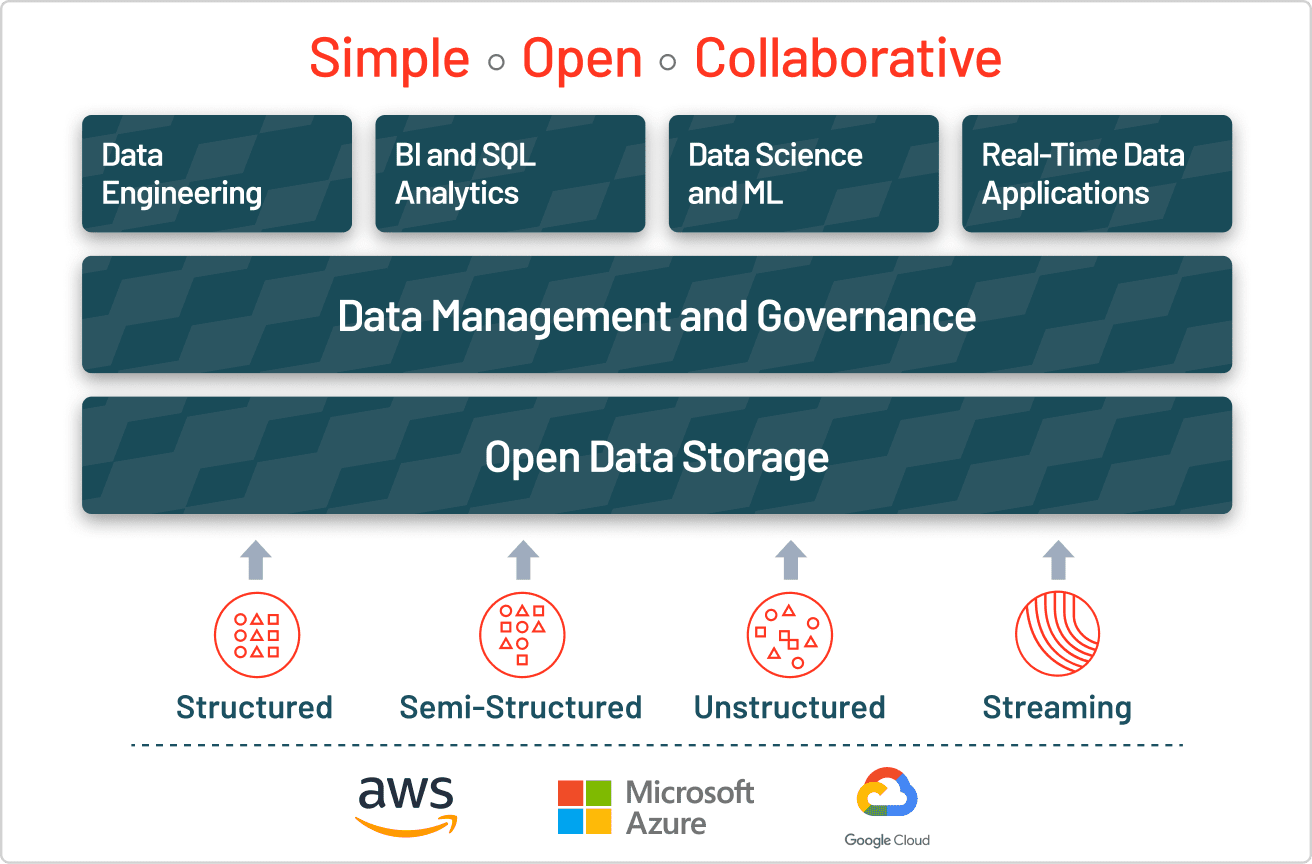
介绍数据湖泊
数据湖泊提供一个完整的和权威的数据存储,数据分析,商业智能和机器学习
介绍数据湖泊
湖是什么数据?
一个数据湖是一个中央位置,拥有大量数据在本土,原始格式。分层数据仓库相比,在文件或文件夹存储数据,数据使用一个湖平面结构和对象存储来存储数据。对象存储存储数据与元数据标签和一个独特的标识符,这使得它更容易在区域定位和检索数据,并提高了性能。通过利用廉价的对象存储和开放格式,数据湖泊使许多应用程序数据的利用。
数据湖泊开发针对数据仓库的局限性。为企业提供高性能和可伸缩的数据仓库分析,它们是昂贵的和专有的和无法处理现代用例大多数公司正在寻找地址。数据湖泊通常用来巩固一个组织所有的数据在一个中央位置,可以保存”,“而不需要征收模式(即。,数据是如何组织的正式结构)像一个数据仓库。细化过程的所有阶段的数据可以存储在一个数据湖:原始数据可摄入和存储与组织的结构,表格数据资源(如数据库表),以及中间数据表生成的精炼过程中的原始数据。与大多数数据库和数据仓库,数据湖泊可以处理所有数据类型——包括非结构化和半结构化数据像图片,视频、音频和文件——这是今天的机器学习和高级分析的关键用例。
为什么你会使用数据湖吗?
首先,湖泊是开放的数据格式,所以用户避免锁定专有系统像一个数据仓库,已成为越来越重要的在现代数据体系结构。数据湖泊也高度耐用、低成本,因为他们的规模和杠杆对象存储的能力。此外,先进的分析和机器学习对非结构化数据的一些最今天企业战略重点。唯一能够摄取各种格式的原始数据(结构化、非结构化、半结构化),连同提到的其他好处,使数据存储的数据湖明确的选择。
当适当的架构,数据湖泊启用的能力:

