



5个关键步骤成功地从Hadoop迁移到Lakehouse架构
决定从Hadoop迁移到一个现代的基于云计算的架构就像lakehouse架构是一个业务决策,而不是技术决定…
决定从Hadoop迁移到一个现代的基于云计算的体系结构lakehouse架构是一个业务决策,而不是技术决定。在以前的博客,我们挖到每个组织必须的理由评估使用Hadoop的关系。一旦利益相关者从技术、数据和业务决定企业的Hadoop,几个注意事项开始前,需要考虑实际的过渡。在这个博客中,我们将特别关注实际的迁移过程本身。你会了解一个成功迁移的关键步骤和作用lakehouse架构在引发下一波的数据驱动的创新。
我们叫它喜欢它。迁移从来就不易。然而,迁移可以结构化将负面影响降至最低,确保业务连续性和有效地管理成本。为此,我们建议把迁移的Hadoop到这五个关键步骤:
让我们回顾一些关键概念的Hadoop从政府的角度来看,以及他们如何与砖比较和对比。
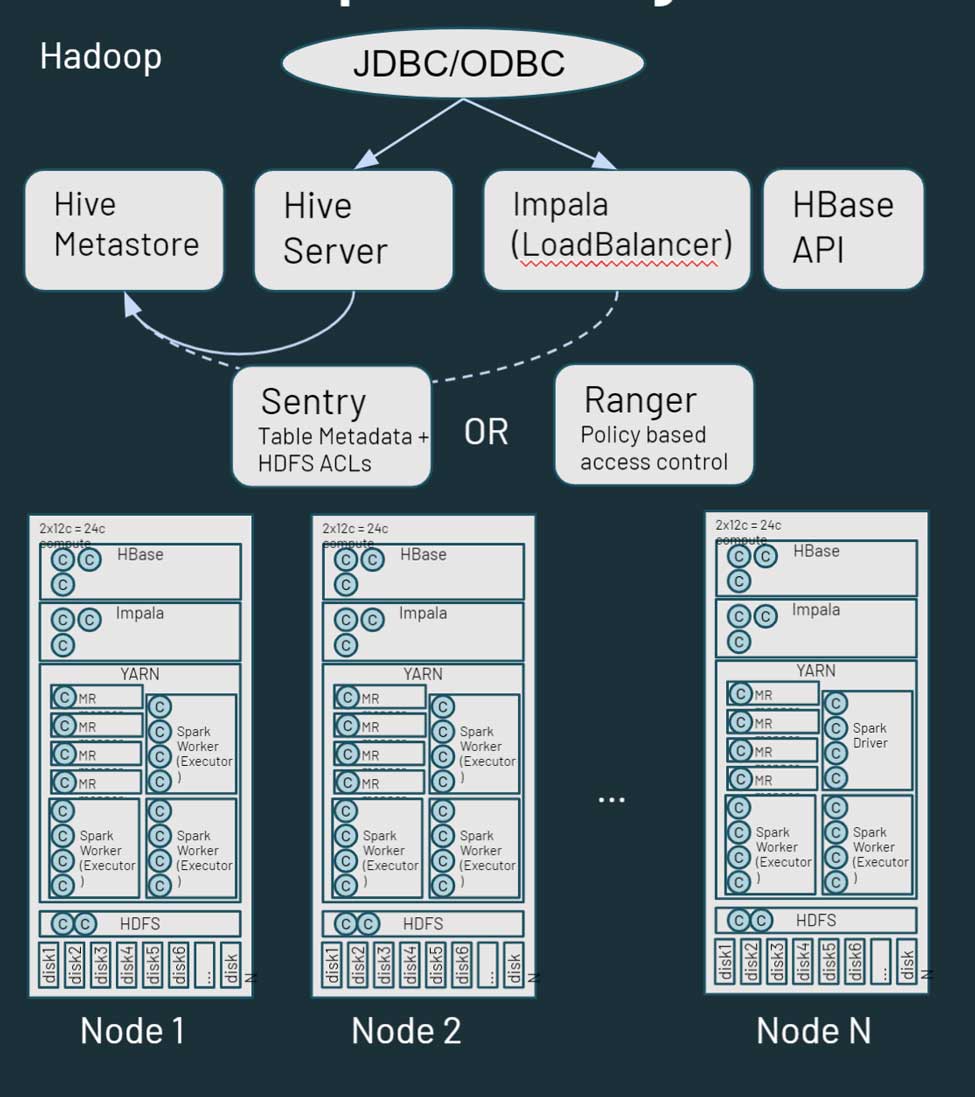
Hadoop是一个庞大的分布式存储和计算平台。bob体育客户端下载它由多个节点和服务器,每个都有自己的存储、CPU和内存。工作是分布在所有节点。资源管理是通过纱,尝试尽最大努力确保工作负载的份额计算。
Hadoop还包括元数据信息。有一个蜂巢metastore,其中包含结构化信息在你的资产存储在HDFS。您可以利用哨兵或管理员控制对数据的访问。从数据访问的角度来看,用户和应用程序可以访问数据直接通过HDFS(或相应的CLI / API)或通过SQL类型接口。SQL接口,反过来,可以通过JDBC / ODBC连接使用蜂巢通用SQL(或在某些情况下ETL脚本)或蜂巢黑斑羚或者特斯交互式查询。Hadoop还提供了一个HBase API和服务相关的数据来源。在Hadoop生态系统在这里。
接下来,让我们讨论这些服务是如何映射到或处理砖Lakehouse平台bob体育客户端下载。在砖,需要注意的第一个差异是,你看砖环境中多个集群。每个集群可以用于一个特定的用例,一个特定的项目,业务部门、团队或开发集团。更重要的是,这些集群是短暂的。对于工作的集群,集群的生命周期是为了持续工作流程的持续时间。它将执行工作流,一旦完成,环境自动拆除。同样地,如果你认为一个交互式的用例中,有在开发人员之间共享的计算环境,这个环境可以在工作日的开始旋转起来,与开发人员运行他们的代码。在不活跃时期,砖通过(可配置)将自动把它拆掉auto-terminate内置的功能平台。bob体育客户端下载
