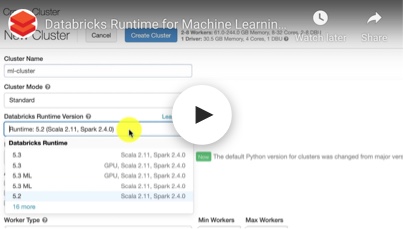
毫升框架发展正在以疯狂的速度和平均从业人员需要管理8库。毫升的稳定和高效运行时提供一键访问分布最受欢迎的ML框架,通过预先构建的容器和定制毫升环境。
Beschleunigen您das机器学习von der Datenvorbereitung bis苏珥Schlussfolgerung麻省理工学院窝integrierten AutoML-Funktionen, einschließlich Hyperparameter-Tuning和Modellsuche麻省理工学院Hyperopt MLflow。
麻省理工学院静脉automatisch verwalteten和skalierbaren Cluster-Infrastruktur您能muhelos·冯·克雷能祖茂堂großen Datenmengen wechseln。机器学习运行时enthalt欧什einzigartige Leistungsverbesserungen毛皮死gangigsten Algorithmen和HorovodRunner,风景明信片einfache API毛皮verteiltes深度学习。
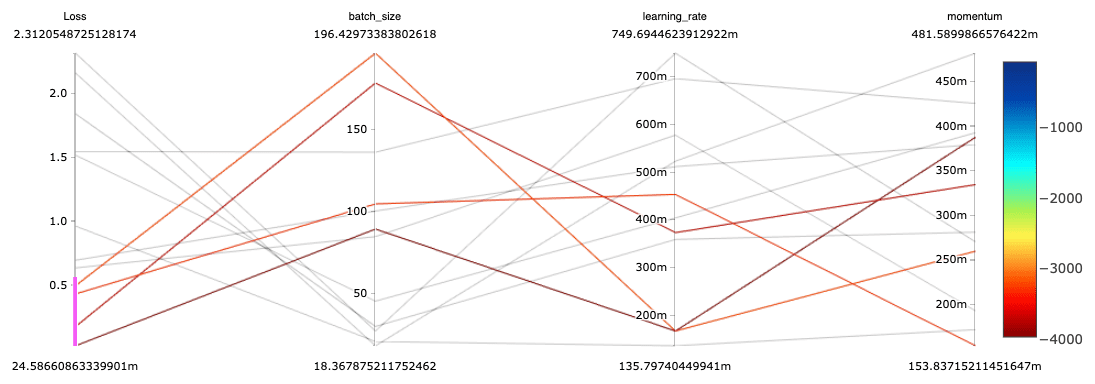
Verfolgung automatisierter Experimente:Verfolgen, vergleichen和visualisieren您Hunderttausende冯Experimenten麻省理工开放源码奥得河管理MLflbob下载地址ow和der Funktion苏珥Darstellung平行Koordinaten。
Automatisierte Modellsuche(毛皮Single-Node-ML):Optimierte和verteilte bedingte Hyperparametersuche uber mehrere Modellarchitekturen麻省理工学院erweitertem Hyperopt和毛皮MLflow automatisiertem跟踪。
Automatisiertes Hyperparameter-Tuning毛皮Single-Node-Machine-Learning:Optimierte和verteilte Hyperparametersuche麻省理工学院erweitertem Hyperopt和毛皮MLflow automatisiertem跟踪。
Automatisiertes Hyperparameter-Tuning毛皮verteiltes机器学习:Tiefe集成在死亡交叉验证冯PySpark MLlib苏珥automatischen Verfolgung冯MLlib-Experimenten MLflow。
TensorFlow optimiert:Profitieren您von der CUDA-optimierten版本冯TensorFlow auf GPU-Clustern毛皮maximale Leistung。
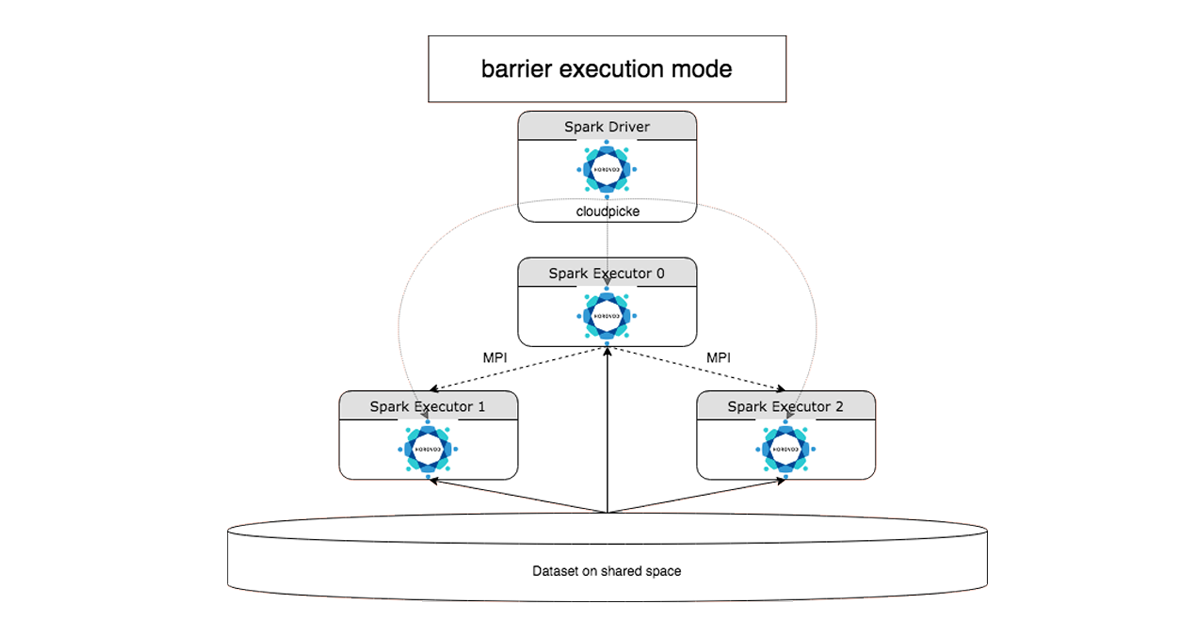
HorovodRunner:Rusten您迅速地和unkompliziert古老而深Learning-Trainingscode毛皮Einzelknoten auf——该死er超级HorovodRunner einem Databricks-Cluster laufen萤石。HorovodRunner这einfache API, Komplikationen死去,死贝der Verwendung冯Horovod毛皮verteiltes培训entstehen abstrahieren萤石。
Optimierte logistische回归和Baumklassifizierung毛皮MLlib:祖茂堂砖运行时毛的机器学习gehort欧什死Optimierung der bekanntesten估计。Im Vergleich麻省理工学院Apache火花测试盒框,您能在这里修女一张嗯bis祖茂堂40 Prozent hohere Geschwindigkeit erzielen。