




检测数据偏差使用世鹏科技电子和机器学习
尝试检测数据偏差使用世鹏科技电子笔记本按需复制下面的步骤,看我们的研讨会学习更多。BOB低频彩StackOverflow的……
2022年2月2日 在数据科学和毫升
随着机器学习(ML)的应用,特别是深度学习(DL)模型在决策,是越来越重要的通过黑盒和证明等关键业务决策基于的模型的输出。举个例子,如果一个毫升模型拒绝客户的贷款请求或对等贷款信用风险赋值给一个特定的客户,给业务涉众一个解释关于为什么这个决定可能是一个强大的工具在鼓励模型的适应性。在许多情况下,可判断的ML不仅仅是一个业务需求但监管要求理解为什么某个决定或选择给客户。沙普利加解释(世鹏科技电子)是一个重要的工具可以利用可辩解的AI和帮助建立信任的结果毫升模型和神经网络在解决业务问题。
世鹏科技电子是一种先进的基于框架模型解释博弈理论。涉及的方法找到一个特性之间的线性关系模型和模型输出为每个数据点在你的数据集。使用这个框架,您可以解释你的模型的输出全球或本地。全球可解释性有助于你理解多少每个特性导致结果积极的还是消极的。另一方面,当地可解释性有助于你理解每个特性的影响对于任何给定的观察。
最常见的世鹏科技电子实现数据科学界普遍采用的是单一节点上运行的机器,这意味着他们在单核运行所有的计算,不管有多少核心是可用的。因此,他们不利用分布式计算能力和有界的一个核心的局限性。
在这篇文章中,我们将演示一个简单的方法在多台计算机上并行化世鹏科技电子价值计算,专门为当地的可解释性。我们将解释如何解决尺度与越来越多的行和列的数据集。最后,我们将介绍一些我们的发现对什么可行、什么时避免并行世鹏科技电子计算与火花。
实现explainability,世鹏科技电子模型转化为一个讲解员;单个模型的预测被解释为应用讲解员。有几种实现世鹏科技电子在不同的编程语言包括价值计算在Python中受欢迎的一个。在这个实现中,解释为每个观察,你可以申请一个讲解员适合您的模型。下面的代码片段说明了如何应用TreeExplainer随机森林分类器。
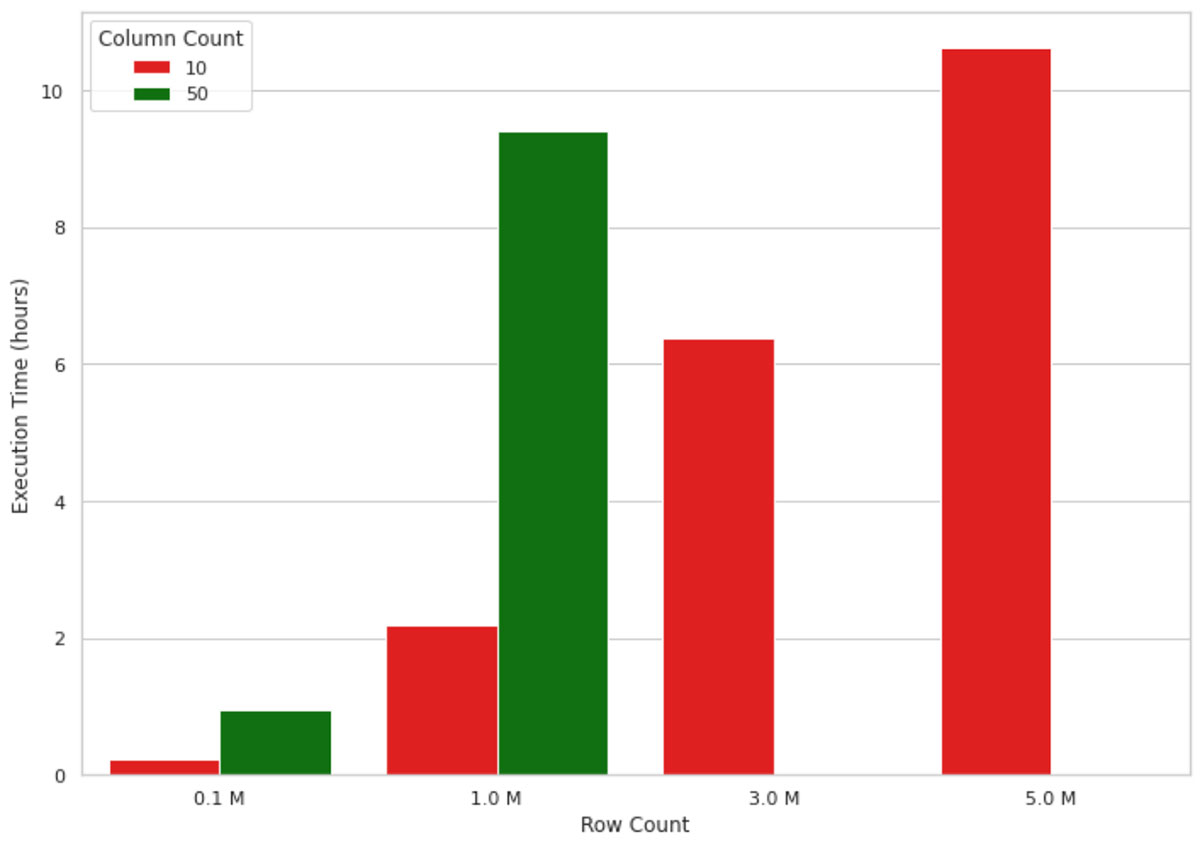
进口世鹏科技电子讲解员= shap.TreeExplainer (clf)shap_values = explainer.shap_values (df)这种方法适用于数据量小,但在解释一个毫升模型输出的数百万条记录,但是没有很好的伸缩性由于单节点的性质实现。举个例子,下面的图1中的可视化显示世鹏科技电子值计算的执行时间的增长在单个节点机(4核和30.5 GB内存)越来越多的记录。内存数据的机器跑出形状大于1 m 50行和列,因此,这些值是失踪的图中。正如你所看到的,执行时间的增长几乎线性的记录,这在真实场景中是不可持续的。例如,等待10个小时来理解为什么一个机器学习模型做出了模型预测既不有效也不接受在许多业务设置。
你可以看看来解决这个问题的一个方法是使用近似计算。你可以设置近似参数为Trueshap_values方法。这样,低分割在树上会有更高的权重和没有保证世鹏科技电子值与精确计算一致。这将加速计算,但你可能得到一个准确的解释模型输出。此外,近似参数只是TreeExplainers中可用。
另一种方法是利用分布式处理框架(如Apache火花™应用程序并行化的讲解员在多个内核。
分发世鹏科技电子计算,我们正在处理这Python实现,熊猫udf在PySpark。我们使用的是kddcup99数据集构建一个网络入侵探测器,能够区分坏的预测模型连接,称为入侵或攻击,和良好的正常连接。这个数据集已知的缺陷入侵检测的目的。然而,在这篇文章中,我们纯粹是专注于世鹏科技电子值计算,而不是底层毫升的语义模型。
我们为我们构建的两个模型实验是简单随机森林分类器训练数据集上10到50特性显示解决方案的可伸缩性在不同列的大小。请注意,原始数据集有少于50列,和我们有复制其中的一些列达到所需的数据量。我们所拥有的数据量试验从4 mb到1.85 gb。
在我们深入代码之前,让我们提供一个快速概述火花Dataframes和udf是如何工作的。火花Dataframes分布(行)在一个集群中,每个分组称为一个分区,每个分区的行(默认情况下)可以在1核心操作。这就是火花从根本上实现并行处理。熊猫熊猫udf是一个自然的选择,因为可以很容易地给世鹏科技电子性能。熊猫UDF,有时称为矢量化UDF,给我们更好的性能在Python UDF使用Apache箭头优化数据的传输。
下面的代码片段演示了如何并行化应用的讲解员PySpark熊猫UDF。我们定义了一个熊猫UDF调用calculate_shap然后通过这个函数mapInPandas。该方法用于并行化方法应用于PySpark dataframe。我们将使用这个UDF来运行我们的世鹏科技电子性能测试。
def calculate_shap (迭代器:迭代器[pd.DataFrame]) - >迭代器[pd.DataFrame]:为X迭代器:收益率pd.DataFrame (explainer.shap_values (np。数组(X), check_additivity =假)[0),列= columns_for_shap_calculation,)
return_schema = StructType ()为在columns_for_shap_calculation特性:return_schema = return_schema。添加(StructField(特性,FloatType ()))
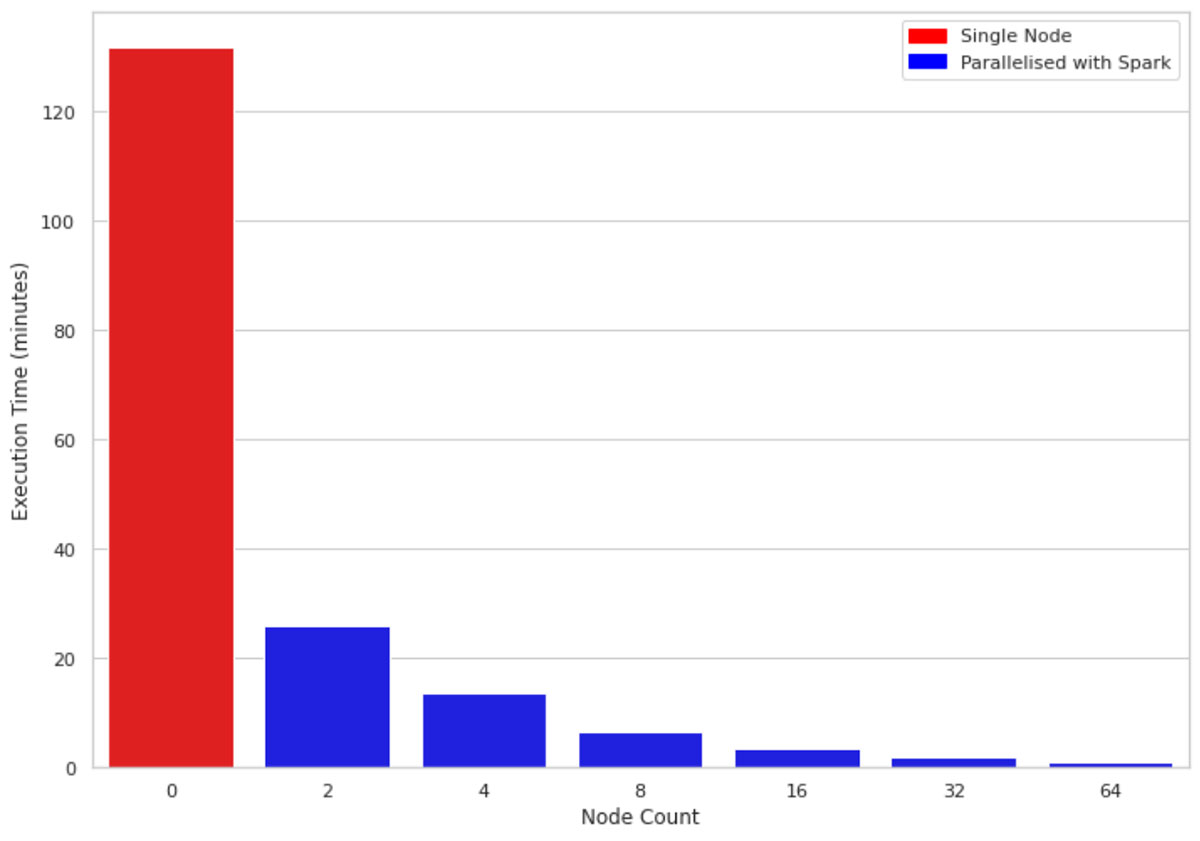
shap_values = df。mapInPandas(calculate_shap, schema=return_schema)图2比较的执行时间1 m行十列单节点机器上对集群的大小2、4、8、16、32、64。底层机器所有集群是相似的(4芯和30.5 GB的内存)。一个有趣的观察是,利用并行代码的核心在集群中的节点。因此,即使使用集群的大小2提高了性能几乎5倍。
由于世鹏科技电子是如何实现的,附加功能对性能的影响远远大于其他行。现在我们知道,世鹏科技电子值可以计算速度使用火花和熊猫UDF。接下来,我们将看看世鹏科技电子执行附加功能/列。
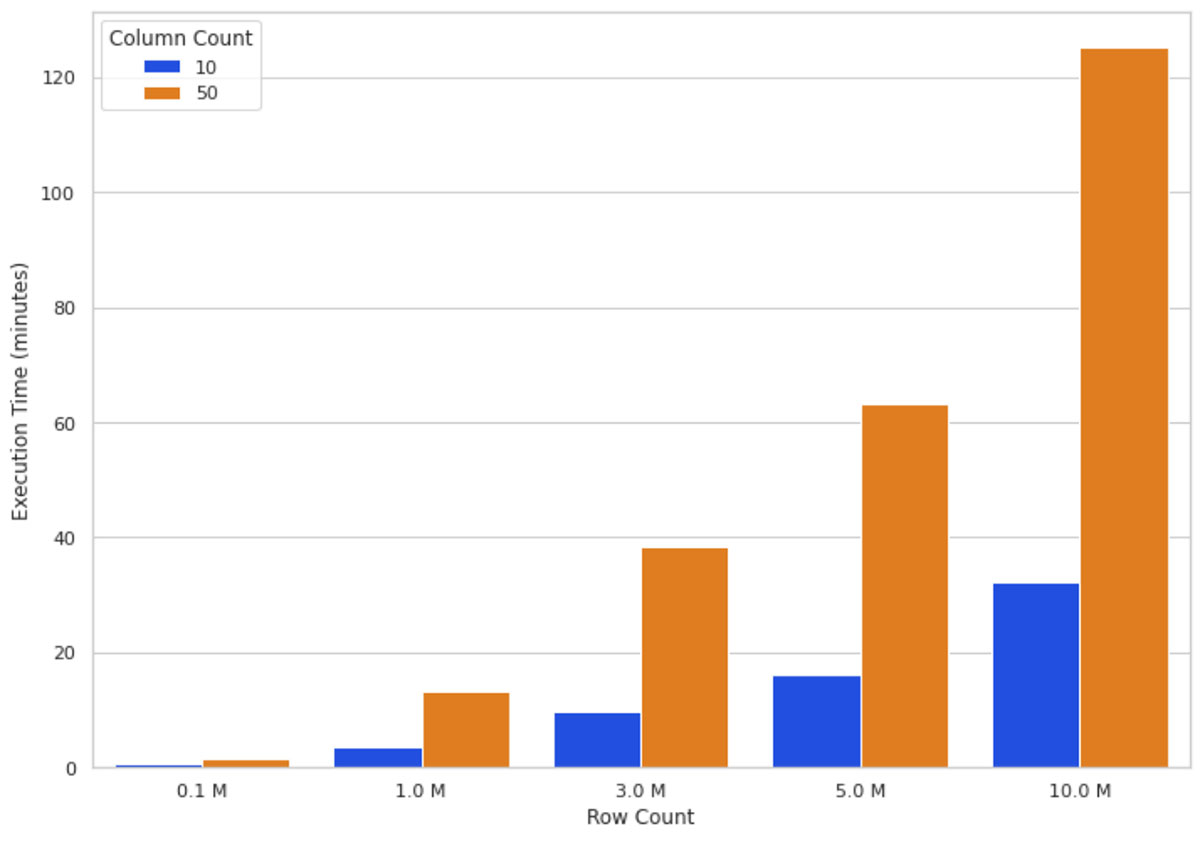
直观的数据大小增长意味着更多的计算通过的紧缩世鹏科技电子算法。图3说明了世鹏科技电子值16-node集群上执行时间不同数量的行和列。你可以看到扩展行增加了执行时间几乎成正比,即增加一倍的行数几乎翻执行时间。扩展的列数与执行时间的比例关系;添加一列增加近80%的执行时间。
这些观察结果(图2和图3)让我们得出这样的结论:数据越多,你越能扩展计算水平(添加更多的工作节点)来保持合理的执行时间。
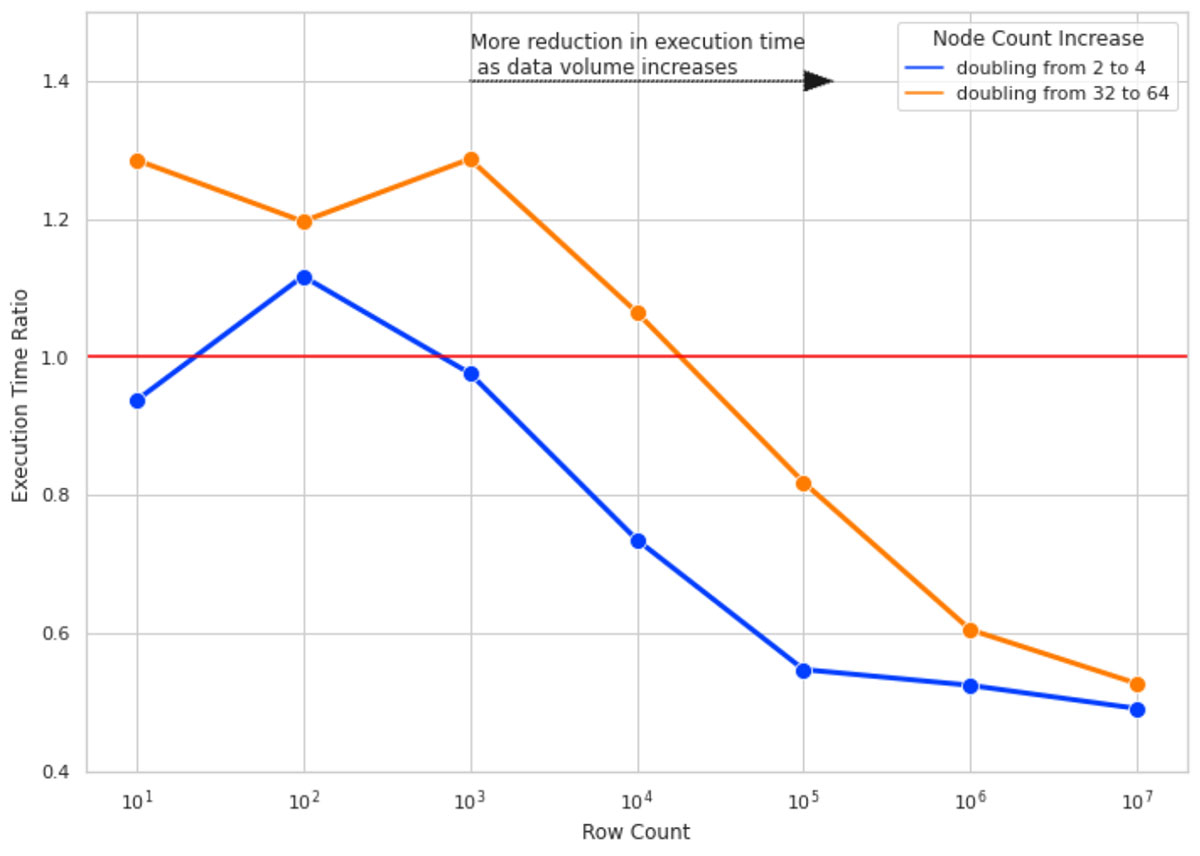
我们想要回答的问题是:当并行值得吗?当一开始使用PySpark并行化世鹏科技电子计算——甚至可能会增加计算的知识?我们建立了一个实验测量的影响集群规模翻倍提高世鹏科技电子计算执行时间。这个实验的目的是找出大小的数据证明扔更多的水平(即资源。,增加工作节点)的问题。
我们跑十世鹏科技电子计算列的数据行数为10,100年,1000年,等等10米。对于每个行数,我们测量了世鹏科技电子计算执行时间4次集群大小的2,4,32,64。执行时间比世鹏科技电子价值计算的执行时间比在更大的集群大小(4 - 64)在集群上运行相同的计算规模的一半的节点数(分别为2和32)。
图4说明了这个实验的结果。这里有外卖的关键:
如前所述,火花通过分区的概念实现了并行性;数据分割成块的行和每个分区处理由一个默认的核心。当数据最初由Apache火花读它未必创造最佳的分区计算您想要在您的集群上运行。特别是,世鹏科技电子计算值,我们可以获得更好的性能,实现我们的数据集。
罢工之间的平衡是很重要的创造足够小的分区,而不是很小,创建它们的开销超过并行计算的好处。
我们的性能测试,我们决定利用集群中的所有核心使用下面的代码:
df = df.repartition (sc.defaultParallelism)更大容量的数据你可能想要分区的数量设置为2或3倍的核心。关键是实验,找出最好的为您的数据划分策略。
如果你工作在一个砖笔记本,你可能想要避免使用显示()当基准测试执行时间的函数。显示()的使用不一定给你完整的转换需要多长时间;它有一个隐含的行限制,注入查询,根据操作你想测量,例如,写入一个文件,有额外的开销收集结果返回给司机。我们的执行时间是衡量使用火花的写方法使用“等待”格式。
在这篇文章中,我们介绍了一个解决方案来加速世鹏科技电子计算的并行PySpark和熊猫udf。然后我们评估解决方案的性能增加卷上的数据,不同的机器类型和改变配置。这里有外卖的关键:
垂直扩展——博文的目的是展示如何缩放水平与大型数据集可以提高世鹏科技电子计算的性能值。我们开始在集群中每个节点的前提下有4个核心,30.5 GB。在未来,这将是有趣的测试的性能扩展垂直和水平;例如,比较4个节点的集群之间的性能(4芯,每30.5 gb) 2节点的集群(8核,61 gb)。
序列化/反序列化——如前所述,核心原因之一使用熊猫udf在Python udf是熊猫udf使用Apache箭头提高JVM和Python之间的数据序列化/反序列化过程。时可能会有一些潜在的优化将引发数据分区转换成箭头批次记录,试验箭头批大小可能导致进一步的性能收益。
比较与分布式世鹏科技电子实现——它将会是很有趣的比较的结果我们的解决方案的分布式实现世鹏科技电子,等Shparkley。在进行这样的比较研究,这将是重要的,以确保输出两种解决方案都是类似的。

