




在Databricks Lakehouse中简化半结构化数据管理的10个强大功能
无麻烦的数据摄取发现如何Databricks简化半结构化的数据摄取到Delta湖详细的用例,演示和现场问答。看……
2021年11月11日 在工程的博客
摄取和查询带有半结构化数据的JSON可能是乏味和耗时的,但是Auto Loader和三角洲湖让它变得简单。JSON数据非常灵活,这使得它非常强大,但也很难摄取和查询。最大的挑战包括:
在这个博客中附赠笔记本,我们将在Databricks Lakehouse中展示哪些内置功能使使用JSON变得简单。下面是增量式ETL体系结构。左边表示连续的和计划的摄取,我们将讨论如何使用Auto Loader进行这两种类型的摄取。在将JSON文件导入青铜Delta Lake表之后,我们将讨论使查询JSON数据中常见的复杂和半结构化数据类型变得容易的特性。
在附带的笔记本中,我们使用销售订单数据演示了如何轻松地摄取JSON。嵌套的JSON销售订单数据集很快就变得复杂起来。
自动加载程序提供Python和Scala接口,从对象存储(S3, ADLS, GCS)的文件夹位置摄取新数据到Delta Lake表。Auto Loader通过以连续或计划的方式直接从对象存储中摄取数据到Delta Lake表,使摄取变得简单和无麻烦。
在讨论Auto Loader的一般特性之前,让我们先研究一下使JSON的摄取变得极其简单的特性。下面是一个如何摄取非常复杂的JSON数据的示例。
df = spark.readStream。格式(“cloudFiles”)\.option (“cloudFiles.schemaLocation”, schemaLocation) \.option (“cloudFiles.format”,“json”)\.option (“cloudFiles.inferColumnTypes”,“真正的”)\.option (“cloudFiles.schemaEvolutionMode”,“addNewColumns”)\.option (“cloudFiles.schemaHints”, schemaHints) \.load (landingZoneLocation)定义模式的灵活性和便利性:在上面的代码中,我们使用Auto Loader的两个特性来轻松定义模式,同时为有问题的数据提供护栏。这两个有用的特性是cloudFiles.inferColumnTypes而且cloudFiles.schemaHints.让我们来仔细看看这些定义:
特性1 -使用cloudFiles。在ferColumnTypes for automatically inferring data types during the schema inference process:的默认值cloudFiles.inferColumnTypes为false,因为在大多数情况下,最好让顶级列为字符串,以实现模式演进的健壮性,并避免在模式演进过程中出现数字类型不匹配(整数、长值、浮点数)等问题。
特性2 -使用cloudFiles。schemaHints用于指定所需的数据类型,以补充模式推断:使用模式提示只有在您没有向自动加载器提供模式。您可以使用模式提示是否cloudFiles.inferColumnTypes启用或禁用。详情请见在这里.
在这个用例中(笔记本),我们实际上设置cloudFiles.inferColumnTypes为true,因为我们希望推断列和复杂的数据类型,而不是Auto Loader默认的推断数据类型字符串。推断大多数列将提供这个复杂JSON的保真度,并为以后的查询提供灵活性。此外,虽然推断列类型非常方便,但我们也知道摄取了有问题的列。这就是cloudFiles.schemaHints开始发挥作用,一起工作cloudFiles.inferColumnTypes.这两个选项的组合允许推断大多数列的复杂数据类型,同时指定所需的数据类型(本例中为字符串)只有两个列的。
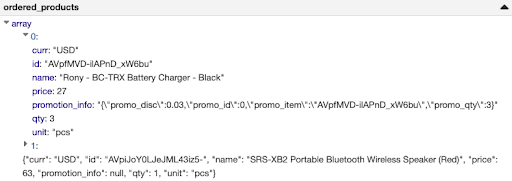
让我们仔细看看这两个有问题的列。中使用的半结构化JSON数据笔记本,我们发现了两列有问题的数据:“ordered_products.element”。Promotion_info "和" clicked_items "。因此,我们提示它们应该以字符串的形式出现(请参阅上面其中一列的数据片段:" ordered_products.element.promotion_info ")。对于这些列,我们可以很容易地用SQL查询半结构化JSON,稍后我们将对此进行讨论。您可以看到,其中一个提示位于数组内的嵌套列上,这使得该特性在复杂模式上真正起作用!
