






构建一个现代临床医疗数据与三角洲湖湖
医疗行业是最大的生产商的数据。事实上,一般的医疗组织正坐在近9 pb……
2020年4月21日 在工程的博客
医疗行业是最大的生产商的数据。事实上,一般的医疗组织正坐在近9 pb的医疗数据。电子健康记录(EHR)的兴起,数字医学图像,这套可导致这个数据爆炸。例如,EHR系统大型目录提供者可以数以百万计的医学测试,临床交互和规定的治疗方法。从这个人口规模和潜在学习数据是巨大的。通过构建分析仪表盘和机器学习模型最重要的这些数据集,医疗组织可以改善病人的经验和驱动更好的健康结果。这里有几个实际的例子:
预防新生儿败血症 |
慢性疾病的早期检测 |
跟踪疾病在人群 |
防止欺诈和滥用 |
得到的早期预览O ' reilly的新电子书一步一步的指导你需要开始使用三角洲湖。
尽管机会改善与分析和机器学习的病人护理,医疗组织面临着古典大数据挑战:
仿佛这挑战性不够,数据存储也必须支持数据的科学家们需要运行特别转换,就像创建一个纵向视图的一个病人,或与机器学习技术建立预测的见解。
幸运的是,三角洲湖一个开源存储层,为大数据带来了ACID事务工作负载,以及Apache火花TM可以帮助解决这些挑战提供事务支持快速多维查询存储在不同的数据以及丰富的数据科学功能。三角洲湖和Apache火花,医疗组织可以构建一个可伸缩的临床资料分析和ML的湖。
在这个博客系列中,我们将开始,走过一个简单的示例,展示了如何三角洲湖可用于特别的关于健康和临床数据的分析。在未来的博客,我们将看看如何三角洲湖和火花可以是耦合在一起的过程流HL7 / FHIR数据集。最后,我们将看看一些数据科学的用例可以运行的健康数据与三角洲湖湖了。
为了演示三角洲湖使它容易使用大型临床数据集,我们将开始一个简单但强大的用例。我们会建立一个仪表板,允许我们识别并存状况(一个或多个疾病或条件发生在与另一个条件在同一人在同一时间)在人口的病人。要做到这一点,我们将使用一个模拟电子健康档案数据集,生成的Synthea模拟器通过数据砖数据集(AWS|Azure)。这个数据集代表了一群来自马萨诸塞州的大约11000名患者,并存储在12 CSV文件。之前,我们将负载的CSV文件屏蔽保护健康信息(φ)和加入表一起为我们的下游获取我们需要的数据表示查询。一旦数据被提炼,我们将使用SparkR构建一个仪表板,使我们能够交互式地探索和计算常见的卫生统计在我们的数据集。
这个用例是一种很常见的起点。在临床中,我们也可以看并存病作为一种理解患者的疾病严重程度增加的风险。从医疗编码和财务的角度来看,并存疾病可能会让我们看确定共同的医疗编码问题影响报销。在医药研究,观察共病疾病遗传学证据可能给我们共享更深的了解基因的功能。
然而,当我们考虑底层的分析架构,我们还在一个起点。而不是在一个大型批量装载数据,我们可以寻求负载流电子健康档案数据,以便实时分析。而不是使用仪表板,给我们简单的见解,我们可以提前机器学习用例,如培训机器学习模型,使用数据从近期病人遇到来预测疾病的进展。这可以在一个ER设置强大的流数据和毫升可以用来预测病人的可能性提高实时或下降。
在这个博客的其余部分,我们将实现我们的仪表板。我们将首先开始使用Apache火花和三角洲湖ETL模拟电子健康档案数据集。一旦数据已经准备分析,我们将创建一个笔记本,标识并存状况在我们的数据集。通过使用内置功能在砖(AWS|Azure),我们就可以直接把笔记本变成一个仪表板。
开始,我们需要加载CSV数据转储到一个一致的表示对我们的分析,我们可以使用工作负载。通过使用三角洲湖,我们可以加速很多下游查询,我们将运行。三角洲湖支持z值,我们可以高效地查询数据跨多个维度。这是处理电子健康档案数据的关键,因为我们可能想切割数据的患者,按日期,由护理设施,或条件,在其他的事情。此外,在砖三角洲湖发行提供了额外的优化管理,加快探索查询到我们的数据集。三角洲湖也不会过时的工作:目前我们没有处理流数据时,我们可以使用EHR直播流在未来,和三角洲湖的酸语义(AWS|Azure)使处理流的简单和可靠。
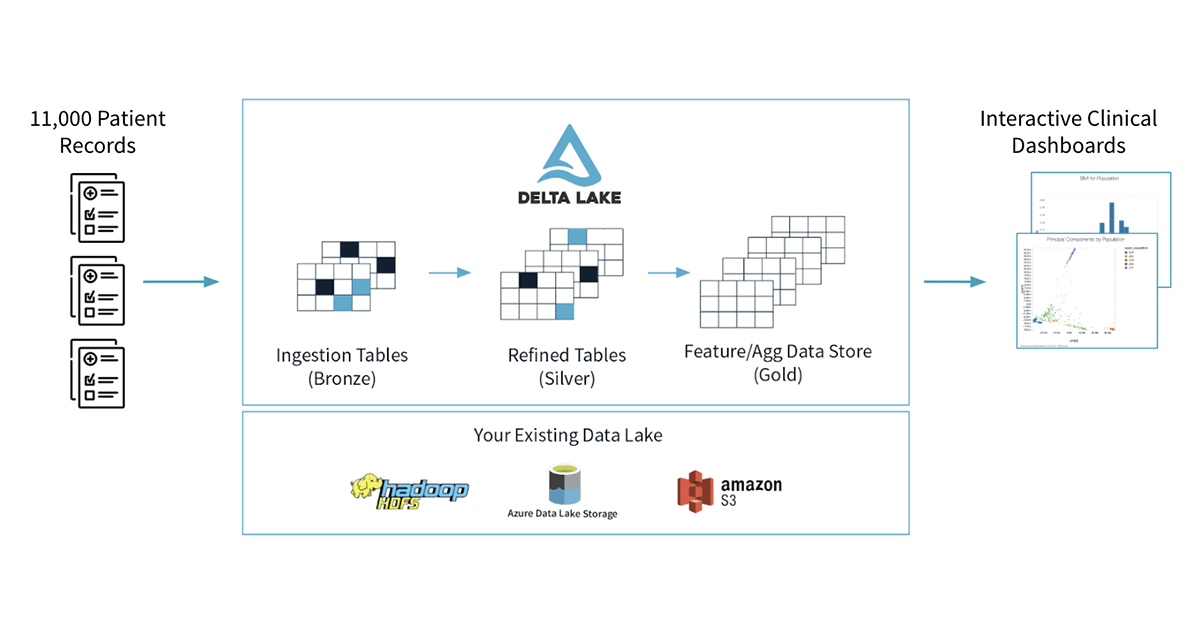
我们的工作流如下几个步骤显示在下面的图。我们将开始通过加载原始/青铜数据从我们的八个不同的CSV文件,我们将任何φ面具出现在表,我们会写出一组银表。我们将我们的银色的表联接在一起,从而得到一个更容易表现为下游处理查询。
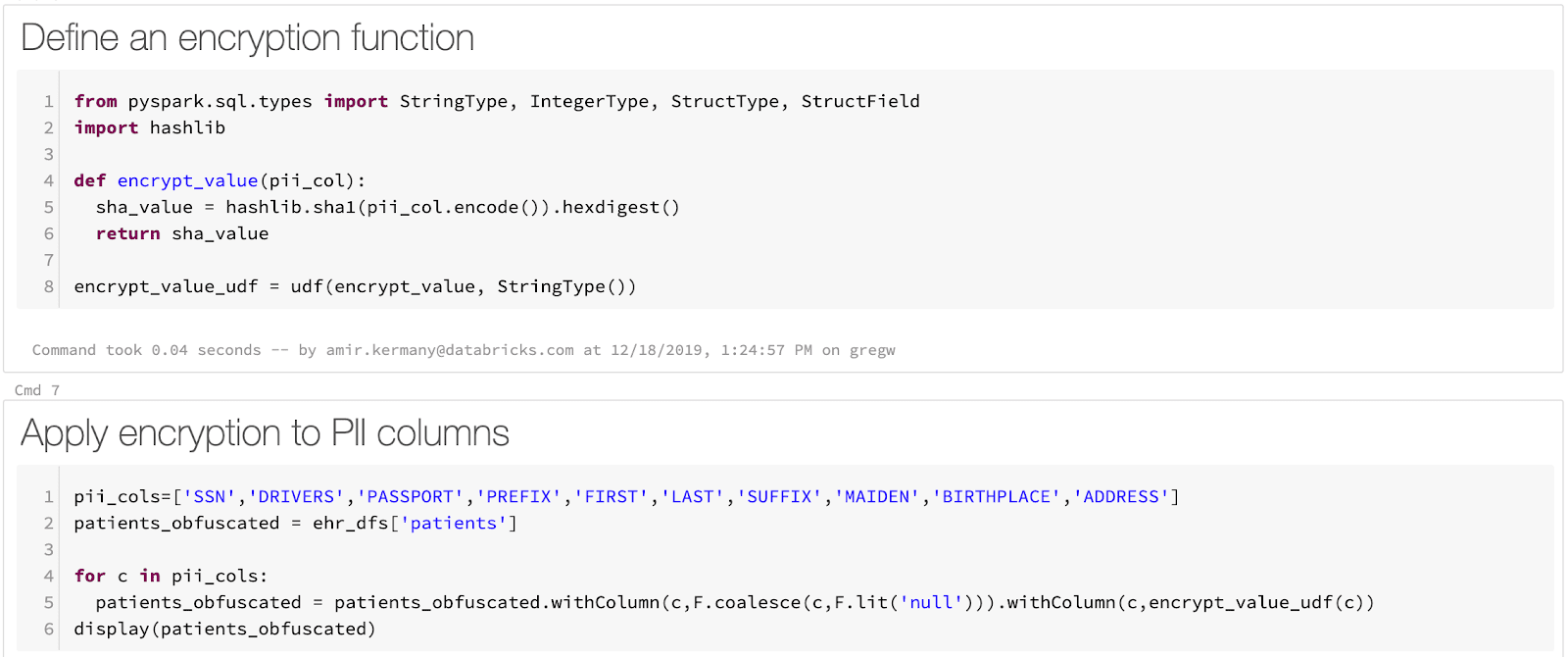
