Hadoop生态系统
回到术语表什么是Hadoop生态系统?
Apache Hadoop生态系统是指Apache Hadoop软件库的各个组件;它包括开源项目以及一系列bob下载地址完整的补充工具。Hadoop生态系统中一些最著名的工具包括HDFS Hive Pig YARNMapReduceSpark, HBase, Oozie, Sqoop, Zookeeper,等。以下是开发人员经常使用的主要Hadoop生态系统组件:HDFS是什么?
Hadoop分布式文件系统(HDFS),是Apache最大的项目之一,也是Hadoop的主存储系统。它采用了NameNode和DataNode架构。它是一个分布式文件系统,能够存储在商用硬件集群上运行的大文件。Hive是什么?
Hive是一个ETL和数据仓库工具,用于查询或分析存储在Hadoop生态系统中的大型数据集。Hive主要有三个功能:对Hadoop中的非结构化和半结构化数据进行数据汇总、查询和分析。它的特点是一个类似SQL的接口,HQL语言的工作原理类似于SQL,并自动将查询转换为MapReduce作业。什么是Apache Pig?
这是一种高级脚本语言,用于对Hadoop中使用的大型数据集执行查询。Pig的简单的类似sql的脚本语言被称为Pig Latin,它的主要目标是执行所需的操作,并以所需的格式排列最终输出。什么是MapReduce?
 这是Hadoop的另一个数据处理层。它能够处理大型结构化和非结构化数据,并通过将作业划分为一组独立的任务(子作业)来并行管理非常大的数据文件。
这是Hadoop的另一个数据处理层。它能够处理大型结构化和非结构化数据,并通过将作业划分为一组独立的任务(子作业)来并行管理非常大的数据文件。什么是YARN?
YARN代表Yet Another Resource Negotiator(另一种资源协商者),但通常仅用首字母缩写来表示。它是开源Apache Hadoop中适合资源管理的核心组件之一。bob下载地址它负责管理工作负载、监视和安全控制实现。它还将系统资源分配给Hadoop集群中运行的各种应用程序,同时为每个集群节点分配应该执行的任务。YARN有两个主要组成部分:- 资源管理器
- 节点管理器
什么是Apache Spark?
Apache Spark是一个快速的内存数据处理引擎,适用于广泛的环境。Spark可以以多种方式部署,它具有Java、Python、Scala和R编程语言,并支持SQL、流数据、机器学习和图形处理,可以在应用程序中一起使用。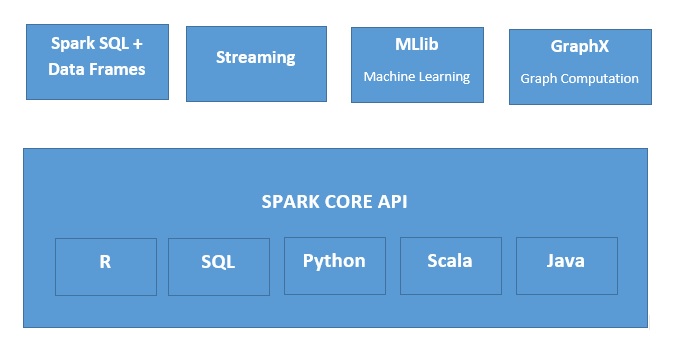
额外的资源
回到术语表
