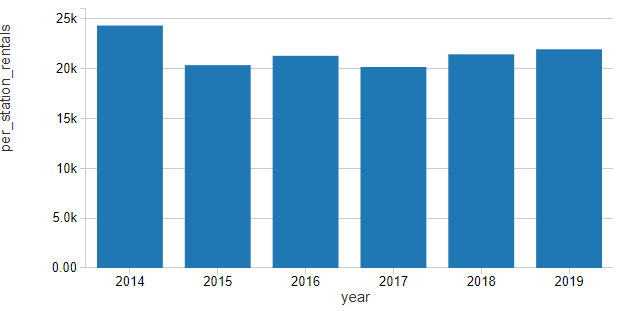
通过网络中活跃站点的数量来标准化租金,可以看出在过去几年里,每个站点的客流量一直在缓慢增长,我们可以认为这是一个轻微的线性上升趋势。
使用这个租金的标准化值,客流量似乎遵循一个明显的季节性模式,在春季、夏季和秋季上升,然后在冬季下降,因为室外的天气变得不太适合骑自行车
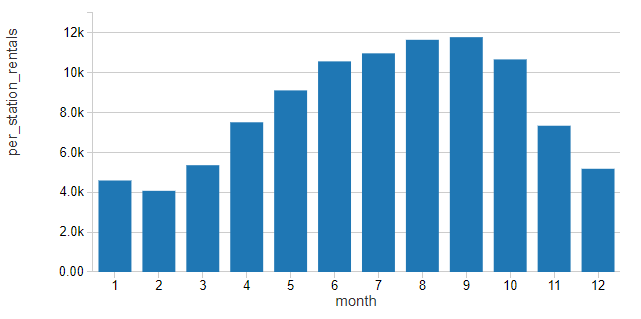
他的模式似乎与该城市最高温度(华氏度)的模式密切相关。

虽然很难将每月的客流量与气温模式区分开来,但降雨量(以月平均英寸为单位)并不能很容易地反映这些模式
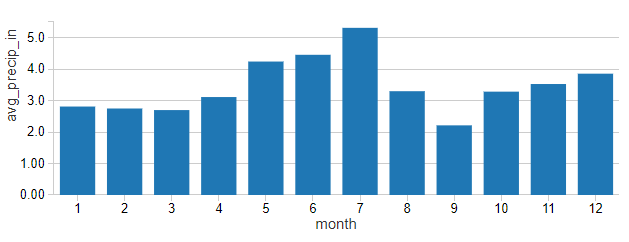
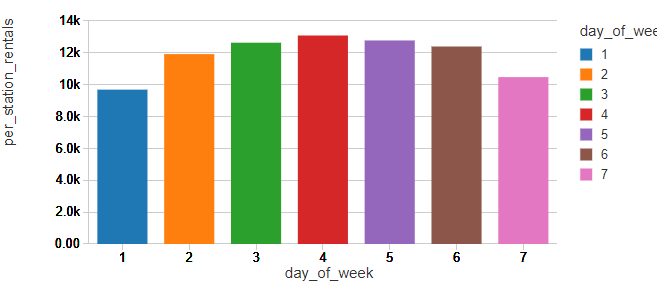
根据周日为1,周六为7的每周骑行模式,纽约人似乎把自行车作为通勤工具,这种模式在许多其他自行车共享项目中都能看到。
按小时划分这些客流量模式,我们可以看到明显的工作日模式,在标准通勤时间客流量峰值。在周末,模式表明更悠闲地使用程序,支持我们之前的假设。
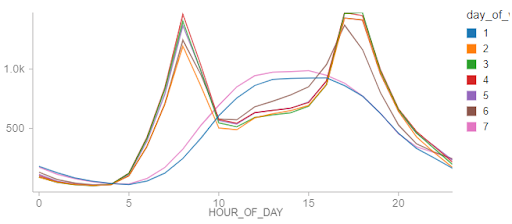
一个有趣的现象是,无论假日是星期几,它所显示的消费模式都大致与周末的使用模式相似。假日的不频繁出现可能是这些趋势不稳定的原因。不过,这张图表似乎表明,节假日的确定对于做出可靠的预测是很重要的。
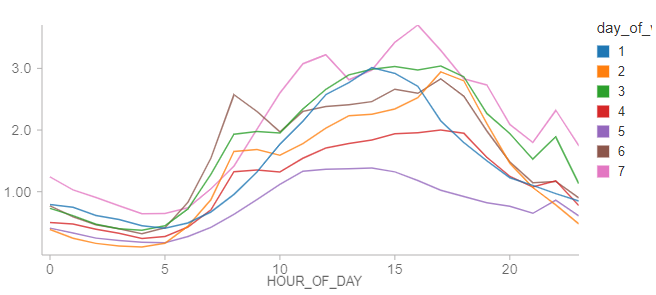
总的来说,每小时的数据似乎表明纽约市确实是一个不夜城。在现实中,有许多车站有很大一部分时间没有自行车出租。
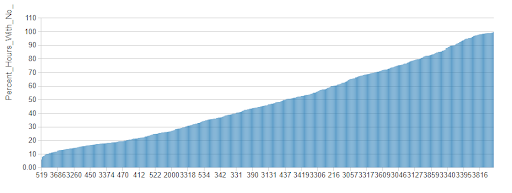
在试图进行预测时,这些活动的差距可能会产生问题。通过将间隔时间从1小时改为4小时,各个站点没有租赁活动的时段数量大幅下降,尽管在这段时间内仍有许多站点处于不活跃状态。
我们将尝试以小时为单位进行预测,探索替代预测技术如何帮助我们处理这个数据集,而不是通过转向更高级别的粒度来回避不活跃期的问题。由于预测大部分不活跃的站点并不是特别有趣,我们将把分析限制在最活跃的200个站点上。
使用Facebook Prophet预测共享单车租赁
在最初尝试预测每个站点的自行车租赁情况时,我们使用了Facebook的先知,一个流行的用于时间序列预测的Python库。该模型被配置为探索具有每日、每周和每年季节性模式的线性增长模式。数据集中与节假日相关的时段也被识别出来,这样这些日期的异常行为就不会影响算法检测到的平均值、趋势和季节模式。
