介绍
砖三角洲湖是一个统一的数据管理系统,使数据可靠性和快速分析云数据的湖泊。在这篇文章里,我们将peek引擎盖下面检查使砖三角洲秒内能够筛选pb的数据。特别是,我们讨论数据不和ZORDER集群。
这两个特性使相结合砖运行时极大地减少了需要扫描的数据量为了回答高度选择性对大型三角洲表查询,通常转化成数量级运行时改进和成本节约。
你可以看到这些特性在行动主旨演讲从2018年火花+人工智能峰会,苹果的多米尼克•Brezinski展示了他们的用例砖三角洲作为一个统一的解决方案的环境科学工程和数据网络安全监控和威胁的反应。
如何使用数据跳过和ZORDER集群
利用数据跳过,所有你需要做的就是使用砖三角洲。无论何时你的功能是自动和踢SQL查询或数据集操作包括过滤器的形式“列op文字”,地点:
列是一些砖三角洲的属性表,无论是顶级或嵌套,其数据类型是字符串/数字/日期/时间戳人事处是一个二进制比较运算符,StartsWith / %’的模式,或
文字是一个显式的(列表)值(s)相同数据类型的列
和/或/不是也支持,以及“文字op柱”谓词。
如下我们将解释,尽管数据不总是踢在上述条件得到满足时,它可能并不总是非常有效。但是,如果你经常有一些列过滤器,要确保的快,那么你可以显式地优化你的数据布局对跳过有效性通过运行下面的命令:

不仅仅是这样。首先,让我们后退一步,把东西放在上下文。
数据如何跳过和ZORDER集群工作吗
这些特性的通用用例是提高针种查询的性能对巨大的数据集。典型的RDBMS的解决方案,即二级索引,是不切实际的在大数据背景下由于可伸缩性方面的原因。如果您熟悉大数据系统(Apache火花、蜂巢、黑斑羚、Vertica,等等),你可能已经思考:(水平)分区。快速提醒:在火花,就像蜂巢一样,分区作品通过一子目录中为每一个不同的分区列(s)的价值。分区列上查询过滤器(s)可以从中受益分区修剪,即,avoid scanning any partition that doesn’t satisfy those filters. The main question is:你分区列做什么?和典型的回答是:你最有可能的过滤器在时间敏感的查询。但是…如果有多个(4 +)说,同样相关列?在这种情况下,问题是,你最终得到的大量的独特的组合值,这意味着大量的分区,因此文件。有数据跨越许多小文件提出以下主要问题:
元数据是数据本身一样大,导致各种驾驶员一侧操作的性能问题特别是,文件清单的影响,变得非常缓慢压缩效果被破坏,导致浪费空间和较慢的IO
所以当数据分区在火花一般适合于日期或分类列,不适合高聚合度列,在实践中,它通常局限于一个或最多两个列。
数据不
除了分区修剪,另一个用于数据仓库的常用技术,但目前缺乏火花,I / O修剪基于小物化总量。简而言之,我们的想法是:
跟踪简单的统计数据如最小和最大值在一定粒度与I / O相关的粒度。利用这些统计数据查询计划时为了避免不必要的I / O。
这正是砖三角洲数据不特性是什么。随着新数据插入到砖δ表,文件级最小/最大统计收集所有列(包括嵌套的)支持的类型。然后,当有一个查找表查询,砖三角洲首先咨询这些统计数据,以确定哪些文件可以安全地忽略。但是,正如他们所说,一个GIF抵得上一千字,所以给你: 一方面,这是一个轻量级的,灵活的(粒度可调)技术,很容易实现和思考。也是完全正交的分区:伟大的除了它工作,但不依赖于它。另一方面,这是一个概率索引方法,像布鲁姆过滤器,可能给假阳性,特别是当数据不是集群。这给我们带来了我们的下一个技巧。
一方面,这是一个轻量级的,灵活的(粒度可调)技术,很容易实现和思考。也是完全正交的分区:伟大的除了它工作,但不依赖于它。另一方面,这是一个概率索引方法,像布鲁姆过滤器,可能给假阳性,特别是当数据不是集群。这给我们带来了我们的下一个技巧。
ZORDER集群
I / O是有效的数据需要修剪集群所以min-max范围狭窄,理想情况下,重叠。这样,对于一个给定的点查找,min-max范围点击的数量最小化,即跳过最大化。有时,数据恰好是自然集群:单调递增id、列与插入时间(例如,日期/时间戳)或分区键(例如,pk_brand_name——model_name)。当事实并非如此,你仍然可以通过显式地执行聚类分类范围分区你的数据再插入。但是,假设你的工作负载由同样频繁/相关单列谓词(如。n = 4)不同的列。在这种情况下,“线性”或称“词典”或“长短”排序的所有n列将强烈支持第一个指定,集群其价值观完全。然而,它不会做太多,如果任何东西(取决于有多少重复的值在第一列),第二个,等等。因此,在所有的可能性,就没有集群在第n列,因此没有跳过可能涉及它的查找。那么我们怎样才能做得更好?更准确地说,我们如何实现类似跳过有效性以及每个个体维度?如果我们仔细想想,我们寻找的是一种将n维数据点分配给数据文件,这样点分配给相同的文件也一起互相接近的每个单独n维度。换句话说,我们想地图多维分维值的方式保存位置。这是一个众所周知的问题,不仅在数据库中遇到的世界,但也在计算机图形学等领域和geohash。答案是:保空间曲线,最常用的是z值和希尔伯特曲线。下面是一个简单的例子如何申请z值提高数据数据布局对于跳过有效性。传说:
