


介绍数据摄取:简单和有效的数据摄取从不同来源到三角洲湖
2020年2月24日
通过普拉卡什Chockalingam
在
工程的博客
我们很高兴地介绍一个新功能-自动加载器-和一组合作伙伴集成,在公开预览中,那…
大多数业务决策都是时间敏感的,需要实时利用来自不同类型来源的数据。在正确的时间获取正确的数据是实现及时决策的关键。时间敏感数据源分布在不同的技术中,包括物联网传感器、社交媒体、点击流、数据库中的变更数据捕获等。为了从这些数据中获得关键的见解,必须首先将其摄入湖屋。这些数据的关键特征是以一种无限的方式连续到达流媒体.在这篇博客中,我们将重点介绍流数据是如何被吸收到湖屋的。
来自不同数据源的流数据在输入到湖屋之前暂存到消息总线系统或云对象存储中。来自暂存区域的数据由Apache Spark Structured Streaming (SS)管道消耗,该管道将数据写入湖屋。有两种突出的登台环境——云对象存储和消息总线系统,下面将讨论它们。
图1显示了从这两个关键数据登台环境向湖屋输入流数据的高级体系结构。
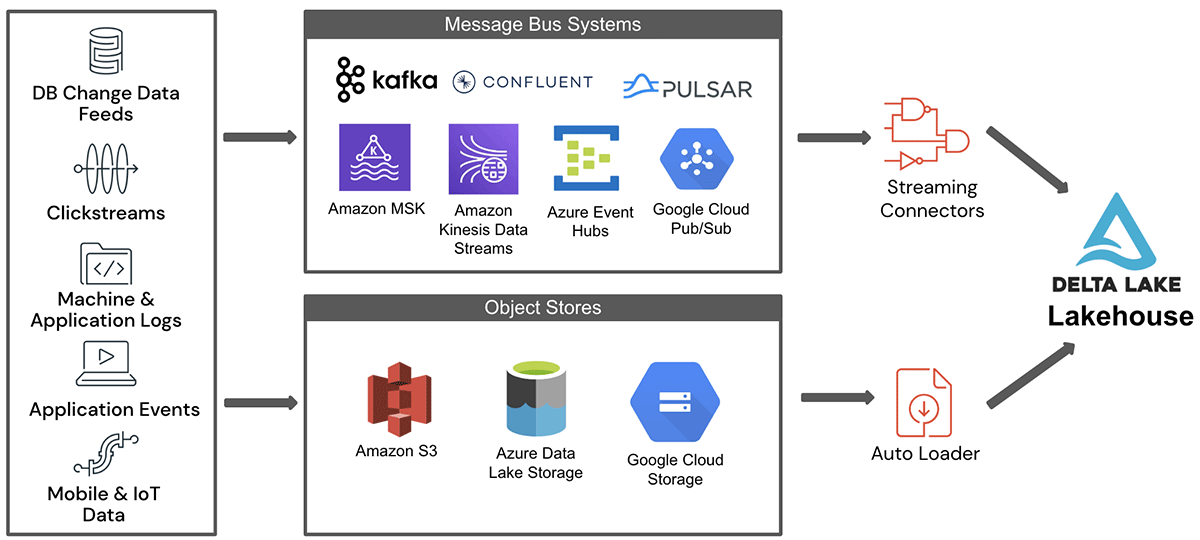
如图所示,来自不同源系统的数据首先到达对象存储区或消息总线中的一个暂存区域。通过用于消息总线的流连接器或用于对象存储的自动加载器,这些数据被摄取到lakehouse中。Delta活动表(DLT)是一种简单的声明性方法,用于创建可靠的数据管道,并全面管理用于批处理和流数据的大规模底层基础设施。它也是基于Spark结构化流的,在本博客中不做介绍。在随后的小节中,我们将详细描述从这些源摄取流数据时所涉及的一些挑战。
通常,文件与批数据摄取相关联。然而,以文件形式将来自各种来源的连续数据摄取到基于云的对象存储中通常是一种常见模式。通常,对于需要接近实时处理的用例,这种模式是首选,其中预期的延迟可能在几分钟内。此外,还需要非功能性需求,例如只进行一次处理、对失败的摄取作业进行重新处理、时间旅行和模式漂移。
为了说明从云对象存储加载到lakehouse的挑战,让我们考虑一个实时信用卡支付处理系统,该系统用于改善客户体验和检测支付欺诈。通常,来自不同支付渠道的事务被批处理到对象存储中的文件中。这些文件需要被输入到lakehouse中进行进一步的下游处理。由于这些是支付事务,我们需要确保它们只被处理一次,并提供重新处理失败的事务而不重复的条款。如果要在AWS云中处理这些数据,则需要一个复杂的架构,其中包括:
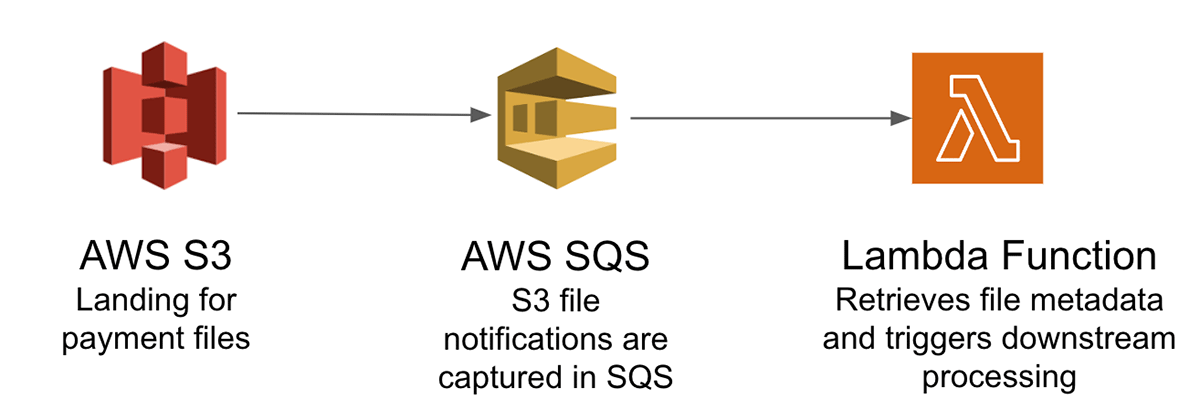
主要的挑战是跟踪对象存储中的大量文件,只对这些文件中的数据进行一次处理,并管理来自不同支付渠道的不同模式。
Auto Loader在新数据文件到达云对象存储时对其进行增量处理,从而简化了流数据的输入,并且不需要用户编写自定义应用程序。它通过维护内部状态来跟踪到目前为止处理的文件。在失败的情况下,它使用状态从最后处理的文件开始。此外,如果需要重放或重新处理数据,它提供了一个选项来处理目录中现有的文件。Auto Loader的主要好处是:
Auto Loader支持两种检测新文件的模式:文件通知和目录列表。
文件的通知: Auto Loader可以自动设置一个通知和队列服务,订阅来自输入目录的文件事件。文件通知模式对于具有大量文件的输入目录具有更高的性能和可伸缩性,但需要额外的云权限。当文件不是按词法顺序到达时,这个选项更好,并且避免了显式设置队列和通知的需要。要启用该模式,需要设置该选项cloudFiles.useNotifications并提供创建云资源所需的权限。请参阅有关文件通知的详细信息在这里.
目录清单:另一种识别新文件的方法是列出在Auto Loader中配置的输入目录。目录列表模式允许您启动自动加载器流,而不需要访问您的数据以外的任何其他权限配置。从Databricks Runtime 9.1开始,Auto Loader可以自动检测文件是否按照词法顺序到达云存储,并显著减少检测新文件所需的API调用量。在默认模式下,它在每连续七次增量目录清单之后触发完整目录清单。但是,可以通过设置配置来调整完整目录列表的频率cloudFiles.backfillInterval.可以通过设置配置显式启用或禁用增量清单cloudFiles.useIncrementalListing.当显式启用此配置时,Auto Loader将不会触发完整的目录清单。有关目录列表的详细信息在这里.
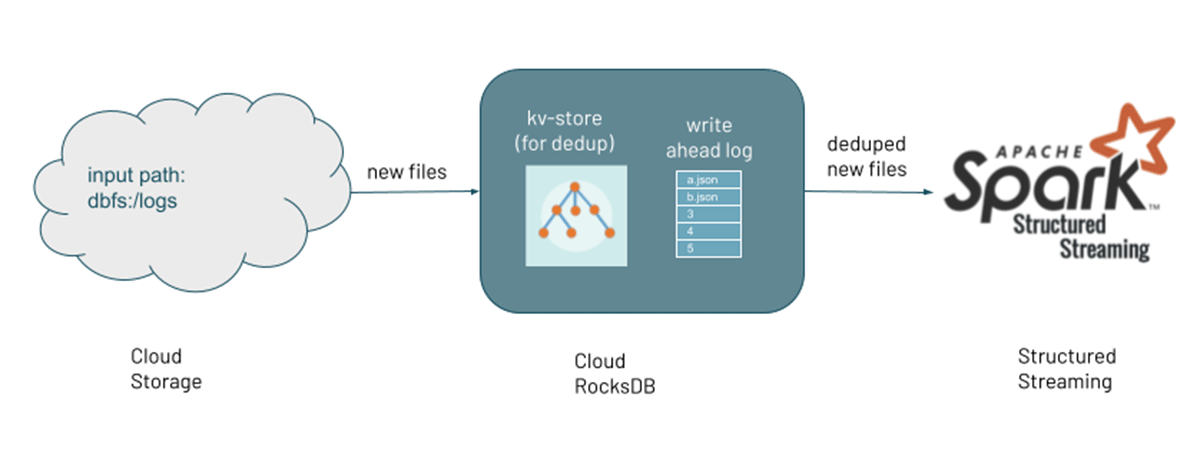
当发现新文件时,它们的元数据将保存在Auto Loader管道检查点位置的可伸缩键值存储(RocksDB)中。这作为跟踪到目前为止处理的文件的状态。管道既可以对包含现有文件的目录执行回填,也可以并发处理通过文件通知发现的新文件。
流数据在本质上通常是无界的。该数据暂存于消息总线中,充当缓冲区,并提供异步通信方法,多个生产者可以写入其中,许多消费者可以从中读取。消息总线广泛用于低延迟用例,如欺诈检测、金融资产交易和游戏。流行的消息总线服务包括Apache Kafka、Apache Pulsar、Azure eventubs、Amazon Kinesis和谷歌云Pub/Sub。然而,连续的数据摄取带来了诸如可伸缩性、弹性和容错等挑战。
为了从消息总线摄取到lakehouse,一个显式的Spark Structured Streaming (SS)管道被实例化,其中包含消息总线的适当源连接器和lakehouse的接收器连接器。这种情况下的关键挑战是吞吐量和容错能力。
让我们来讨论一些来自这些来源的常见摄入模式。尽管消息总线对于实时处理用例来说是一个很好的选择,但大多数应用程序都需要在延迟、吞吐量、容错需求和成本之间取得平衡。我们将详细介绍这些设计选择:
延迟:实现更低的延迟并不总是更好。相反,你可以通过选择合适的延迟、准确性和成本权衡来降低成本。Spark结构化流处理由触发器增量控制的数据,触发器定义流数据处理的时间。Spark结构化流作业的低延迟是通过较低的触发间隔实现的。建议你配置结构化流的触发间隔平衡延迟需求和数据到达源的速率。如果您指定的触发间隔非常低,系统可能会执行不必要的检查来查看是否有新数据到达。