使用之前引用的博客文章中记录的横向扩展模式,对200个最活跃的站点的模型进行了训练,并为每个站点生成了36小时的预报。总的来说,这些模型的均方根误差(RMSE)为5.44,平均比例误差(MAPE)为0.73。(MAPE计算将零值实际调整为1。)
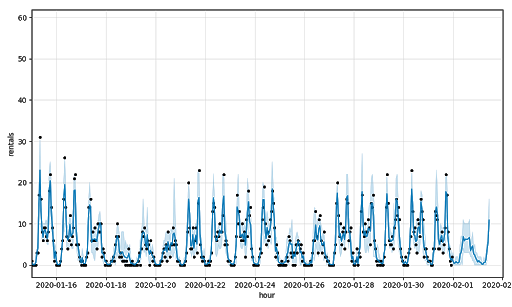
这些指标表明,这些模型在预测租金方面做得相当不错,但当每小时租金上涨时,这些模型就不存在了。将单个站点的销售数据可视化,您可以通过图形化方式看到这一点,例如E 39 St & 2 Ave 518站点的图表,其RMSE为4.58,MAPE为0.69:
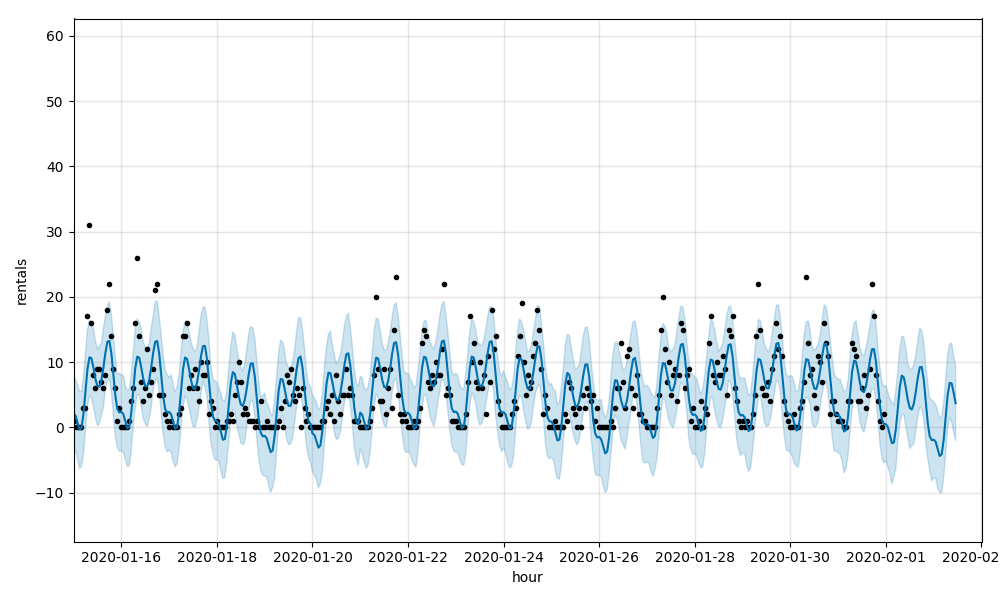
然后对模型进行了调整,将温度和降水作为回归因子。总的来说,所得预测的RMSE为5.35,MAPE为0.72。虽然有很小的改善,但模型仍然难以在车站层面发现客流量的大幅波动,正如518站再次证明的那样,其RMSE为4.51,MAPE为0.68:
这种模式的难度建模较高的值在两个时间序列模型是典型的处理数据的泊松分布.在这样的分布中,我们将在平均值周围有大量的值,在平均值之上有长尾值。在平均值的另一边,零底部会使数据产生偏差。今天,Facebook Prophet希望数据具有正态分布(高斯分布)计划对泊松回归的引入进行了讨论。
预测供应链需求的替代方法
那么我们如何继续对这些数据进行预测呢?Facebook Prophet的管理者正在考虑的一种解决方案是,在传统时间序列模型的背景下利用泊松回归功能。虽然这可能是一种很好的方法,但它并没有被广泛记录,因此在考虑其他技术之前自行解决这个问题可能不是满足我们需求的最佳方法。
另一个潜在的解决方案是对非零值的规模和零值周期出现的频率进行建模。然后可以将每个模型的输出组合成一个预测。这种方法被称为Croston方法,最近发布的Python库而另一位数据科学家已经实现了他自己的功能为它。然而,这并不是一种被广泛采用的方法(尽管该技术可以追溯到20世纪70年代),我们的偏好是探索更多的东西开箱即用的.
考虑到这种偏好,随机森林回归器似乎有相当大的意义。一般来说,决策树不会像许多统计方法那样对数据分布施加相同的约束。预测变量的值范围是这样的,在训练模型之前使用像平方根变换这样的东西来转换租金可能是有意义的,但即使这样,我们可能会看到算法在没有它的情况下表现如何。
