Delta Lake Data Ingestion Demo
無料トライアルを開始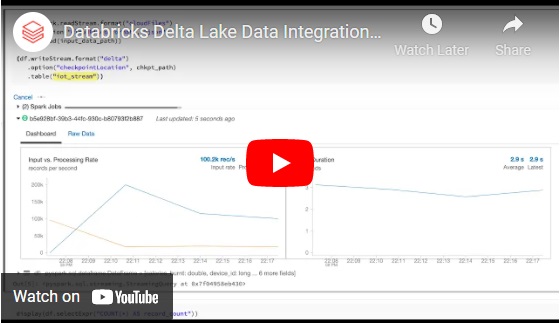

With Databricks Auto Loader, you can incrementally and efficiently ingest new batch and real-time streaming data files into your Delta Lake tables as soon as they arrive in your data lake — so that they always contain the most complete and up-to-date data available. Auto Loader is a simple, flexible tool that can be run continuously, or in “triggerOnce” mode to process data in batches. SQL users can use the simple “COPY INTO” command to pull new data into their Delta Lake tables automatically, without the need to keep track of which files have already been processed.
Notebook をダウンロード
Dive deeper into the Databricks Platform


Video transcript
Getting data into Delta Lake with Auto Loader
Loading raw data into a data warehouse can be a messy, complicated process, but with Databricks, filling your Delta Lake with the freshest data available has never been easier.
Here, we’re working with some JSON telemetry data from IoT devices like smart watches that track steps. New data files are landing in our data lake every 5 seconds, so we need a way to automatically ingest them into Delta Lake. Auto Loader provides a new Structured Streaming data source called “cloudFiles” that we can use to do just that.
Click to expand the transcript →
Click to collapse the transcript →
How to use Databricks Auto Loader
First, we specify “cloudFiles” as the format for our data stream. Next, we specify which directory in the data lake to monitor for new files. As soon as they arrive, Auto Loader efficiently and incrementally loads them into the Delta Lake table that we specify.
And you’re done! Using Auto Loader is like pressing the “easy button” for raw data ingestion. We don’t have to specify a schema, set up a message queue or manually track which files have already been processed. Behind the scenes, Auto Loader keeps track of new file events using an always-on file notification service that’s faster and more scalable than running costly “list” operations on your data lake.
Using Auto Loader in batch mode with triggerOnce
For time-sensitive data workloads, running Auto Loader continuously is a no-brainer. But for less time-sensitive workloads, you can run Auto Loader in “batch mode” by specifying the “triggerOnce” option, then setting up the notebook to run as a scheduled job. In triggerOnce mode, Auto Loader still keeps track of new files even when there’s not an active cluster running — it just waits to actually process them until you run the Auto Loader code again manually, or as part of a scheduled job.
与复制到SQL用户加载数据
Finally, SQL users that prefer this batch-oriented approach to data ingestion can use the COPY INTO command instead. COPY INTO is a retriable and idempotent command, so it ignores data that has already been processed, just like Auto Loader in “triggerOnce” mode.
無料お試し・その他ご相談を承ります


