





介绍砖摄取:简单和有效的摄入来自不同数据源的数据到三角洲湖
2020年2月24日
通过普拉卡什Chockalingam
在
工程的博客
我们兴奋地介绍一个新功能——自动加载器和一组合作伙伴集成,在公共预览,……
2020年2月24日 在工程的博客
我们兴奋地介绍一个新功能——自动加载器和一组合作伙伴集成,在公共预览,让砖用户数据增量地摄取到三角洲湖从不同的数据源。自动加载器是一个优化的云文件来源Apache火花加载数据的持续高效地从云存储新数据到来。数据摄取的网络合作伙伴集成允许你摄取来自数百个数据源的数据直接进入三角洲湖。
组织大量的孤立的在不同数据源的信息。这些可以从数据库(例如Oracle、MySQL、Postgres等)产品应用(Salesforce、Marketo HubSpot的等)。大量的分析用例需要来自这些不同数据源的数据产生有意义的报告和预测。举例来说,一个完整的漏斗从域分析报告需要信息的来源从导致信息在hubspot的产品Postgres数据库中注册事件。
只有在集中你所有的数据数据仓库是一种反模式,因为机器学习框架在Python / R库将无法有效地访问数据仓库。因为你的分析用例范围从构建简单的SQL报告更先进的机器学习预测,至关重要的是,您构建一个湖中央数据在一个开放的和来自你的所有数据源的数据格式,使其可用于各种用例。
自从我们去年开源三角洲湖,有数以千计的组织构建这个湖中央数据在一个开放的格式比以前更加可靠和有效的。三角洲湖上砖提供ACID事务和高效的索引,对暴露不同的数据访问模式至关重要,在BI工具从特定的SQL查询,预定的离线训练工作。我们称之为模式建立一个中央,可靠和有效的单一的事实来源的数据在一个开放的格式用例从BI毫升与解耦的存储和计算“Lakehouse”。
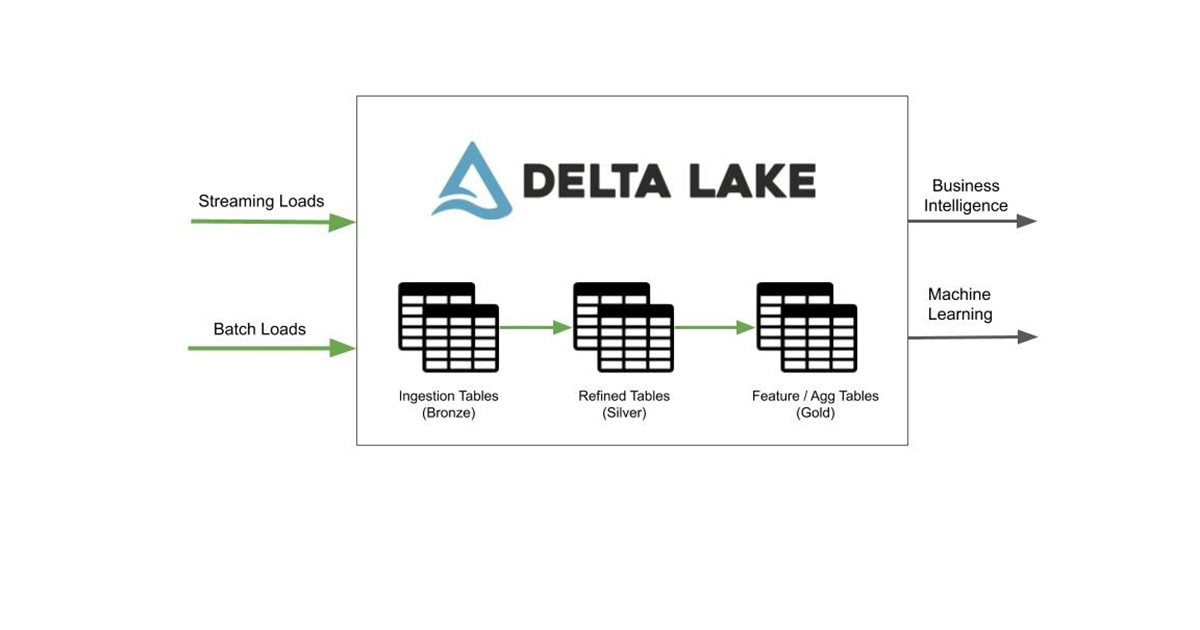
在建立lakehouse一个关键挑战是将来自不同源的数据集中在一起。根据你的数据,有两种常见的场景数据团队:
摄入来自内部数据源的数据需要为他们每个人写专业的连接器。这可能是一个巨大的投资时间和精力构建连接器使用源api和映射源模式三角洲湖的模式功能。此外,您还需要维护这些连接器的api和模式进化来源。化合物的维护问题与每一个额外的数据源。