为了利用这个模型,我们需要设计一些特性。从探索性分析中可以明显看出,无论是在年度、每周还是每天的水平上,数据都存在强烈的季节性模式。这导致我们提取年、月、星期的一天和一天中的小时作为特征。我们还可以加入一面假日旗帜。
使用随机森林回归器和时间衍生特征,我们得到了总体RMSE为3.4,MAPE为0.39。518站的RMSE和MAPE值分别为3.09和0.38:
通过利用降水和温度数据,结合这些相同的时间特征,我们能够更好地(尽管不是完美地)解决一些较高的租金值。518站的RMSE下降到2.14,MAPE下降到0.26。总体而言,RMSE降至2.37,MAPE降至0.26,表明天气数据在预测自行车需求方面是有价值的。
研究结果的意义
更细粒度级别的需求预测可能需要我们以不同的方式思考建模方法。外部影响因素可能被安全地认为是总结在高水平的时间序列模式中,可能需要更明确地纳入我们的模型。隐藏在聚合级别的数据分布模式可能变得更容易暴露,并需要对建模方法进行更改。在这个数据集中,这些挑战最好的解决办法是包括每小时的天气数据,并从传统的时间序列技术转向对输入数据进行较少假设的算法。
可能还有许多其他的外部影响因素和算法值得探索,当我们沿着这条路走下去时,我们可能会发现其中一些对我们的某些数据子集比其他数据更好。我们可能还会发现,随着新数据的到来,以前工作良好的技术可能需要被放弃,而需要考虑新的技术。
我们在客户探索细粒度需求预测时看到的一个常见模式是在每个训练和预测周期中评估多种技术,我们可以将其描述为自动模型烘烤。在决胜轮中,为给定数据子集产生最佳结果的模型赢得这轮比赛,每个子集都能够决定自己的获胜模型类型。最后,我们希望确保我们正在执行良好的数据科学,其中我们的数据与我们所使用的算法正确对齐,但正如一篇又一篇文章所指出的那样,问题的解决方案并不总是只有一种,有些解决方案可能在同一时间比其他解决方案更好。我们今天所拥有的Apache Spark和Databricks等平台的强大之处在于,我们可以利bob体育客户端下载用计算能力来探索所有这些路径,并为我们的业务提供最佳解决方案。
额外的零售/CPG和需求预测资源
- 报名参加免费试用下载这些笔记本开始尝试吧:
- 下载我们的零售和CPG的大规模数据分析和人工智能指南
- 访问我们的零售和CPG页面了解Dollar Shave Club和Zalando如何利用Databricks进行创新
- 阅读我们最近的博客使用Facebook Prophet和Apache Spark进行大规模细粒度时间序列预测学习如何Databricks统一数据分析平台bob体育客户端下载及时解决挑战,并在粒度级别上允许业务对产品库存进行精确调整
免费试用Databricks
相关的帖子