功能3 -使用模式演化随着时间的推移处理模式变化,使摄取和数据更具弹性:与模式推断一样,模式演化也很容易用Auto Loader实现。你要做的就是设置cloudFiles.schemaLocation,它将模式保存到对象存储中的该位置,然后可以随着时间的推移适应模式的演变。为了澄清,模式演化是指所摄取的数据的模式发生变化,Delta Lake表的模式也相应发生变化。
例如,在附赠笔记本,一个名为fulfillment_days被添加到自动加载程序所摄取的数据中。此列由Auto Loader标识,并自动应用于Delta Lake表。根据文档,您可以根据自己的喜好更改模式演化模式。下面是Auto Loader选项支持的模式的快速概述cloudFiles.schemaEvolutionMode:
上面的示例(也在笔记本)不包括模式,因此我们使用默认选项.option(“cloudFiles。schemaEvolutionMode”、“addNewColumns”)在readStream以适应模式进化。
特性4 -使用获救数据列在一个额外的列中捕获坏数据,这样就不会丢失任何数据:已保存的数据列保存所有未解析的数据,这确保在ETL期间不会丢失数据。如果数据不符合当前模式,不能进入所需的列,则数据不会随着已获救的数据列一起丢失。在这个用例中(笔记本),我们没有使用这个选项。要打开此选项,您可以指定以下内容:.option(“cloudFiles。schemaEvolutionMode”、“救援”)。请查看更多信息在这里.
现在,我们已经探索了Auto Loader的特性,这些特性使它能够很好地处理JSON数据挑战在开头提到的,让我们来看看它的一些功能,让所有的摄取都没有麻烦:
df。writeStream \.format \(“δ”).触发(一次=真正的)\.option("mergeSchema", "true") \.option("checkpointLocation", bronzeCheckPointLocation) \.开始(bronzeTableLocation)特性5 -使用触发一次而且触发AvailableNow连续摄入和定时摄入:虽然Auto Loader是Apache Spark™结构化流数据源,但它不需要连续运行。您可以使用触发一次选项,将其转换为定时作业,并在所有文件已被摄取时自动关闭。当您不需要连续运行摄取时,这就很方便了。然而,它还使您能够随着时间的推移而降低计划的节奏,然后最终在不更改代码的情况下持续运行ingest。在DBR 10.1及以后的版本中,我们已经介绍过触发器。AvailableNow,它提供了与触发器一次相同的数据处理语义,但也可以执行速率限制,以确保您的数据处理可以扩展到非常大量的数据。
功能6 -使用检查点处理状态:状态是在摄取过程停止时,在摄取过程停止的地方启动所需的信息。例如,使用Auto Loader,状态将包括已经摄取的文件集。检查点如果ETL在任何点停止,无论是故意还是由于失败,都保存状态。通过利用检查点,Auto Loader可以连续运行,也可以作为定期或计划作业的一部分。在上面的例子中,检查点保存在选项中checkpointLocation.如果自动加载器被终止,然后重新启动,它将使用检查点返回到其最新状态,并且不会重新处理已经处理过的文件。
现在我们已经在Delta Lake表中拥有了JSON数据,让我们探索查询半结构化和复杂结构化数据的强大方法。让我们解决查询半结构化数据的最后一个挑战。
在此之前,我们使用Auto Loader将Delta Table写入特定位置。我们可以在SQL中通过位置访问这个表,但是为了可读性,我们使用下面的SQL代码将一个外部表指向这个位置。
创建表格autoloaderBronzeTable位置“$ {c.bronzeTablePath}”;使用转换值的语法轻松访问半结构化JSON列中的顶层和嵌套数据:
选择fulfillment_days fulfillment_days:采摘,fulfillment_days:包装::双fulfillment_days: shipping.days从autoloaderBronzeTable在哪里fulfillment_days是不零在摄取数据时,您可能需要将其保存在JSON字符串中,并且一些数据可能不是正确的数据类型。在这些情况下,上面示例中的语法使查询半结构化数据的部分变得简单且易于阅读。要双击此示例,让我们看看列中的数据filfillment_days,这是一个JSON字符串列:
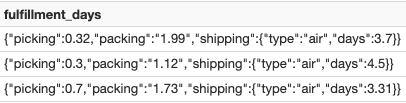
功能7 -使用单冒号(:)来提取顶层JSON字符串列:例如,filfillment_days:选为上面的第一行返回值0.32。
功能8 -使用点符号访问嵌套字段:例如,fulfillment_days: shipping.days返回上面第一行的值3.7。
功能九-使用双冒号(::)指定要返回的所需数据类型铸造价值:
例如,fulfillment_days:包装::翻倍为上面第一行的packing字符串值返回双数据类型值1.99。
从半结构化数组中提取值,即使数据格式不正确:
SELECT *, reduce(all_click_count_array,0, (acc, value) -> acc + value)作为总和从(SELECT order_number, clicked_items:[*][1]作为all_click_counts,from_json (clicked_items: [*] [1],“数组<字符串>”)::数组<int>作为all_click_count_array从autoloaderBronzeTable)int>字符串>不幸的是,并非所有数据都以可用的结构提供给我们。例如,列clicked_items是一个令人困惑的数组,其中计数以字符串形式出现。下面是该列中的数据片段clicked_items:

功能十-从数组中提取值:使用星号(*)提取JSON数组字符串中的所有值。对于特定的数组下标,使用一个基于0的值。例如,SQLclicked_items: [*] [1]返回字符串值["54","85"]。
强制转换复杂数组值:为数组的数组提取正确的值后,我们可以使用from_json而且::数组
复杂结构化数据的SQL聚合:
在Databricks中,访问复杂的结构化数据以及在结构化和半结构化数据之间切换已经有一段时间了。
选择order_date, ordered_products_explode.name作为product_name,总和(ordered_products_explode.qty)作为数量从(选择日期(from_unixtime (order_datetime))作为order_date,爆炸(ordered_products)作为ordered_products_explode从autoloaderBronzeTable在哪里日期(from_unixtime (order_datetime))是不零)集团通过order_date, ordered_products_explode.name订单通过order_date, ordered_products_explode.name在上面的SQL查询中,我们研究了如何从列中的复杂结构化数据中访问和聚合数据ordered_products.为了显示数据的复杂性,下面是该列的一行示例ordered_products,我们的目标是找出每天售出的每种产品的数量。如您所见,乘积和数量都嵌套在数组中。

以行形式访问数组元素:在ordered_products列上使用explosion,这样每个元素都是自己的行,如下所示。

访问嵌套字段:使用点表示法以与半结构化JSON相同的方式访问嵌套字段。例如,ordered_products_explosion。Qty返回上面第一行的值1。然后,我们可以根据日期和产品名称对数量进行分组和相加。
额外的资源:我们已经讨论了很多关于查询结构化和半结构化JSON数据的主题,但你可以在这里找到更多信息:
在Databricks,我们致力于将不可能变为可能,将困难变为容易。Auto Loader使得大规模地摄取复杂的JSON用例变得容易和可能。用于半结构化和复杂数据的SQL语法使操作数据变得容易。让我们来回顾一下这10个特点:
现在,您已经知道如何使用Auto Loader和SQL摄取和查询复杂的JSON,我们迫不及待地想看看您用它们构建了什么。