方便您的用户访问你所有的数据在三角洲湖,我们现在与一组数据摄入的产品。这个网络的数据摄入合作伙伴建立了本地与砖摄取和储存的数据集成在bob体育外网下载三角洲湖直接在你的云存储。这有助于您的数据科学家和分析师轻松地开始使用来自不同数据源的数据。
Azure砖顾客已经从中受益与Azure数据工厂的集成摄取来自各种数据源的数据到云存储。我们兴奋地宣布新的合作伙伴bob体育外网下载Fivetran,Qlik,Infoworks,StreamSets,Syncsort——帮助用户接收来自各种数据源的数据。我们也扩大这个数据摄入的网络合作伙伴集成来自Informatica很快,缝合。bob体育外网下载

增量处理新数据落在云blob存储和使它准备在ETL工作负载分析是一种常见的工作流。然而,加载数据不断从云blob存储只有一次担保以低成本,低延迟,和以最小的DevOps工作,是难以实现的。
一旦在三角洲表数据,由于三角洲湖的ACID事务,数据可以可靠地阅读。从三角洲流数据表,您可以使用δ源(Azure|AWS),利用表的事务日志快速识别新添加文件。
然而,加载原始文件的主要瓶颈是土地在云存储到三角洲表。天真的基于文件的流源(Azure|AWS)确定新文件清单云目录和反复跟踪文件都已看到。成本和延迟快速添加越来越多的文件可以添加到一个目录将重复的文件清单。为了克服这个问题,数据团队通常归结为其中一个解决方法:
自动加载器是一个优化文件来源,克服上述限制和数据团队提供了一个无缝的方式以低成本和延迟加载原始数据以最小的DevOps的努力。你只需要提供一个源目录路径和启动一个流媒体工作。新的结构化流源,称为“cloudFiles”,将自动设置文件通知订阅的服务从输入目录和文件事件过程为到达的新文件,选择也处理现有的文件目录。
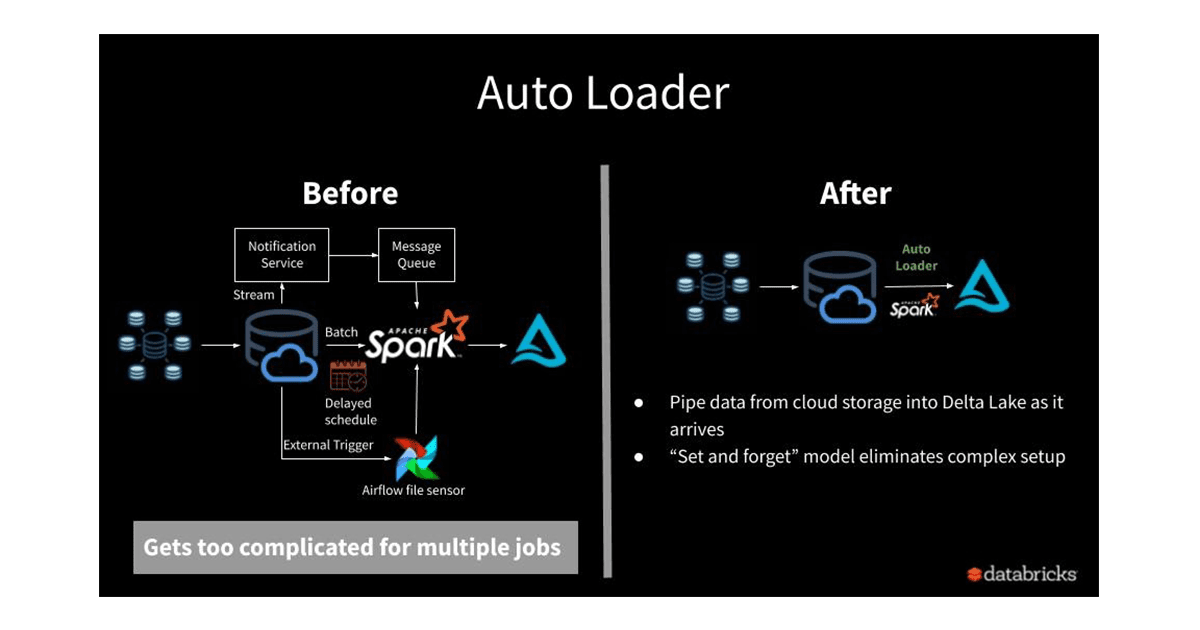
你可以开始使用最少的代码更改利用流媒体工作Apache火花的熟悉的api加载:
spark.readStream。格式(“cloudFiles”).option (“cloudFiles.format”,“json”).load (“/输入/路径”)如果你有数据只有一次每隔几个小时,您仍然可以利用汽车装载机使用预定的工作结构化流的触发器。一旦模式。
val df = spark.readStream。格式(“cloudFiles”).option (“cloudFiles.format”,“json”).load (“/输入/路径”)
df.writeStream.trigger (Trigger.Once)。格式(“δ”).start(“/输出/路径”)你可以安排上面的代码运行在一个每小时或每天安排加载新数据逐步使用砖工作调度器(Azure|AWS)。你不需要担心晚到达数据场景使用上面的方法。
用户喜欢使用声明性语法可以使用SQL复制命令将数据加载到三角洲湖在预定的基础上。复制命令是幂等的,因此可以安全地重新运行失败。命令自动忽略了以前装载的文件并保证只有一次语义。这使数据团队轻松地构建健壮的数据管道。
语法如下所示的命令。更多细节,请参阅文档复制命令(Azure|AWS)。
复制成tableIdentifier从{位置|(选择identifierList从位置)}FILEFORMAT={CSV|JSON|AVRO|兽人|镶木地板}(文件=(”(,”][,……)))(模式=”][FORMAT_OPTIONS (“dataSourceReaderOption”=“价值”,……)[COPY_OPTIONS (“力”={“假”,“真正的”}))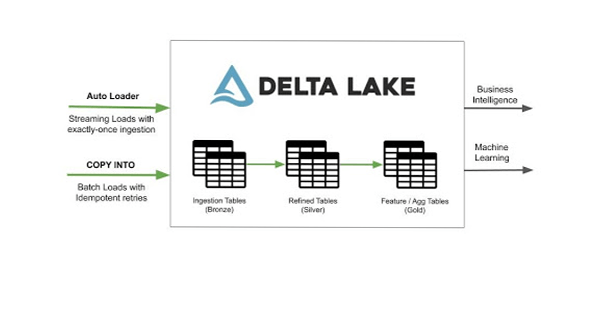
湖获取所有的数据到你的数据是至关重要的对机器学习和业务分析用例成功并为每个组织是一个艰巨的任务。我们兴奋地介绍汽车装载机和合作伙伴的集成功能,可以帮助我们的成千上万的用户在这个构建一个高效的数据湖之旅。今天可以预览的特性。我们的文档的更多信息关于如何开始使用合作伙伴集成(Azure|AWS),自动加载器(Azure|AWS)和复制命令(Azure|AWS开始你的数据加载到三角洲湖)。
更多地BOB低频彩了解这些功能,我们将举办一个研讨会在十时整3/19/2020 @ PST预排砖摄取的能力,注册在这里。