



如何增量ETL和数据湖泊让生活更简单吗
2021年8月30日
通过John O 'Dwyer
在
工程数据
O ' reilly的早期预览版的新电子书一步一步指导你需要开始使用三角洲湖。增量ETL(提取、转换…
2021年8月30日 在工程数据
得到的早期预览O ' reilly的新电子书一步一步的指导你需要开始使用三角洲湖。
增量ETL(提取、转换和加载)在传统数据仓库已经变得司空见惯,美国疾病控制与预防中心(变化数据捕获)来源,但规模、成本、占机器学习的状态和缺乏访问不到理想。相比之下,增量ETL数据没有可能由于湖等因素无法更新数据并确定改变了大数据表中的数据。好了,直到现在还没有可能。增量ETL过程有很多好处,包括它是高效、简单和产生一个灵活的数据结构,数据科学家和数据分析师都可以使用。这个博客走过这些优势的增量ETL和数据架构,支持这种现代的方法。
首先让我们深入什么增量ETL。在一个较高的水平,这是源和目的地之间的运动数据,但只有当新的或更改的数据移动。穿过增量数据ETL可以几乎任何东西——网络流量事件或物联网传感器读数(附加的数据)或企业数据库的变化(CDC)的情况。增量ETL可以预定作为低延迟的工作或连续运行访问新数据,比如,对于商业智能(BI)的用例。下面的体系结构显示了如何通过多个表增量数据可以移动和变换,每一个都可以用于不同的目的。
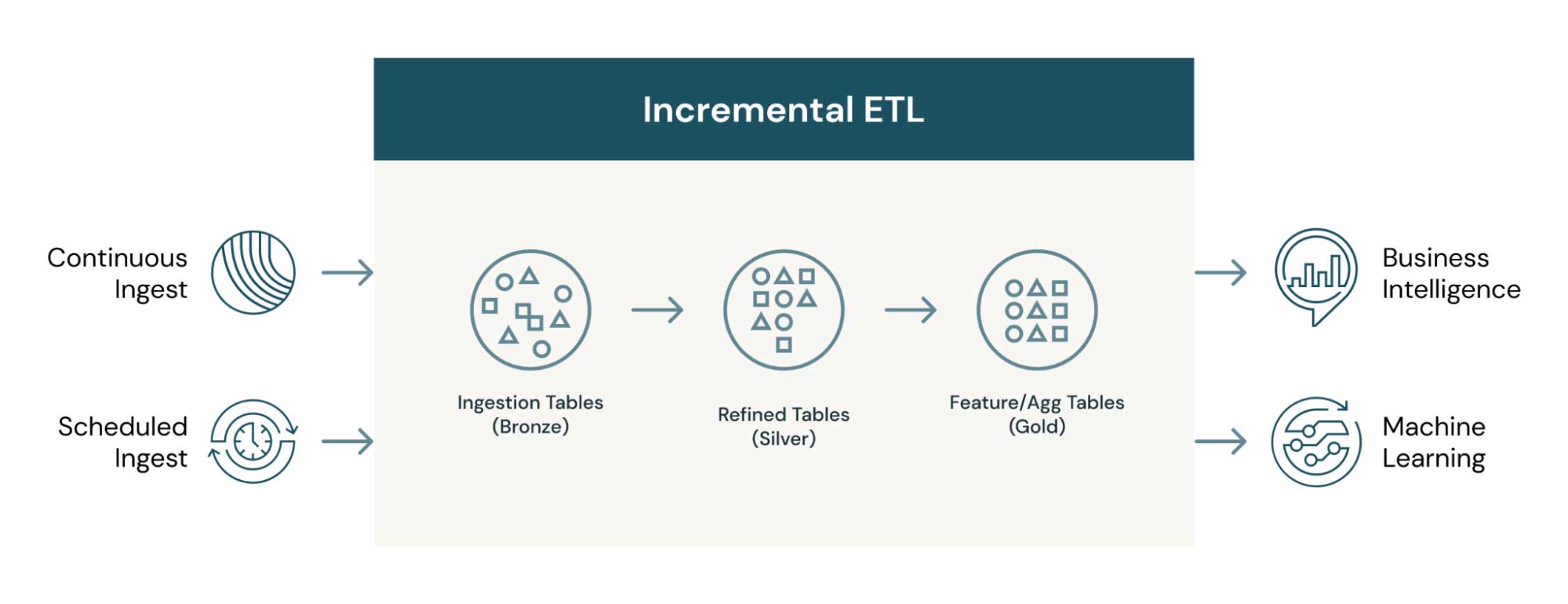
利用增量ETL。有很多原因bob下载地址开源的大数据技术,如三角洲湖和Apache引发™,让它更无缝工作规模,有成本效益的和无需担心厂商锁定。顶部采取这种方法的优点包括:
你可能会问自己这个问题。你可能熟悉架构的部分或这将如何工作在数据仓库,它可以非常昂贵。让我们来探讨一些过去的原因,这样一个架构很难完成之前探索大数据技术,使它成为可能。
我很高兴你问!许多创新的Apache火花™和三角洲湖成为可能,容易建立数据体系结构建立在增量ETL。这是有可能的技术:
既然增量ETL可能使用大数据和开放源码技术,你应该评估可以使用它在你的组织中,这样您可以构建所需的所有策划的数据bob下载地址集尽可能有效和容易!
阅读更多关于开源技术,使增量ETL,结账bob下载地址delta.io和spark.apache.org