电力数据科学和机器学习
湖泊允许您将原始数据转换成数据准备SQL结构化数据分析,数据科学与低延迟和机器学习。原始数据可以保留无限期地以低成本为未来使用机器学习和分析。

集中,巩固和目录数据
集中式数据湖消除数据孤岛的问题(如数据重复,多种安全策略和协作困难),提供下游用户一个地方寻找所有的数据来源。

快速和无缝集成不同的数据来源和格式
所有数据类型可以在数据收集和保留无限期湖,包括批处理和流数据、视频、图像、二进制文件和更多。由于数据提供了一个新数据的着陆区湖,它总是最新的。

民主化数据提供用户自助服务工具
数据湖泊非常灵活,让用户完全不同的技能、工具和语言执行不同的分析任务。
数据湖挑战
尽管他们的优点,但许多数据的承诺湖泊没有意识到由于缺少一些关键功能:不支持事务,没有执行数据质量或治理,可怜的性能优化。因此,大多数的企业已经成为数据中的数据湖泊沼泽。
可靠性的问题
没有适当的工具,数据的湖泊会从数据可靠性的问题,使数据科学家和分析师很难推断数据。这些问题源于困难结合批处理和流数据,数据损坏和其他因素。
缓慢的性能
湖的大小数据在数据的增加,传统的查询引擎的表现一直较慢。的一些瓶颈包括元数据管理、数据分区不当等等。
缺乏安全特性
湖泊的数据很难正确安全管理由于缺乏可见性和删除或更新数据的能力。这些限制使其很难满足监管机构的要求。
由于这些原因,传统数据湖本身不足以满足企业的需要,寻求创新,这也是为什么企业经常在复杂的体系结构,孤立的数据在不同的存储系统:数据仓库,数据库和其他存储系统在整个企业。简化架构的统一所有数据在数据湖是第一步的公司渴望利用机器学习和数据分析来赢得未来十年。
lakehouse如何解决这些挑战
答案数据湖泊是lakehouse的挑战,这在上面添加一个事务性存储层。lakehouse使用类似的数据结构和数据管理功能的数据仓库,而是直接运行在云数据湖泊。最终,lakehouse允许传统分析,数据科学和机器学习在同一个系统共存,所有在一个开放的格式。
lakehouse允许范围广泛的新的跨功能的企业级分析用例,BI和机器学习项目,可以释放巨大的商业价值。数据分析师能收获丰富的见解通过湖使用SQL查询数据,数据科学家可以加入和丰富的数据集生成毫升模型与更大的精度,数据工程师可以构建自动化ETL管道,和商业情报分析人员可以创建视觉仪表盘和报表工具比以前更快和更容易。这些用例都可以同时进行数据湖,没有提升和改变数据,尽管新数据流。
建立一个lakehouse三角洲湖
lakehouse建立成功,组织必须利用三角洲湖,开放格式数据管理和治理层相结合的最好的两个湖泊和数据仓库的数据。各行业,企业利用三角洲湖电力合作提供了一个可靠的、单一来源的真理。通过交付质量、可靠性、安全性和性能数据湖上——流和批处理操作——三角洲湖消除数据孤岛,使分析整个企业的访问。三角洲湖,客户可以建立一个有成本效益的,高度可伸缩的lakehouse,消除数据孤岛,为终端用户提供自我分析。
湖泊与数据lakehouses与数据仓库
| 数据湖 | 数据lakehouse | 数据仓库 | |
|---|---|---|---|
| 类型的数据 | 所有类型:结构化数据、半结构化数据、非结构化(生的)数据 | 所有类型:结构化数据、半结构化数据、非结构化(生的)数据 | 结构化数据只 |
| 成本 | 美元 | 美元 | $ $ $ |
| 格式 | 开放格式 | 开放格式 | 关闭,专有格式 |
| 可伸缩性 | 尺度持有任何以低成本的数据量,无论类型 | 尺度持有任何以低成本的数据量,无论类型 | 扩大成为指数由于供应商成本更加昂贵 |
| 面向的用户 | 限制:数据科学家 | 机器学习统一:数据分析师、数据科学家,工程师 | 有限:数据分析师 |
| 可靠性 | 低质量数据沼泽 | 高质量的、可靠的数据 | 高质量的、可靠的数据 |
| 易用性 | 困难:探索大量原始数据可能很困难,没有工具来组织和目录数据 | 简单:为数据仓库的简单性和结构提供了更广泛的用例数据湖 | 简单:数据仓库的结构使得用户能够快速、轻松地访问数据报告和分析 |
| 性能 | 可怜的 | 高 | 高 |
Lakehouse最佳实践
使用数据湖的着陆区所有数据
将你所有的数据都保存到您的数据没有改变或湖聚合保存它为机器学习和数据血统的目的。
面具数据包含之前进入你的私人信息
个人身份信息(PII)必须pseudonymized为了符合GDPR并确保它可以无限期保存。
安全数据湖——基于角色访问控制
添加基于acl(访问控制级别)允许更精确的调优和控制数据的安全性比仅基于角色控制湖。
可靠性和性能构建到您的数据通过使用三角洲湖湖
大数据的性质使得它难以提供相同级别的可靠性和性能可以与数据库直到现在。湖泊三角洲湖带来了这些重要特性数据。
目录中的数据数据湖
使用数据目录和元数据管理工具的摄入,使自助数据科学分析。