不同于Hadoop,砖不像HBase或SOLR提供数据存储服务。你的数据驻留在您的文件存储在对象存储。很多服务,比如HBase或SOLR替代品或同等技术产品在云中。这可能是一个原生云或一个ISV的解决方案。
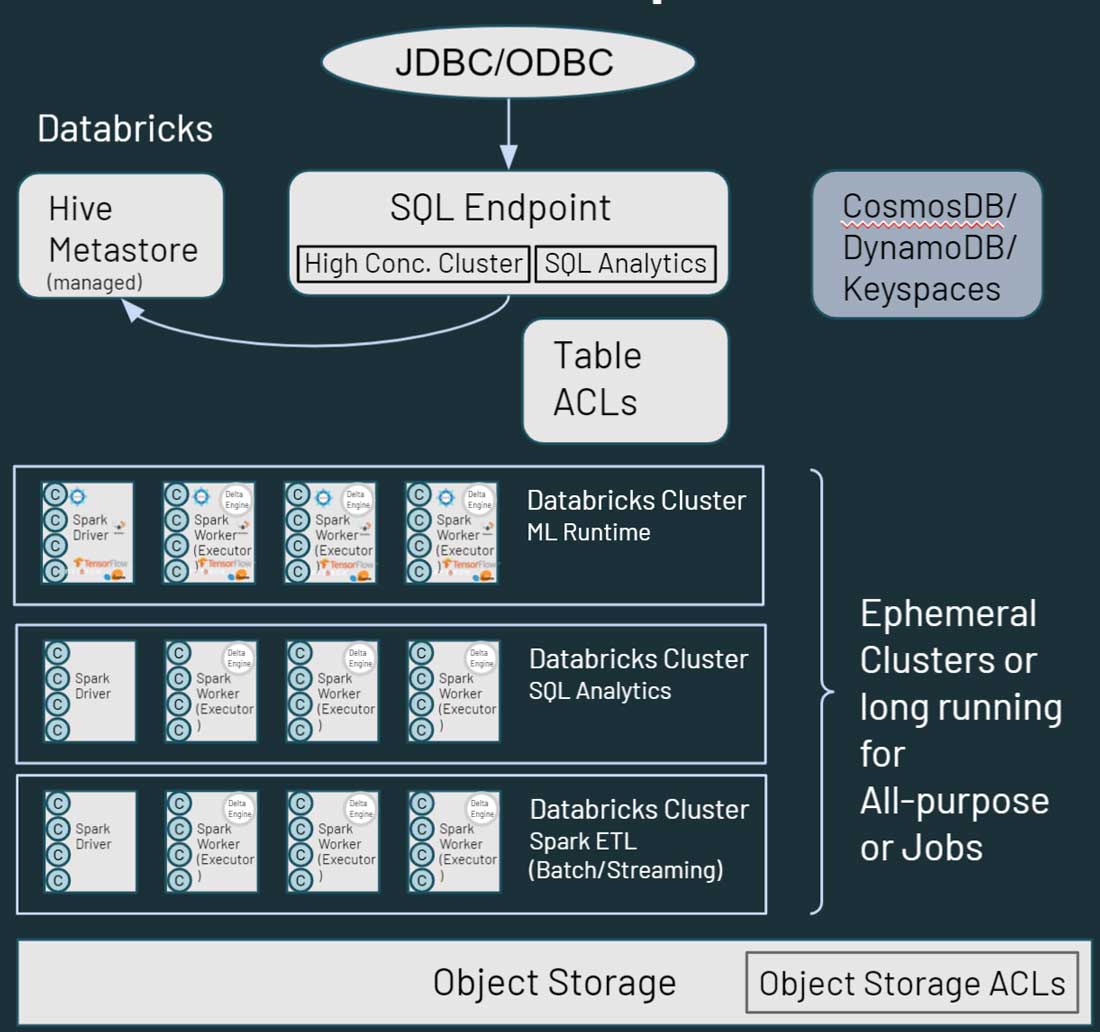
正如你所看到的在上面的图中,每个集群节点砖对应的火花司机或工人。这里的关键是,不同的砖集群是完全独立的。这允许您以确保严格sla可以为特定项目和用例。你可以真正分离流或实时从其他用例,面向批处理的工作负载,您不必担心手动隔离长时间运行的工作能拱起集群资源很长一段时间。你可以自旋向上新的集群计算为不同的用例。砖也将存储从计算,允许您利用现有的云存储等AWS S3, Azure Blob存储和Azure湖数据存储(ADLS)。
砖也有一个默认的蜂巢metastore管理,存储结构化数据资产位于云存储的信息。它还支持使用外部metastore,比如AWS胶水,Azure SQL Server或Azure范围。您还可以指定安全控制等表内acl数据砖,以及对象存储权限。
当涉及到数据访问、数据砖Hadoop提供类似功能的用户与数据进行交互。数据存储在云存储中,可以通过多条路径的砖的环境。用户可以使用SQL端点和砖SQL交互查询和分析。他们还可以使用砖笔记本数据工程和机器学习功能的数据存储在云存储中。HBase Azure CosmosDB Hadoop地图,或AWS DynamoDB /用于,可以利用下游应用程序服务层。
来自一个Hadoop的背景,我将假定大多数观众都已经熟悉HDFS。HDFS的存储文件系统使用Hadoop部署利用Hadoop集群的节点上的磁盘。HDFS规模时,您需要添加集群作为一个整体的能力(即需要大规模计算和存储)。如果这涉及到采购和安装额外的硬件,可以有大量的时间和精力。
云,你几乎无限的存储容量云存储的形式如AWS S3, Azure湖存储或Blob存储或Google存储数据。不需要维护或健康检查,它提供了内置冗余和高水平的耐用性和可用性的部署。我们建议使用本机云服务迁移数据,和缓解迁移有几个合作伙伴/ isv。bob体育外网下载
那么,如何开始?最常见的推荐路线是开始有双重摄入策略(即添加一个提要,上传数据到云存储除了内部环境)。这允许您开始使用新的用例在云中(利用新数据)而不影响你现有的设置。如果你正在寻找其他团体组织中“买账”,你可以位置作为一个备份策略。HDFS支持传统上一直是一个挑战由于规模和努力参与,所以数据备份到云可以生产计划。