我们的原始CSV文件加载到三角洲湖表是一个简单的过程。Apache火花原生支持加载CSV,我们能够加载文件每一行代码文件。而火花没有内置支持掩蔽φ,我们可以用火花丰富的支持用户定义函数(udf,AWS|Azure)来定义一个任意函数,确定性PIIφ和面具字段。在我们的示例中笔记本,我们使用Python函数计算SHA1哈希。最后,将数据保存到三角洲湖是一行代码。
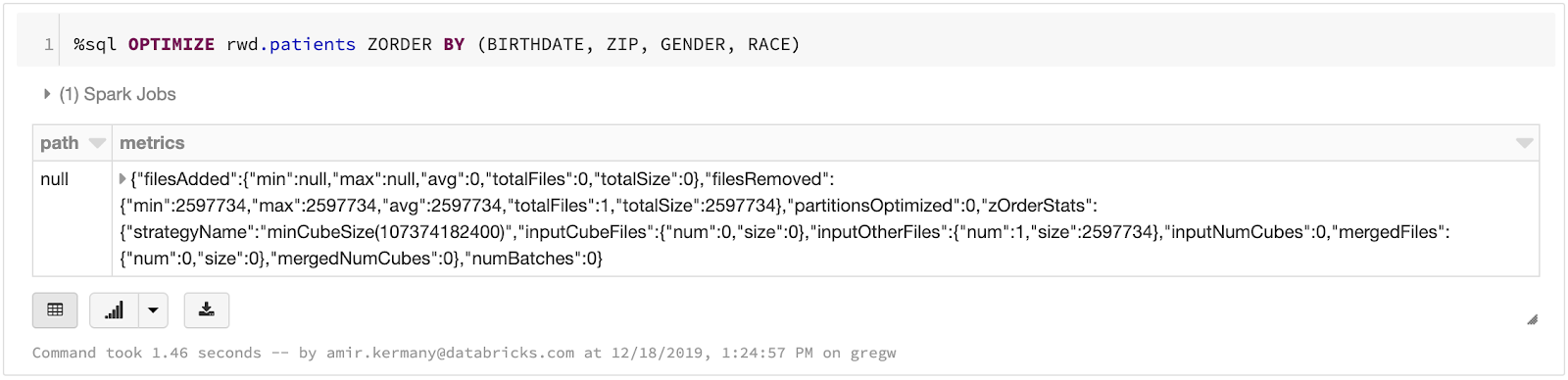
一旦数据被加载到三角洲,我们可以优化表通过运行一个简单的SQL命令。在我们的示例中并发症预测引擎,我们需要快速查询在病人ID和他们评估的条件。通过使用三角洲湖z值的命令,我们可以优化表可以快速查询维度。我们做过的一个最后的黄金表,已加入了几个我们的银表一起实现数据表示我们需要为我们的仪表板。
现在我们已经准备好了,我们的数据集,我们将构建仪表盘并存状况让我们去探索,或者更简单地说,通常同时发生在一个病人的条件。有些时候,这些可以前体/风险因素,例如,高血压是一个众所周知的中风和其他心血管疾病的危险因素。