Delta Live Tables (DLT) 是第一个使用简单的声明式方法来创建可靠数据管道的ETL框架,并为批处理和流数据 .许多用例需要从近实时数据中获得可操作的见解。Delta Live Tables支持低延迟流数据管道 通过从事件总线直接摄取数据来支持低延迟的用例Apache卡夫卡 ,AWS运动 ,汇合的云 ,亚马逊MSK的 ,或Azure事件中心 .
本文将介绍如何在Apache Kafka中使用DLT,同时提供摄取流所需的Python代码。本文将介绍推荐的系统架构,并探讨值得考虑的相关DLT设置。
流媒体平台bob体育客户端下载
事件总线或消息总线将消息生产者与消费者分离。一个流行的流用例是用户浏览网站时的点击数据集合,其中每个用户交互都作为事件存储在Apache Kafka中。然后,来自Kafka的事件流用于实时流数据分析。多个消息消费者可以从Kafka读取相同的数据,并使用这些数据了解受众的兴趣、转化率和反弹原因。来自用户交互的实时流事件数据通常还需要与存储在计费数据库中的实际购买相关联。
Apache卡夫卡
Apache卡夫卡 是一种流行的开源事件总线。bob下载地址Kafka使用了主题的概念,这是一种仅可追加的分布式事件日志,其中消息将被缓冲一定的时间。尽管Kafka中的消息在被使用后不会被删除,但它们也不会被无限期地存储。Kafka的消息保留可以配置为每个主题,默认为7天。过期的消息将最终被删除。
本文围绕Apache Kafka展开;然而,所讨论的概念也适用于许多方面其他事件总线或消息传递系统 .
流数据管道
在数据流管道中,可以使用标准的SQL Create Table As Select (CTAS)语句和DLT关键字“Live”声明Delta Live表及其依赖项。
在使用Python开发DLT时,使用@dlt.tabledecorator用于创建Delta Live Table。为了确保管道中的数据质量,DLT使用预期 它们是简单的SQL约束子句,用无效记录定义管道的行为。
由于流工作负载通常会带来不可预测的数据量,Databricks采用增强自动定量 对于数据流管道来说,通过关闭不必要的基础设施来降低成本,从而最大限度地减少整体端到端延迟。
Delta活动表 以正确的顺序对每个管道运行完全重新计算一次。
相比之下,流媒体Delta Live Tables 是有状态的、增量计算的,并且只处理自上次管道运行以来添加的数据。如果定义流式活动表的查询更改,则将基于新的查询处理新数据,但不会重新计算现有数据。流式实时表总是使用流式源,并且只能在仅追加的流上工作,例如Kafka、Kinesis或Auto Loader。流dlt是基于Spark结构化流的。
您可以链接多个流管道,例如,具有非常大的数据量和低延迟要求的工作负载。
从流引擎直接摄取
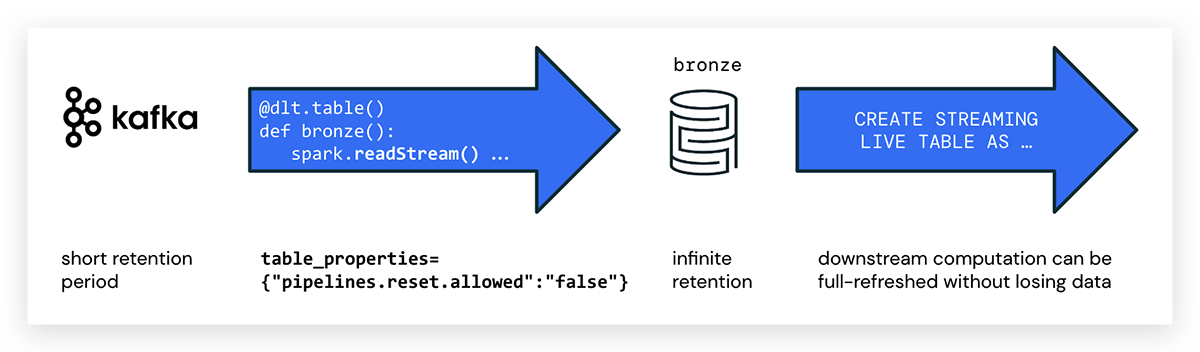
用Python编写的Delta Live表可以使用Spark结构化流直接从Kafka等事件总线中摄取数据。您可以为Kafka主题设置一个较短的保留期,以避免遵从性问题,降低成本,然后受益于Delta提供的廉价、弹性和可治理的存储。
作为管道中的第一步,我们建议将数据原样吸收到青铜(原始)表中,并避免可能丢失重要数据的复杂转换。像任何Delta表一样,青铜表将保留历史记录,并允许执行GDPR和其他合规任务。
从Apache Kafka摄取流数据
在Python中编写DLT管道时,使用@dlt.table注释来创建DLT表。Python中没有标记流dlt的特殊属性;简单地使用spark.readStream ()访问流。创建名称为的DLT表的示例代码kafka_bronze从Kafka主题中消费数据,如下所示:
进口 dlt 从 pyspark.sql.functions 进口 * 从 pyspark.sql.types 进口 * 主题= “tracker-events” KAFKA_BROKER = spark.conf.get( “KAFKA_SERVER” ) #在KAFKA_BROKER订阅TOPIC . 格式 ( “卡夫卡” ) .option ( “订阅” 、主题) .option ( “kafka.bootstrap.servers” KAFKA_BROKER) .option ( “startingOffsets” , “最早” ) .load ())@dlt.table ( table_properties = { “pipelines.reset.allowed” : “假” } ) def kafka_bronze (): 返回 raw_kafka_events pipelines.reset.allowed
注意,事件总线通常在一段时间后使消息过期,而Delta是为无限保留而设计的。
这可能会导致Kafka上的源数据在运行DLT管道的完全刷新时已经被删除。在这种情况下,并非所有历史数据都可以从消息传递平台回填,并且DLT表中会缺少数据。bob体育客户端下载为了防止数据丢失,使用以下DLT表属性:
pipelines.reset.allowed = false
设置pipelines.reset.allowedfalse阻止对表的刷新,但不阻止对表的增量写操作或新数据流入表。
检查点
如果你是一个有经验的Spark结构化流开发人员,你会注意到上面的代码中没有检查点。在Spark结构化流中,需要使用检查点来持久化关于已成功处理的数据的进度信息,并且在失败时,此元数据用于重新启动失败的查询。
在Spark结构化流中,检查点对于只有一次保证的故障恢复是必要的,而DLT自动处理状态,不需要任何手动配置或显式检查点。
混合SQL和Python的DLT管道
DLT管道可以由多个笔记本组成,但一个DLT笔记本需要完全用SQL或Python编写(不像其他Databricks笔记本,在一个笔记本中可以有不同语言的单元格)。
现在,如果你的偏好是SQL,你可以在一个笔记本上用Python编写来自Apache Kafka的数据摄取,然后在另一个笔记本上用SQL实现数据管道的转换逻辑。
模式映射
从消息平台读取数据时,数据流是不透明的,必须提供模式。bob体育客户端下载
下面的Python示例显示了来自健身跟踪器的事件的模式定义,以及的值部分如何Kafka消息映射 对那个图式来说。
StructField ( “时间” 、TimestampType () 真正的 ), \ StructField ( “版本” 、StringType () 真正的 ), \ StructField ( “模型” 、StringType () 真正的 ), \ StructField ( “heart_bpm” 、IntegerType () 真正的 ), \ StructField ( “千卡” 、IntegerType () 真正的 ) \ ])
#临时表,在管道中可见,但在数据浏览器中不可见 #不能交互查询 @dlt.table ( 评论= “Kakfa有效载荷的真实模式” , 临时= 真正的 ) def kafka_silver (): 返回 ( # kafka流是(时间戳,值) # value包含kafka负载 dlt.read_stream ( “kafka_bronze” ) .select(坳( “时间戳” ), from_json(坳( “价值” ) .cast ( “字符串” ), event_schema) .alias ( “事件” )) .select ( “时间戳” , “。*” ) )好处
直接从消息代理读取DLT中的流数据可以最大限度地降低体系结构的复杂性,并提供更低的端到端延迟,因为数据直接从消息代理中流式传输,不涉及中间步骤。
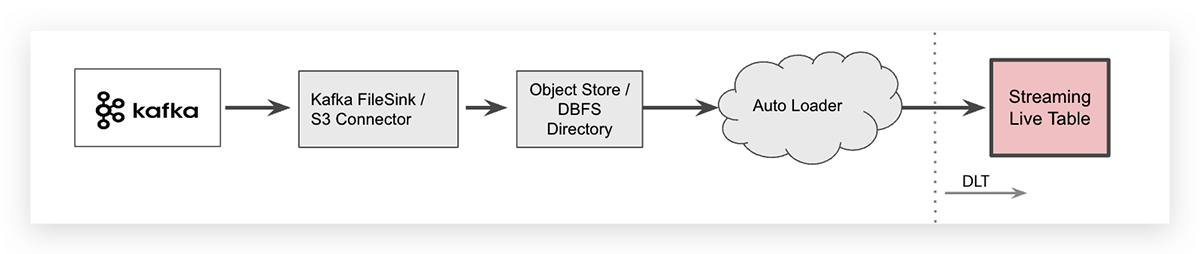
流式摄取与云对象存储中介
对于某些特定的用例,你可能想要从Apache Kafka卸载数据,例如,使用Kafka连接器,并将流数据存储在云对象中介中。在Databricks工作空间中,特定于云供应商的对象存储可以通过Databricks Files System (DBFS)映射为独立于云的文件夹。一旦数据被卸载,Databricks自动加载器 可以摄取文件。
Auto Loader可以通过一行SQL代码摄取数据。将JSON文件摄取到DLT表的语法如下所示(为了可读性,它被换行了两行)。
- INGEST与自动加载器 创建 或 取代直播 表格 生 作为 选择 * 从 cloud_files(“dbfs: /数据/ twitter”,“json”) 请注意,Auto Loader本身是一个流数据源,所有新到达的文件都将被处理一次,因此原始表的streaming关键字表明数据是增量地摄取到该表中的。
由于将流数据卸载到云对象存储中会在系统架构中引入额外的步骤,它还会增加端到端延迟并产生额外的存储成本。请记住,Kafka连接器将事件数据写入云对象存储需要管理,这增加了操作的复杂性。
因此,Databricks建议使用Spark Structured Streaming直接从DLT访问事件总线数据作为最佳实践如上所述 .
其他事件总线或消息传递系统
本文围绕Apache Kafka展开;但是,所讨论的概念也适用于其他事件总线或消息传递系统。DLT支持任何Databricks Runtime直接支持的数据源 .
亚马逊运动
在Kinesis中,您将消息写入完全托管的无服务器流。和Kafka一样,Kinesis不永久存储消息。Kinesis中的默认消息保留时间为一天。
使用Amazon Kinesis时,替换格式(“卡夫卡”),格式为(“运动”)在上面的Python代码中进行流摄取,并添加Amazon kinesis特定的设置选项()。有关更多信息,请查看有关运动的集成 在Spark结构化流文档中。
Azure事件中心
对于Azure事件集线器设置,请检查官方微软文档 这篇文章Delta Live Tables食谱:从Azure事件中心消费 .
总结
DLT不仅仅是ETL中的“T”。使用DLT,您可以轻松地从流和批处理源中摄取数据,在任何云上的Databricks Lakehouse平台上清洗和转换数据,并保证数据质量。bob体育客户端下载
来自Apache Kafka的数据可以通过直接从Python中的DLT笔记本连接到Kafka代理来摄取。即使Kafka流层中的源数据过期,也可以防止数据丢失,以进行完整的管道刷新。
开始
如果您是Databricks的客户,只需按照入门指南 .阅读发行说明以了解更多关于此GA发行版中包含的内容。BOB低频彩如果您不是Databricks的现有客户,注册免费试用吧 ,你可在此浏览我们详细的数码物流服务定价在这里 .
中加入对话砖社区 痴迷于数据的同行们正在讨论2022年数据+人工智能峰会的公告和更新。学习。网络。
最后但并非最不重要的,享受深入研究数据工程 来自峰会的会议。在这节课中,我将向您介绍另一个流数据示例的代码,其中包括Twitter直播流、Auto Loader、SQL中的Delta live Tables和hug Face情感分析。