在大多数情况下,您可以利用现有的数据交付工具叉提要和写作不仅Hadoop云存储。例如,如果您正在使用工具/框架Informatica和Talend Hadoop处理和写数据,很容易添加额外的步骤,让他们写信给云存储。一旦数据在云中,有很多方法来处理这些数据。
方向的数据,数据是来自内部的云,从本地或推到云。的一些工具,可以用于将数据传送到云是云本地解决方案(Azure数据框,AWS雪家庭,等等),DistCP(一个Hadoop的工具),其他第三方工具,以及任何内部框架。推动选项通常是容易的获得所需的安全团队的批准。
为拉到云上的数据,您可以使用火花/卡夫卡流或批摄入管道引发的云。对于批处理,可以直接摄取文件或使用JDBC连接器连接到相关的上游技术平台和数据。bob体育客户端下载当然,有第三方工具的。推动选项更广泛接受和理解,让我们潜水深入一点拉的方法。
首先你需要设置您的本地环境和云之间的连接。这可以实现与互联网连接和网关。您还可以利用专门的连通性选项如AWS直接连接,Azure ExpressRoute,等等。在某些情况下,如果您的组织到云并不新鲜,这可能已经为您的Hadoop设置你可以重用它迁移项目。
另一个考虑是Hadoop内的安全环境。如果它是一个使用kerberos环境,它可以容纳从砖。您可以配置数据砖在集群启动时初始化脚本运行,安装和配置必要的kerberos客户端,访问krb5。配置和keytab文件,存储在云存储位置,并最终执行kinit()函数,它将允许砖直接与您的Hadoop集群互动的环境。
最后,您还需要一个外部metastore共享。而砖确实有metastore服务部署在默认情况下,它还支持使用外部。将共享外部metastore Hadoop和砖,和可以部署本地(Hadoop环境中)或云。举个例子,如果你有现有ETL流程中运行Hadoop并不能迁移砖,您可以利用这种设置与现有本地metastore,砖消费最终策划从Hadoop数据集。
最主要的事情要记住的是,从数据处理的角度来看,一切砖利用Apache的火花。所有Hadoop编程语言,例如MapReduce,猪,蜂巢QL和Java,可以转换为运行在火花,无论是通过Pyspark Scala,甚至引发SQL或r .关于代码和IDE, Apache飞艇和Jupyter笔记本都可以被转换成砖笔记本,但是有点容易进口Jupyter笔记本。飞艇笔记本需要被转换成Jupyter或Ipython才能进口。如果您的数据科学团队愿继续代码在飞艇或Jupyter,他们可以使用砖连接的,这允许您利用您的本地IDE (Jupyter,飞艇甚至IntelliJ、VScode RStudio,等等)砖上运行代码。