灰色的点=数据点如棋盘坐标灰色的盒=数据文件;在这个例子中,我们的目标是为每个文件的4点黄色的盒=数据文件的读取给定查询绿色点=数据点通过查询的过滤和查询的答案红色的点=数据点读,但不满足过滤;“假阳性”
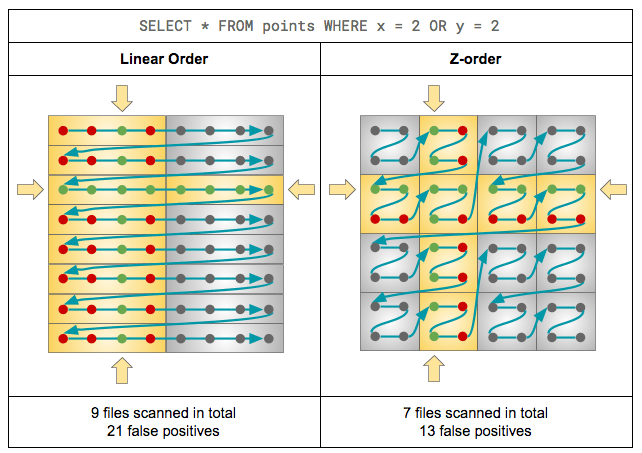
在网络安全分析一个例子
好的,足够的理论,让我们回到火花+人工智能峰会主题,看看砖三角洲可用于实时网络安全威胁的反应。说你正在使用兄弟流行的开源网络流量分析仪,产生实时、全面的网络活动信息。你的产品是更受欢迎,更多你的服务习惯,因此,更多的数据兄弟开始输出。写这以足够快的速度数据持久存储在一个更结构化的方法为未来处理是第一大数据挑战你的脸。这正是砖δ设计首先,使这个任务简单和可靠。你可以做的是使用结构化数据流管你的兄弟康涅狄格州到date-partitioned砖三角洲的表,你会定期运行优化这样你的日志记录最终均匀分布在中等数据文件。但这并不是这篇文章的重点,因此,出于演示目的,我们保持简单和使用非,非分区数据砖三角洲表组成的均匀分布随机数据。面对潜在的网络攻击威胁,这种临时数据分析你要运行是一系列的互动“查找”记录网络连接数据。例如,“找到所有最近的网络活动涉及这可疑的IP地址。“我们将模型假设它是由这个工作负载基本的查找查询与单列平等过滤器使用随机抽样IPs和港口。这样的简单查询IO-bound,即他们的运行时线性依赖于扫描的数据量。这些查询通常会变成全表扫描,可能运行几个小时,这取决于你多少数据存储和多远你想回来。你的最终目标是可能减少的总量时间运行这些查询,但是,出于演示目的,我们定义我们成本函数随着总记录数的扫描。这个指标应该是一个好的近似的总运行时和定义良好和确定性的好处,让有兴趣的读者很容易和可靠地重现我们的实验。我们去,我们会一起工作,具体:
情况下类ConnRecord(src_ip:字符串,src_port: Int, dst_ip:字符串,dst_port: Int)defrandomIPv4(接待员:随机)=Seq。填满(4)(r.nextInt (256年))。mkString(“。”)defrandomPort(接待员:随机)=r。nextInt(65536年)defrandomConnRecord(接待员:随机)=ConnRecord(src_ip = randomIPv4 (r),src_port = randomPort (r),dst_ip = randomIPv4 (r),dst_port = randomPort (r))
情况下类TestResult(numFilesScanned:长,numRowsScanned:长,numRowsReturned:长)deftestFilter(表:字符串,过滤器:字符串):TestResult={val查询=年代“SELECT COUNT (*)美元的表在哪里美元的过滤器”瓦尔(结果、指标)= collectWithScanMetrics (sql(查询)。作为(长))TestResult (numFilesScanned =指标(“filesNum”),numRowsScanned = metrics.get (“numOutputRows”).getOrElse (0L),numRowsReturned = result.head)}/ /运行testFilter()在所有给定的过滤器和返回的行百分比跳过/ /平均代替数据跳过有效性:0不好,1是好的def skippingEffectiveness(表:字符串过滤器:Seq [字符串):双= {…}
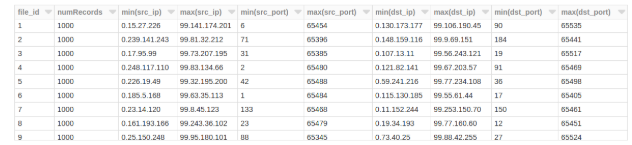
100年的一个随机生成的表文件,每个1 k随机记录,可能看起来像:
选择row_number()在(订单通过文件)作为file_id,数(*)作为numRecords,最小值(src_ip),马克斯(src_ip),最小值(src_port),马克斯(src_port),最小值(dst_ip),马克斯(dst_ip),最小值(dst_port),马克斯(dst_port)从(选择input_file_name ()作为文件,*从conn_random)集团通过文件