Spark Structured Streaming提供了三个触发类型:
默认:默认情况下,Spark结构化流处理下一批处理前一批完成。在大多数用例中,默认值将适合您的需求。
固定时间间隔:使用固定时间间隔,可以按照用户指定的时间间隔处理作业。通常使用固定的间隔来等待特定的时间并运行较大的微批处理。
一次:有时,数据在固定的时间间隔到达,保持集群全天正常运行将是一种资源浪费。其中一个选项是以批处理模式运行作业。然而,在触发器中执行Spark结构化流作业一次或AvailableNow模式对整个批处理都是有益的。通过这些执行设置,不需要保持集群运行,并且可以通过定期旋转集群、处理数据和关闭集群来显著节省成本。尽管它类似于批处理作业,但它提供了额外的好处,例如对正在处理的数据进行簿记管理、通过维护表级原子性来容错以及跨运行的有状态操作。
吞吐量:在Spark结构化流中,有多个参数可以调优以实现高吞吐量。除了选择触发器类型外,一个关键参数是数据摄取作业的并行处理。要实现更高的吞吐量,可以增加消息总线上的分区数量。通常Spark在消息总线分区和Apache Kafka的Spark结构化流分区之间有一对一的映射。但是在AWS Kinesis的情况下,消息是在内存中预取的,Kinesis Shards的数量和Spark任务的数量之间没有直接的映射。
让我们考虑一个真实的例子,其中通过调优批大小和分区数量实现了更高的吞吐量。在一个银行用例中,使用流作业全天处理实时事务。然而,实时接收到的事件很少可能是不准确的。因此,在一天结束时执行了一个和解批处理来修复问题。使用相同的流代码但不同的作业实例处理了对账批处理。在另一个主题中,与连续流数据相比,增加了分区数量和批处理大小以实现高吞吐量。
容错:当Spark Structured Streaming以微批量执行作业时,它提供了两个明显的优势来实现容错:
在Spark结构化流中,失败作业的恢复是使用每个查询的检查点位置来实现的。检查点位置内的偏移量使您能够从确切的故障点重新启动作业。在查询中提供检查点位置的选项是:
选项(“checkpointLocation”、“dbfs: / / checkpointPath”)
通过可重玩源和幂等接收器,Spark Structured Streaming作业可以实现恰好一次的语义,这通常是生产级应用程序的要求。
流数据摄取是在湖屋中实现时间敏感决策的第一步。在本博客中,我们将流数据源分类为连续的文件流或消息总线服务。Auto Loader使用Spark Structured Streaming简化了来自文件源的近乎实时的摄取,并提供了高级功能,如文件到达的自动检测、处理大量数据的可伸缩性、模式推断和成本效益高的数据摄取。而对于来自消息总线服务的数据摄取,Spark Structured Streaming支持健壮的数据摄取框架,该框架集成了跨不同云提供商的大多数消息总线服务。大多数生产级应用程序需要在延迟和吞吐量之间进行权衡,以最小化成本并实现更高的精度。



