





以三角洲湖为依托,构建现代临床健康数据湖
医疗保健行业是最大的数据生产者之一。事实上,平均每个医疗机构占用近9pb的数据……
2020年4月21日 在工程的博客
医疗保健行业是最大的数据生产者之一。事实上,一般的医疗机构都在坐着将近9pb的医疗数据.电子健康记录(EHR)、数字医疗图像和可穿戴设备的兴起促成了这种数据爆炸。例如,大型供应商的EHR系统可以对数百万个医疗测试、临床互动和处方治疗进行分类。从这些人口规模的数据中学习的潜力是巨大的。通过在这些数据集上构建分析仪表板和机器学习模型,医疗保健组织可以改善患者体验并推动更好的健康结果。以下是一些现实世界的例子:
预防新生儿败血症 |
慢性疾病的早期检测 |
追踪人群疾病 |
防止索赔欺诈和滥用 |
尽管有机会通过分析和机器学习来改善患者护理,但医疗保健组织仍面临着经典的大数据挑战:
似乎这还不够具有挑战性,数据存储还必须支持需要运行特别转换的数据科学家,例如创建患者的纵向视图,或使用机器学习技术构建预测性见解。
幸运的是,三角洲湖这是一种开源存储层,可以将ACID事务带到大数据工作负载中Apache火花TM可以通过提供事务性存储来帮助解决这些挑战,该存储支持对不同数据的快速多维查询以及丰富的数据科学功能。借助Delta Lake和Apache Spark,医疗保健组织可以为分析和ML构建可扩展的临床数据湖。
在本系列博客中,我们将通过一个简单的示例开始,演示如何将Delta Lake用于健康和临床数据的临时分析。在以后的博客中,我们将讨论Delta Lake和Spark如何耦合在一起来处理流HL7/FHIR数据集。最后,我们将介绍一些可以在使用Delta lake构建的健康数据湖之上运行的数据科学用例。
为了演示Delta Lake如何更容易地使用大型临床数据集,我们将从一个简单但强大的用例开始。我们将构建一个仪表板,使我们能够识别患者群体中的共病条件(同一个人同时发生的一种或多种疾病或条件与另一种疾病同时发生)。为此,我们将使用模拟的EHR数据集,该数据集由Synthea模拟器,可透过Databricks数据集(AWS|Azure).该数据集代表了来自马萨诸塞州的约1.1万名患者,存储在12个CSV文件中。在屏蔽受保护的健康信息(PHI)并将表连接在一起以获得下游查询所需的数据表示之前,我们将加载CSV文件。一旦数据得到完善,我们将使用SparkR构建一个仪表板,允许我们在数据集上交互式地探索和计算常见的健康统计数据。
这个用例是一个非常常见的起点。在临床环境中,我们可以通过观察共病来理解病人病情加重的风险.从医学编码和财务的角度来看,研究共病可能会让我们做到确定常见的医疗编码问题这会影响报销。在药物研究中,寻找具有共同基因证据的共病可能会给我们一个更深入地了解基因的功能.
然而,当我们考虑底层的分析架构时,我们也是在一个起点上。我们可能会尝试加载流EHR数据来进行实时分析,而不是在一个大批量中加载数据。我们可能会使用机器学习用例,而不是使用提供简单见解的仪表板,例如训练一个机器学习模型,该模型使用最近患者遭遇的数据来预测疾病的进展。这在急诊室环境中非常强大,流数据和ML可用于实时预测患者改善或下降的可能性。
在本博客的其余部分,我们将详细介绍仪表板的实现。我们将首先使用Apache Spark和Delta Lake来ETL我们模拟的EHR数据集。一旦数据准备好进行分析,我们将创建一个笔记本,在我们的数据集中识别共病条件。利用Databricks的内置功能(AWS|Azure),然后我们可以直接将笔记本转换为仪表盘。
首先,我们需要将CSV数据转储加载到可以用于分析工作负载的一致表示中。通过使用Delta Lake,我们可以加速将要运行的许多下游查询。Delta Lake支持z排序,这使我们能够有效地跨多个维度查询数据.这对于处理EHR数据至关重要,因为我们可能希望按患者、日期、护理机构或病情等对数据进行切片和切分。此外,Databricks中的托管Delta Lake提供了额外的优化,可以加速对数据集的探索性查询。Delta Lake还对我们的工作进行了未来证明:虽然我们目前没有使用流数据,但将来我们可能会使用来自EHR系统的实时流,并且Delta Lake的ACID语义(AWS|Azure)使使用流的工作简单可靠。
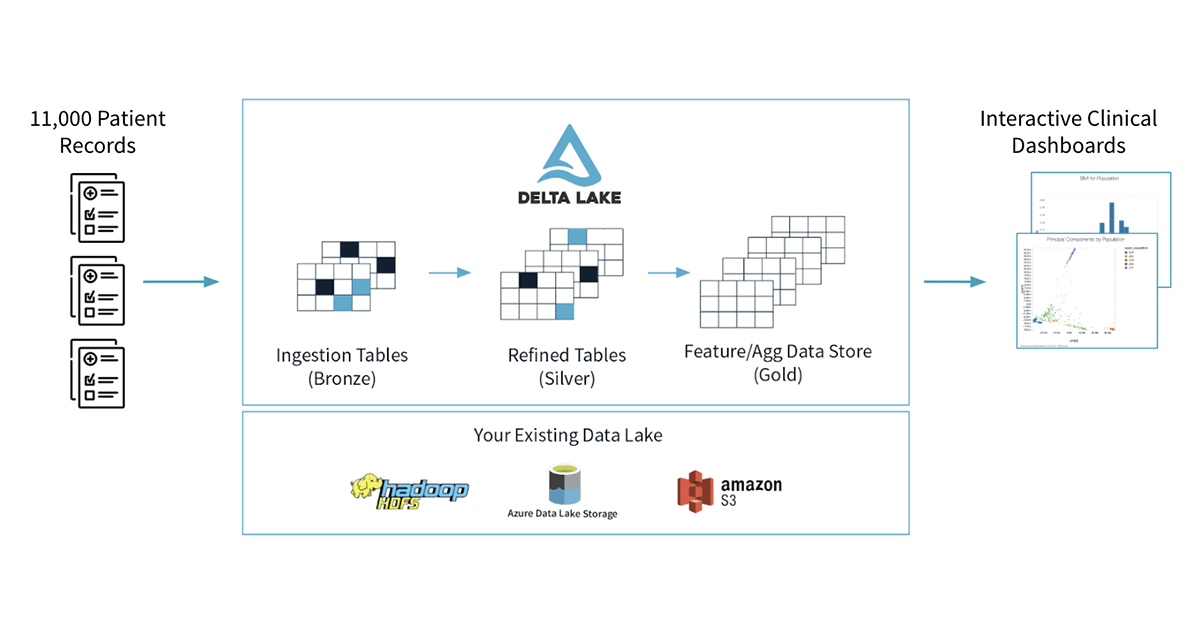
我们的工作流程遵循如下图所示的几个步骤。我们将从8个不同的CSV文件中加载原始/青铜数据开始,我们将屏蔽表中存在的任何PHI,我们将写出一组银表。然后,我们将把银表连接在一起,以获得更容易用于下游查询的表示。
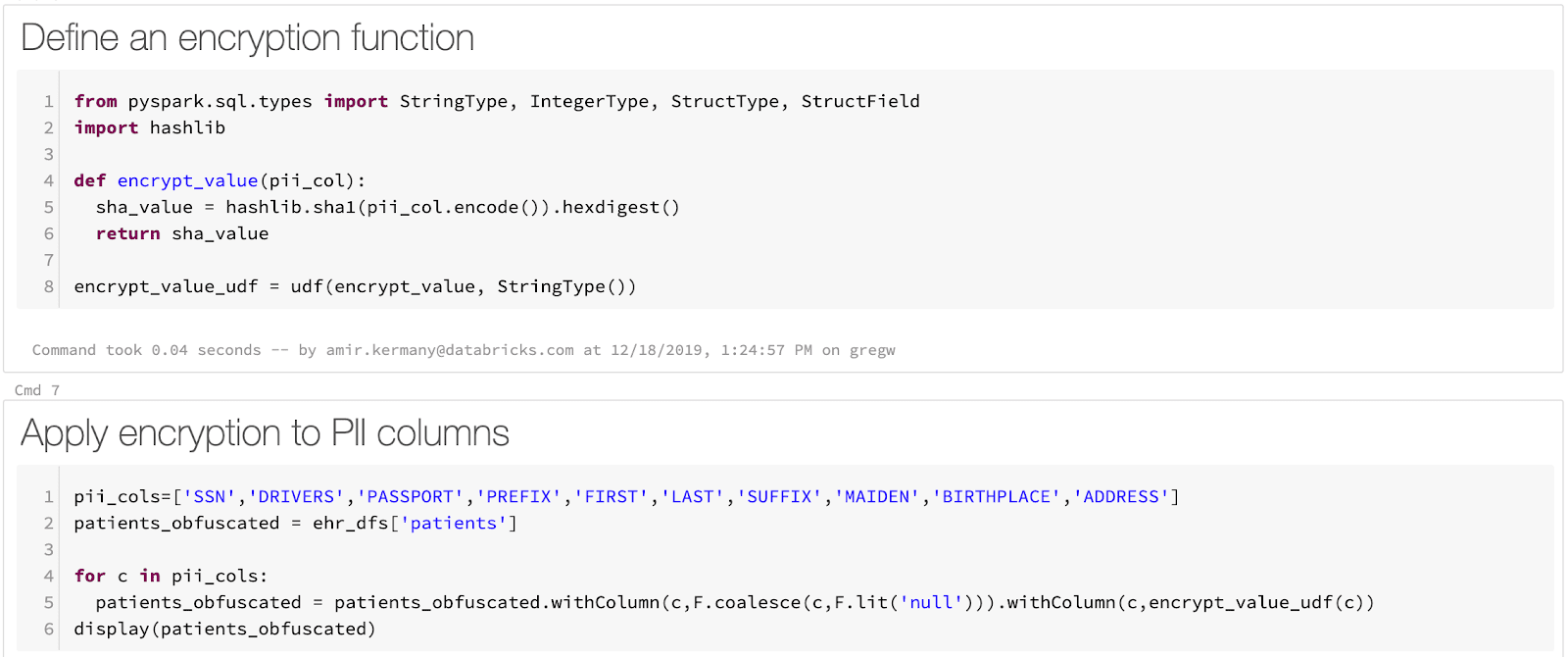
将原始CSV文件加载到Delta Lake表中是一个简单的过程。Apache Spark有加载CSV的原生支持,我们可以通过每个文件一行代码来加载文件。虽然Spark没有对屏蔽PHI的内置支持,但我们可以使用Spark对用户定义函数(udf,AWS|Azure)定义一个任意函数,该函数确定性地用PHI或PII掩盖字段。在我们的示例笔记本中,我们使用Python函数来计算SHA1哈希。最后,将数据保存到Delta Lake只需要一行代码。
一旦数据加载到Delta中,我们就可以通过运行一个简单的SQL命令来优化这些表。在我们的共病病情预测引擎示例中,我们将希望快速查询患者ID和他们所评估的病情。通过使用Delta Lake的z排序命令,我们可以优化该表,以便可以快速地按任何维度查询它。我们已经在最后的一个金表上实现了这一点,它将几个银表连接在一起,以实现仪表板所需的数据表示。
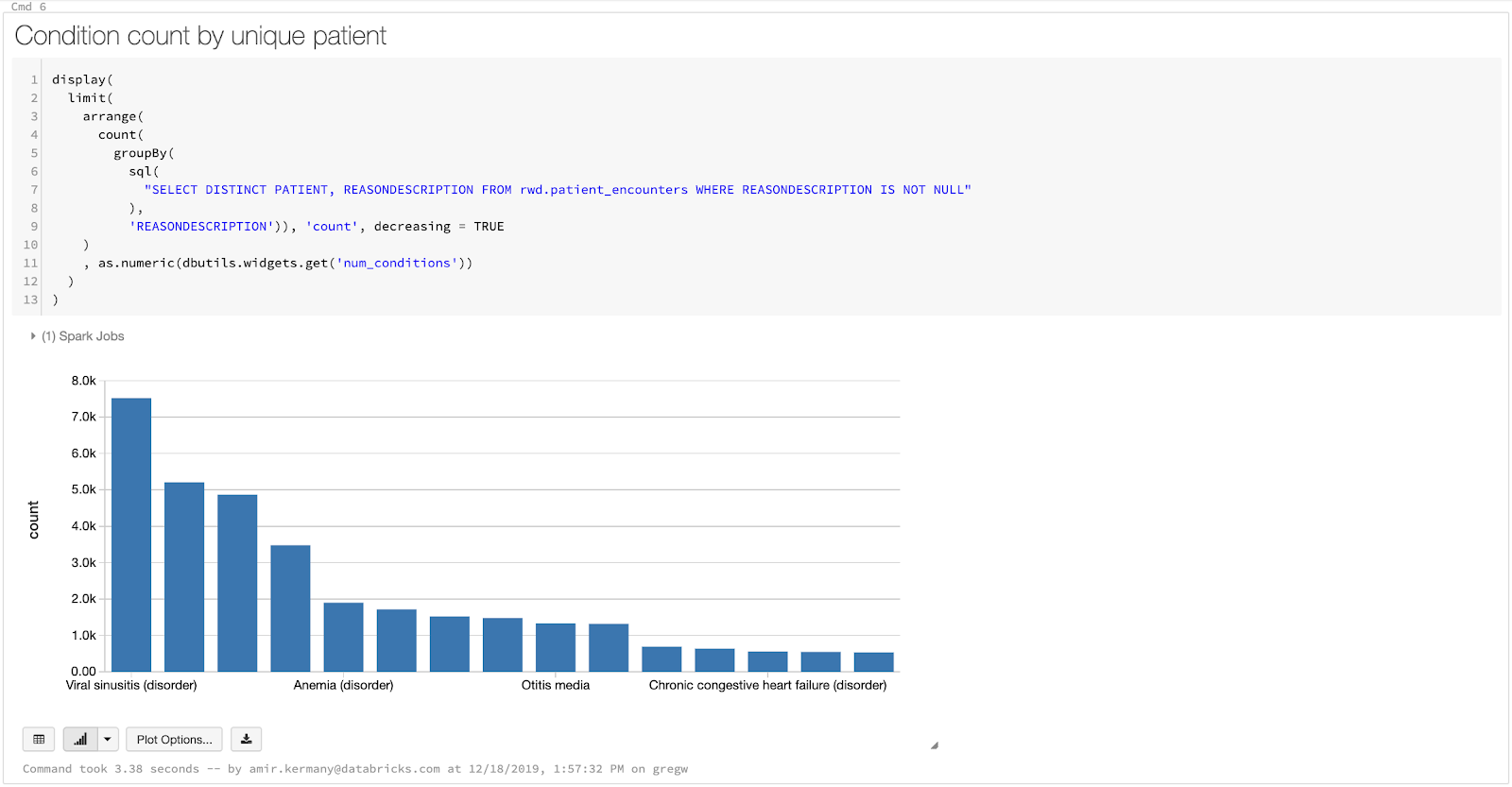
现在我们已经准备好了数据集,我们将构建仪表板,使我们能够探索共病条件,或者更简单地说,通常在单个患者身上同时发生的条件。有些时候,这些可能是前兆/危险因素,例如,高血压是中风和其他心血管疾病的一个众所周知的危险因素。通过发现和监测共病状况以及其他卫生统计数据,我们可以通过识别风险并建议患者采取预防措施来改善护理。最终,确定合并症是一个计算练习!我们需要确定同时患有A和B病症的不同患者,这意味着可以使用Spark SQL完全在SQL中完成。在我们的仪表板中,我们将遵循简单的三步流程:
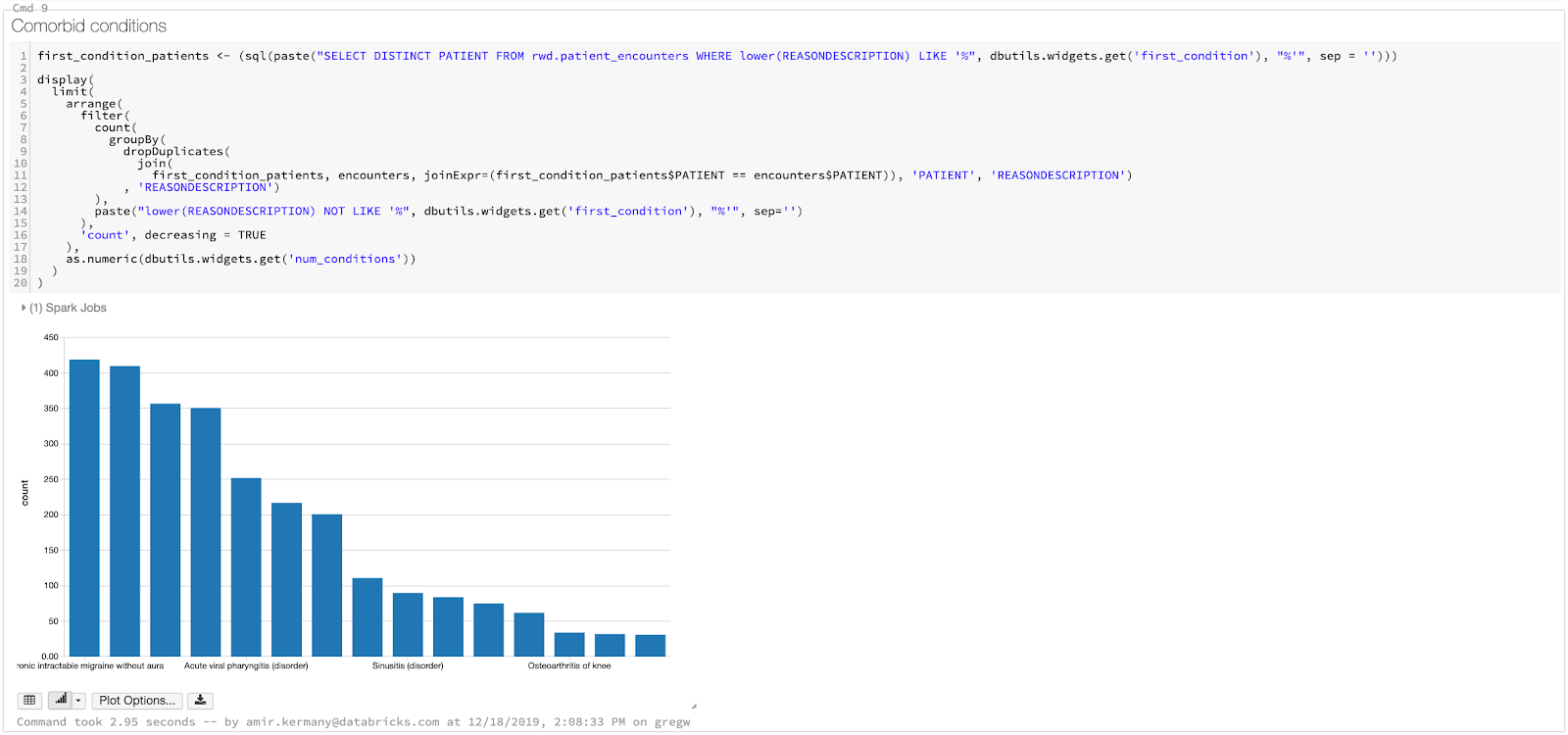
虽然快速迭代以了解数据集中趋势的数据科学家可能喜欢在笔记本上工作,但我们会遇到许多用户(临床医生、公共卫生官员和研究人员、运营分析师、账单分析师),他们对查看分析背后的代码不太感兴趣。通过使用内置的仪表板功能,我们可以隐藏代码并专注于我们生成的可视化。由于我们在笔记本中添加了小部件,用户仍然可以向笔记本提供输入,并更改要比较的疾病。
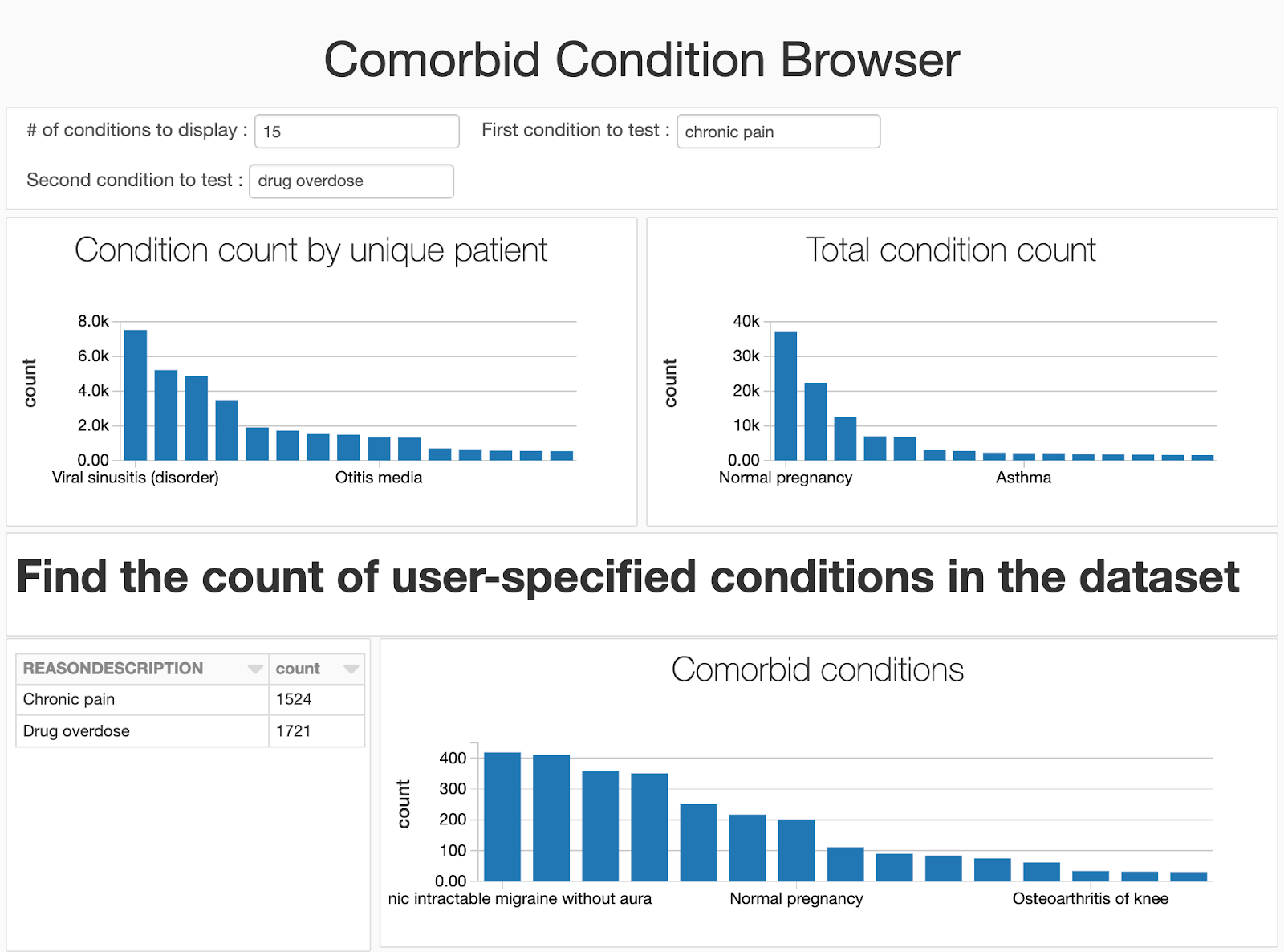
在这篇博客中,我们阐述了使用Delta lake和简单的共病仪表板构建可扩展健康数据湖的基本原理。要了解BOB低频彩有关使用Delta Lake存储和处理健康和临床数据集的详细信息,请执行以下操作: