


介绍砖摄取:简单和有效的摄入来自不同数据源的数据到三角洲湖
2020年2月24日
通过普拉卡什Chockalingam
在
工程的博客
我们兴奋地介绍一个新功能——自动加载器和一组合作伙伴集成,在公共预览,……
大多数商业决策时间敏感,需要利用实时数据从不同的来源。采购的关键是在正确的时间正确的数据能够及时决策。时间敏感数据来源从物联网传感器分布在不同的技术,社会媒体,点击流,变化数据捕获从数据库等。为了从这些数据获得关键的见解,首先必须摄取到lakehouse。这些数据的关键特征是连续到达一个无界的时尚又名流媒体。在这个博客中,我们将关注如何摄取到lakehouse流数据。
流来自不同数据源的数据举行到消息总线系统或云对象存储在摄入lakehouse之前。的数据暂存区域被Apache火花结构化流(SS)管道,写数据到lakehouse。有两个著名的登台环境——云对象存储和消息总线系统,讨论如下。
高级体系结构的流数据摄取到lakehouse从这两个关键数据暂存环境如图1所示。
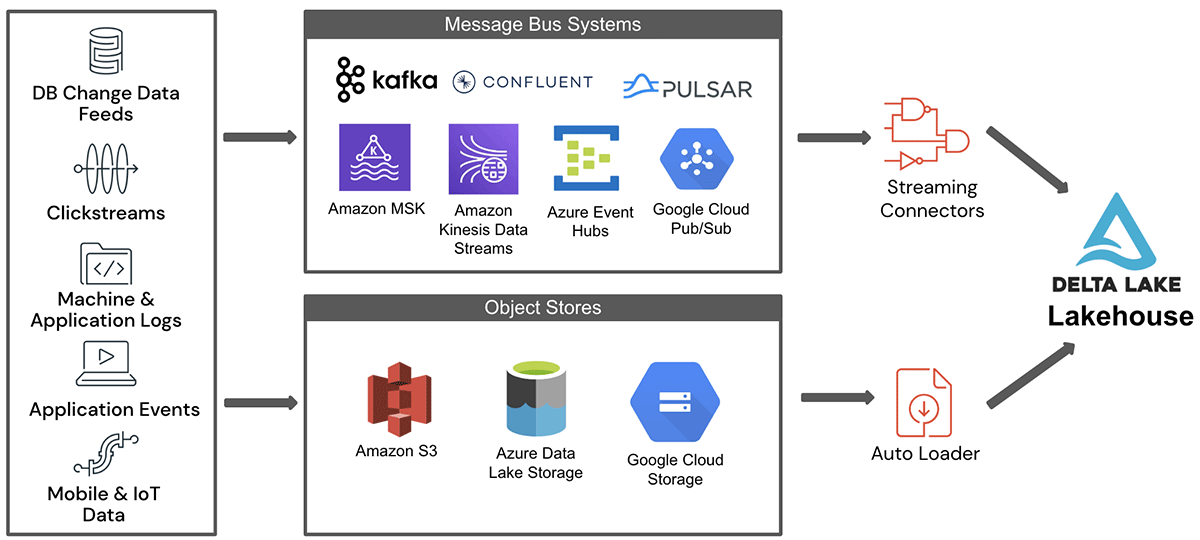
如图,来自各种源系统的数据第一次登台的地区之一的土地在对象存储或消息总线。这个数据摄取到lakehouse通过流连接器为对象存储消息巴士或汽车加载程序。三角洲生活表(DLT)是一个简单的声明性方法用于创建可靠的数据管道和全面管理底层基础设施规模的批处理和流媒体数据。也是基于火花结构化流并没有涵盖在这个博客。在随后的部分中,我们将详细描述所涉及的一些挑战而摄取流数据从这些来源。
通常,文件与批处理相关数据摄入。然而,连续摄入来自不同数据源的数据到基于云的对象存储文件的形式往往是一种常见的模式。通常情况下,这种模式更适合用例需要实时处理,预计延迟可以在附近一系列的分钟。此外,非功能性需求,如完全一次处理,再处理失败的摄入工作,时间旅行,需要和模式漂移。
说明的挑战从云存储对象加载到lakehouse,让我们考虑一个信用卡支付需要实时处理系统,改善客户体验和检测欺诈付款。通常情况下,从不同的支付通道是批处理事务对象存储成文件。这些文件需要摄取到下游lakehouse作进一步处理。随着这些付款交易,我们需要确保他们完全一旦规定再加工处理失败的事务,没有重复。如果这是在AWS云处理,这需要一个复杂的体系结构,包括:
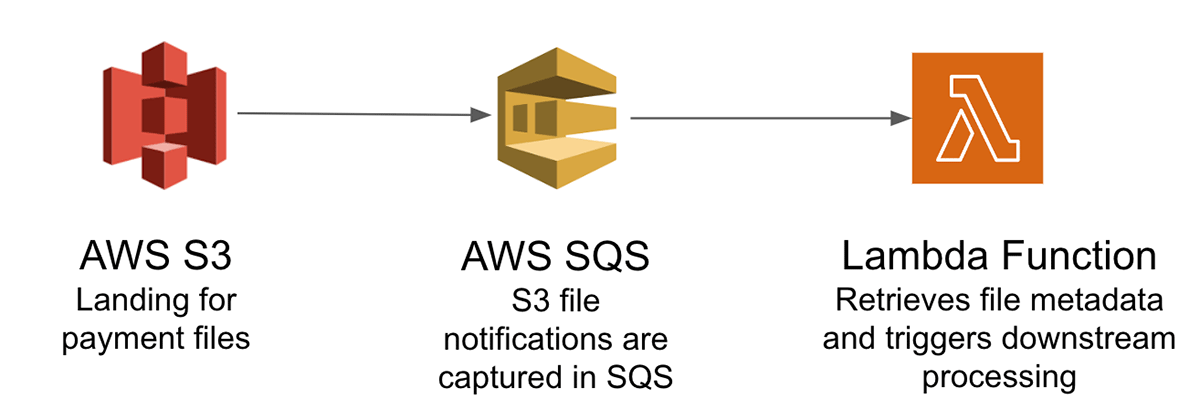
的关键挑战是跟踪降落在对象存储大量文件,使完全一旦处理这些文件中的数据和管理不同模式从不同的支付渠道。
自动加载程序简化了流数据摄入增量处理新的数据文件所到达云对象存储和它不需要用户编写一个自定义应用程序。它跟踪文件处理到目前为止,通过维护一个内部状态。在失败的情况下,它使用状态从过去开始处理文件。此外,如果需要重放或再加工数据,它提供了一个选项来处理现有的目录中的文件。自动装载器的主要优点是:
自动加载程序支持两种模式检测新文件:文件通知和目录清单。
文件的通知:自动加载程序可以自动建立一个事件队列服务,订阅通知和文件从输入目录。文件通知模式更好的性能和可伸缩的输入目录与大量的文件,但需要额外的云权限。此选项时更好的文件不抵达词法顺序和不再需要显式设置队列和通知。启用这个模式,你需要设置的选项cloudFiles.useNotifications为true和提供必要的权限来创建云资源。看到更多的细节关于文件通知在这里。
目录清单:确定新文件的另一种方法是通过清单中输入目录配置自动加载程序。目录清单模式允许您启动自动加载程序流没有任何额外的权限配置除了访问您的数据。从砖9.1运行时起,自动加载程序可以自动检测文件是否与词法顺序到达,云存储并显著降低API调用的数量需要检测新文件。在默认模式,它触发完整的目录清单后每七个增量目录清单。然而,完整的目录列表的频率可以调整通过设置配置cloudFiles.backfillInterval。可以显式地启用或禁用清单通过设置配置增量cloudFiles.useIncrementalListing。显式地启用这个配置时,自动加载程序不会触发完整的目录清单。看到更多的目录列表的详细信息在这里。
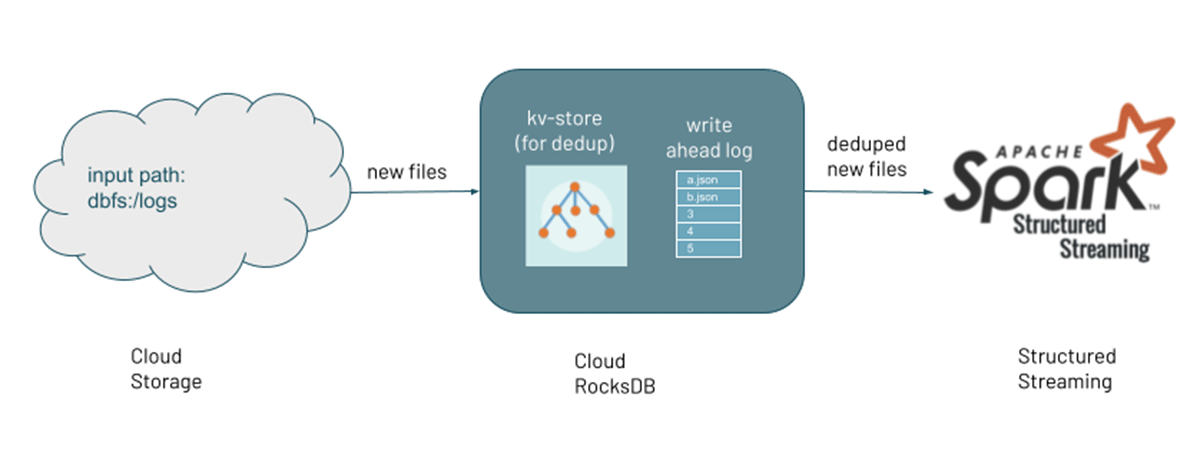
随着新文件被发现,他们的元数据保存在一个可伸缩的键值存储(RocksDB)的检查点位置自动加载器管道。这是国家跟踪文件的处理。管道都可以执行包含并发现有文件和目录上的回填过程新文件被发现通过文件通知。
流数据通常是无限的。这些数据是在消息公交车作为一个缓冲和提供异步的通信方法在多个生产者可以写入和许多消费者可以读取。消息总线是广泛用于低延迟用例如欺诈检测、金融资产交易,和游戏。受欢迎的消息总线服务包括Apache卡夫卡,Apache脉冲星,Azure EventHubs,亚马逊云Pub / Sub运动和谷歌。然而,连续数据摄入带来了挑战,如可伸缩性、弹性和容错。
摄入的消息总线lakehouse,显式火花结构化流实例化适当的源(SS)管道连接器的消息总线和水槽lakehouse连接器。在这种情况下的关键挑战是吞吐量和容错。
让我们讨论一些常见的摄入模式从这些来源。虽然消息总线是一个不错的选择,实时处理用例,大多数应用程序需要一个平衡的设计之间的延迟,吞吐量,容错需求和成本。我们将通过这些设计选择:
延迟:实现低延迟并不总是更好。而你可以通过选择合适的延迟,降低成本的准确性和成本的权衡。火花结构化流流程数据增量控制触发器定义流媒体数据处理的时机。低延迟的火花结构化流工作实现触发间隔较低。这是建议配置结构化流触发间隔平衡的延迟需求和数据到达率。如果你指定一个非常低的触发时间间隔,该系统可能进行不必要的检查,看看新数据到来。
火花结构化流提供了三个触发类型:
默认值:默认情况下,火花结构化流处理下一批就前一批处理完成。在大多数用例,默认将满足您的需求。
固定间隔:使用固定的间隔,可以处理工作在用户指定的时间间隔。一般是用来固定时间间隔等特定时间和运行更大的microbatch。
一次:有时,数据到达一个固定的间隔,这将是一个浪费资源的保持集群启动并运行。其中一个选项是在批处理模式下运行的工作。然而在触发火花结构化流执行工作一次或AvailableNow在批处理模式可以是有益的。与这些执行设置,不需要保持集群运行,你可以显著节省成本通过定期旋转的一个集群,集群处理数据和关闭。尽管它类似于批处理作业,它提供了额外的好处,如记账管理,数据处理,容错通过维护表级原子性和有状态操作在运行。
吞吐量:有多个参数,可以通过调优在火花结构化流实现高吞吐量。除了选择触发类型,关键参数之一是摄入的数据并行处理工作。实现更高的吞吐量,可以增加分区的数量在消息总线。通常火花消息总线分区之间有一对一的映射为Apache卡夫卡火花结构化流分区。然而在AWS动作的情况下,消息是预取的记忆和动作的数量之间没有直接的映射碎片和火星任务的数量。
让我们考虑一个真实世界的例子,更高的吞吐量是通过调优的批量大小和数量的分区。在银行使用的情况下,实时交易处理使用流媒体工作一整天。然而,一些实时接收到的事件可能是不准确的。因此和解批处理执行到一天结束的时候解决问题。和解批处理使用相同的代码流,但不同的工作实例。分区和批量大小增加的数量来实现高吞吐量相比,连续流数据在另一个话题。
容错:作为microbatches火花结构化流执行的工作,它给了两个截然不同的优势实现容错:
在火花结构化流失败的恢复工作是通过使用每个查询的检查点位置。检查站内的偏移位置使您能够重新启动工作从准确的故障点。选择提供检查点位置查询:
选项(“checkpointLocation”、“dbfs: / / checkpointPath”)
可复制源和幂等汇,火花结构化流工作可以实现只有一次语义,这通常是一个需求的生产级应用程序。
流数据摄入是第一步在lakehouse启用时间敏感的决策。在这个博客中,我们连续流动的流数据来源分类文件或消息总线服务。自动加载程序简化了接近实时摄取来源文件使用火花结构化流并提供先进的功能,如自动检测文件的到来,可伸缩性来处理大量的数据,模式推理和成本效益数据摄入。而对于数据摄入从消息总线服务,火花结构化流使健壮的数据摄入框架,集成了大部分的消息总线服务在不同的云供应商。大多数生产级应用程序需要一个延迟和吞吐量之间的权衡来减少成本,获得更高的精度。