看到每个文件的min-max范围覆盖几乎整个域的值,很容易预测,将会有很少的机会文件跳过。我们的评估功能确认:
skippingEffectiveness (connRandom singleColumnFilters)

好了,这是意料之中的,我们的数据是随机生成的,因此不存在相关性。让我们试着在写作之前明确排序数据。
spark.read.table (connRandom).repartitionByRange ($“src_ip”美元,“src_port”美元,“dst_ip”美元,“dst_port”)/ /或只是.sort(美元)“src_ip”美元,“src_port”美元,“dst_ip”美元,“dst_port”).write。格式(“δ”).saveAsTable (connSorted)
skippingEffectiveness (connRandom singleColumnFilters)
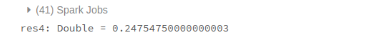
嗯,我们确实改善指标,但25%的仍然不是很好。让我们仔细看看:
val src_ip_eff = skippingEffectiveness (connSorted srcIPv4Filters)val src_port_eff = skippingEffectiveness (connSorted srcPortFilters)val dst_ip_eff = skippingEffectiveness (connSorted dstIPv4Filters)val dst_port_eff = skippingEffectiveness (connSorted dstPortFilters)

结果src_ip查找非常快,但其他所有人基本上是全表扫描。再说一次,这并不奇怪。如前所述,得到线性排序:结果数据集群完全沿着第一个维度(src_ip在我们的例子中),但几乎没有进一步的维度。
所以我们如何能做的更好吗?通过执行ZORDER集群。
spark.read.table (connRandom).write.format (“δ”).saveAsTable (connZorder)sql(年代“优化connZorder美元ZORDER由(src_ip src_port、dst_ip dst_port)”)
skippingEffectiveness (connZorder singleColumnFilters)

不少比0.25得到的线性排序,对吧?另外,分解:
val src_ip_eff = skippingEffectiveness (connZorder srcIPv4Filters)val src_port_eff = skippingEffectiveness (connZorder srcPortFilters)val dst_ip_eff = skippingEffectiveness (connZorder dstIPv4Filters)val dst_port_eff = skippingEffectiveness (connZorder dstPortFilters)
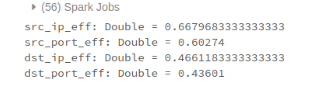
几个值得注意的观察:
预计跳过有效性在src_ip现在低于线性排序,因为后者将确保完美的集群,与z值。然而,其他列的分数现在几乎一样好,不像之前的时候0。也期望z值的列越多,效率越低。
例如,由(ZORDER src_ip dst_ip)达到0.82。这是由你来决定你最关心什么过滤器。
在实际用例提出火花+人工智能峰会上,一个典型的跳过有效性在src_ip y = x和dst_ip =查询甚至更高。的数据集504字节(超过11万亿行),只有36.5 tb需要扫描数据由于跳过。这是一个显著的减少92.4%的字节数和93.2%的行数。
结论
使用砖跳过和三角洲的内置数据ZORDER聚类特性,大云数据湖泊可以查询在几秒钟内通过跳过文件与查询无关的。在真实的网络安全分析用例,93.2%的记录504字节数据集被跳过一个典型的查询,查询时间减少到两个数量级。
换句话说,砖三角洲可以加快查询的100 x。
请注意:数据跳过已作为一个独立选项以外的砖δ在过去作为一个单独的预览。该选项将在不久的将来被弃用。我们强烈推荐你搬砖三角洲利用数据跳跃能力。
阅读更多
这里有一些资产:
对开源三角洲湖感兴趣吗?bob下载地址
访问在线三角洲湖中心要了解BOB低频彩更多,请下载最新的代码,并加入三角洲湖社区。