迁移时,Apache火花™工作,最大的考虑是火花版本。你的本地的Hadoop集群可能会运行一个旧版本的火花,你可以使用火花迁移指南确定你看到任何影响发生了改变的代码。要考虑的另一个领域是dataframes抽样转换。抽样与火花常用版本2。x,而他们仍然可以使用火花3。x,这样做可以防止你利用火花优化器的全部功能。我们建议你改变抽样dataframes。
最后但并非最不重要的,一个常见的陷阱我们在迁移过程中遇到与客户是硬编码的参考当地的Hadoop环境。当然,这些都需要更新,没有代码将在新的设置。
接下来,让我们来谈谈转换non-Spark工作负载,这在很大程度上涉及重写代码。MapReduce,在某些情况下,如果您使用共同的逻辑形式的Java库,可以利用的代码火花。然而,你可能仍然需要重写代码的某些部分在引发环境中运行MapReduce。Sqoop相对容易迁移,因为在新环境你运行一组火花命令(而不是MapReduce命令)使用JDBC的数据源。您可以指定参数火花代码以同样的方式在Sqoop指定它们。水槽,大多数用例我们看到周围消费HDFS数据从卡夫卡和写作。这是一个可以很容易地使用火花流来完成的任务。迁移水槽的主要任务是,你必须配置基于文件的方法转换为一个更引发的编程方法。最后,我们有Nifi,大部分是使用Hadoop外,大多是一个拖拽,自助摄入的工具。Nifi可以利用在云中,但我们看到许多客户使用机会迁移到云Nifi替换为其他,云中的新工具。
迁移HiveQL或许是最简单的任务。之间存在着高度的兼容性蜂巢和火花SQL,和大多数查询应该能够运行在SQL原有火花。有一些轻微的SQL DDL HiveQL和火花之间的变化,比如火花SQL使用vs HiveQL“使用”条款的“格式”条款。我们建议更改代码使用火花SQL格式,因为它允许优化器准备最好的执行计划为您的代码在砖。你仍然可以利用蜂巢并行转换器和udf,使生活更容易迁移时HiveQL砖。
对工作流程编制,你必须考虑潜在的更改将提交你的工作。您可以继续利用火花提交语义,但也有其他更快和更无缝地集成选项。您可以利用砖工作和三角洲表无代码ETL取代Oozie的工作生活,在砖和定义的端到端数据管道。涉及外部的工作流处理依赖关系,你必须创建相当于工作流/管道在Apache气流等技术,Azure数据工厂等自动化/调度。砖的REST api,几乎任何调度平台可以集成和配置使用砖。bob体育客户端下载
还有一个自动化工具,称为MLens(由KnowledgeLens),它可以帮助你的工作负载迁移Hadoop砖。MLens可以帮助迁移PySpark代码和HiveQL,包括翻译的一些蜂巢细节到火花SQL,这样您就可以利用完整的功能和性能的火花SQL优化器的好处。他们也计划很快支持迁移Oozie工作流气流,Azure数据工厂等。
让我们看看安全性和治理。在Hadoop的世界里,我们有LDAP集成洋麻等连接到管理控制台或Cloudera经理,甚至是黑斑羚或者Solr。Hadoop还Kerberos,用于验证与其他服务。从授权的角度来看,管理员和哨兵是最常用的工具。
砖,单点登录(SSO)集成可与任何身份提供者支持SAML 2.0。这包括Azure Active Directory,谷歌工作区SSO, AWS SSO和Microsoft Active Directory。对于授权,砖提供acl(访问控制列表)砖对象,它允许您设置权限等实体笔记本,工作,集群。数据权限和访问控制,您可以定义acl表和视图列和行限制访问,以及利用凭证之类的透传,砖的传递您的工作区登录凭证到存储层(S3, ADLS Blob存储),以确定如果你是授权访问数据。如果你需要功能属性控制或数据屏蔽,可以利用合作伙伴的工具如Immuta和Privacera。从企业治理的角度来看,您可以连接砖等企业数据目录的AWS胶水,Informatica数据目录,Alation Collibra。
在Hadoop,正如前面所讨论的,你有蜂巢和黑斑羚接口ETL以及特别的查询和分析。通过在砖,你也有类似的功能砖的SQL。砖SQL还提供极端性能通过三角洲引擎,以及支持高并发性的用例与伸缩集群。三角洲引擎还包括光子,这是一个新的MPP引擎从零开始在c++和矢量化,利用数据和指令级并行性水平。
砖为本地集成提供BI工具如表、PowerBI, Qlik看起来,以及高度优化的JDBC / ODBC连接器,可以利用这些工具。新JDBC / ODBC驱动程序有一个非常小的开销(¼sec)和传输速率高出50%使用Apache箭头,以及一些元数据操作,支持更快的元数据检索操作。PowerBI砖还支持SSO,与其他BI /仪表盘工具支持SSO快到了。
砖有一个内置的SQL用户体验除了上面提到的笔记本体验,使您的SQL用户自己的镜头和一个SQL工作台,以及光仪表盘和报警功能。这允许基于sql的数据转换和探索性分析数据在湖上,而不需要移动它下游数据仓库或其他平台。bob体育客户端下载
当你思考现代云架构迁移旅程像lakehouse架构,这里有两件事要记住:
学习更BOB低频彩多关于砖增加商业价值,开始计划迁移的Hadoop,访问www.neidfyre.com/migration。