通过发现和监控并存状况,和其他健康统计数据,我们可以通过识别风险和提高护理建议病人在他们可以采取的预防措施。最终,确定并发症是计数锻炼!我们需要确定患者的不同情况和条件B,这意味着它可以做所有的完全使用火花SQL SQL。在仪表板中,我们将遵循一个简单的三个步骤:
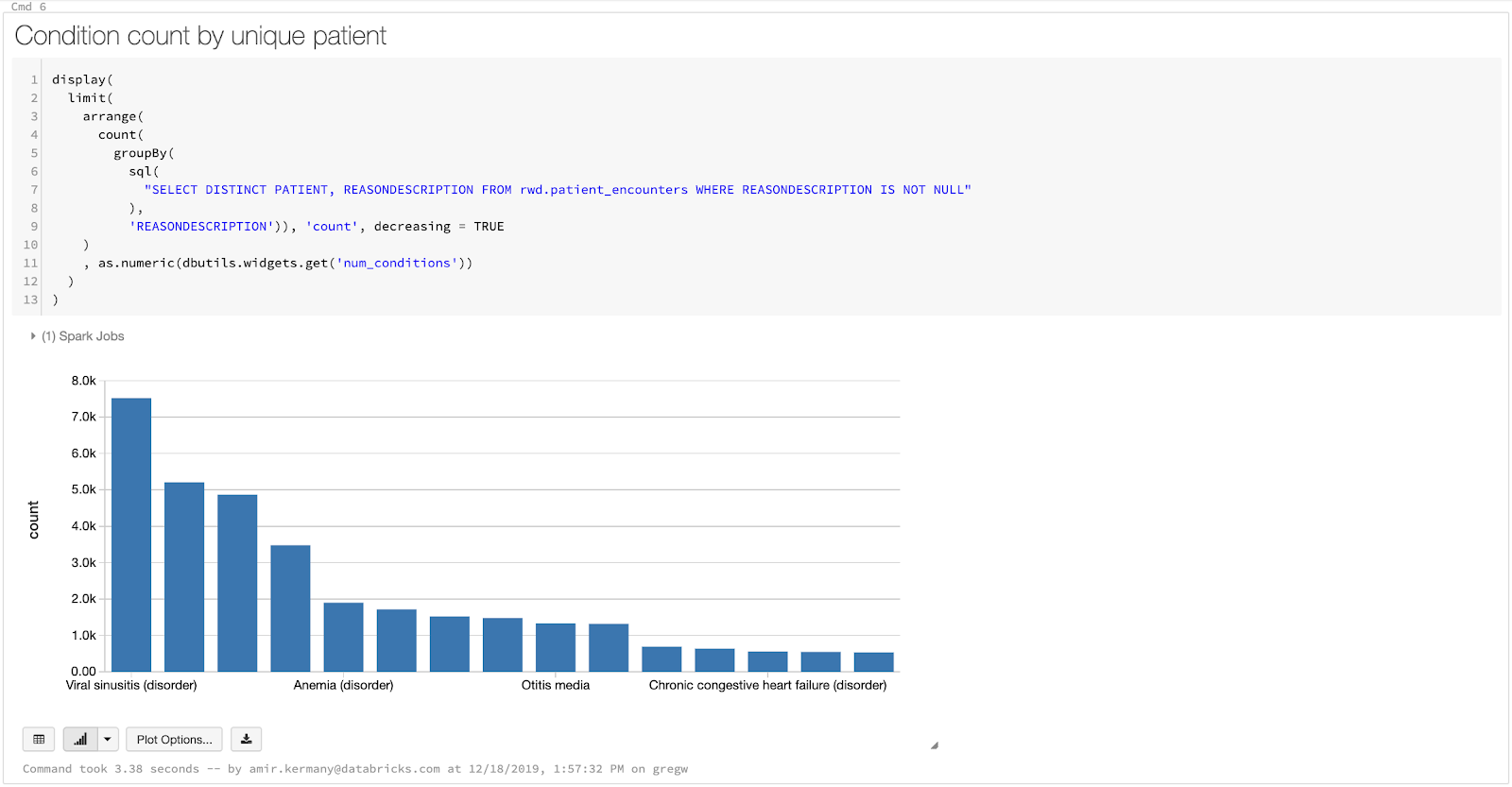
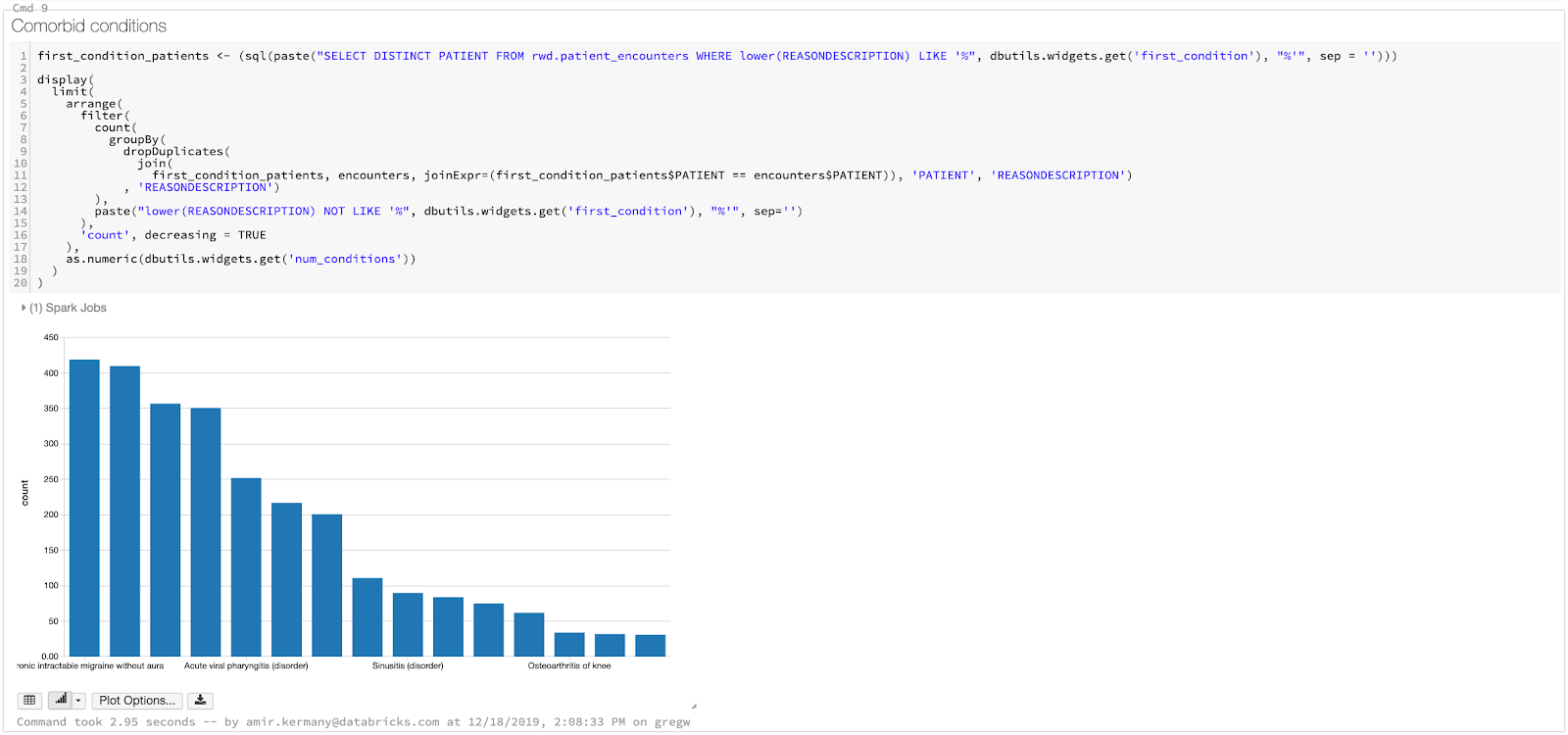
而数据科学家正在迅速迭代了解趋势躺在他们的数据集可能是快乐的工作在一个笔记本,我们会遇到许多用户(医生、公共卫生官员和研究人员,业务分析师、计费分析师)谁不感兴趣看到代码的分析。通过使用内置的仪表盘函数,我们可以隐藏的代码和关注我们生成的可视化。因为我们小部件添加到我们的笔记本,用户仍然可以提供输入疾病比较的笔记本和改变。
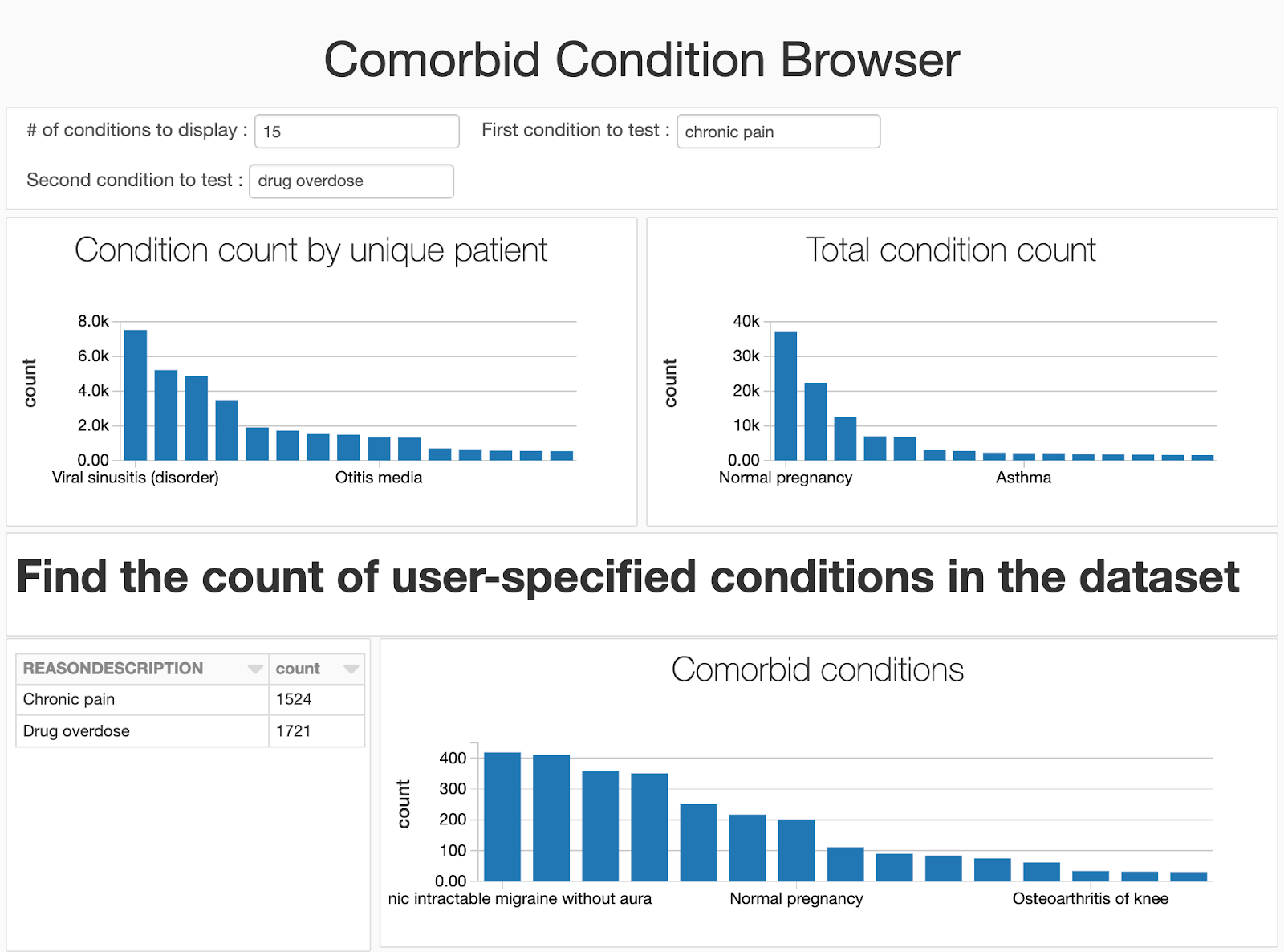
在这个博客中,我们制定了构建一个可伸缩的基本面健康数据湖三角洲湖和一个简单的合并症仪表板。了解更BOB低频彩多关于使用三角洲湖存储和处理健康和临床数据集: