
简化机器学习与砖Apache火花


很多数据科学家和工程师可以证明,大部分时间都花在模型本身,而是支持基础设施。关键问题包括容易想象的能力,分享,部署和安排工作。更令人不安的是数据工程师需要重新实现模型数据科学家开发的生产。砖,数据科学家和工程师可以简化这些物流问题和花更多的时间关注他们的数据问题。
简化可视化
数据科学家和工程师的一个重要观点是能够快速可视化数据和模型生成。例如,一个常见的问题在处理线性回归是确定模型的拟合优度。而统计评估,如基本均方误差,能够查看数据散点图与回归模型也同样重要。
训练模型
使用一个数据集比较人口(x)和标签数据的平均房价(y),我们可以使用火花MLlib构建一个线性回归模型与随机梯度下降法的线性回归(LinearRegressionWithSGD)。火花MLlib是Apache火花的核心组成部分,允许数据科学家和工程师快速实验,构建数据模型,并把它们生产。因为我们都在尝试SGD,我们需要尝试不同的迭代和学习速率(即α或步长)。
开始尝试这些模型的一个简单方法是创建一个砖笔记本在你选择的语言(python, scala,火花SQL),并提供上下文信息通过减价文本。下面的截图是两个细胞从一个例子DBC笔记本顶部细胞含有减记的评论而底部细胞包含pyspark代码训练两个模型。

图1:截图的砖笔记本训练两个模型与SGD进行线性回归
评估模型
一旦模型训练,与一些额外的pyspark代码,您可以快速计算这两个模型的均方误差:
valuesAndPreds = parsedData。地图(λ(p。标签,model.predict (p.features)))MSE = valuesAndPreds。(λ(p, v): (v - p) * *2).mean ()打印("均方误差= "+str(MSE))的定义模型和MSE结果在下表中。
| #的迭代 | 步长 | 均方误差 | |
| 模型 | One hundred. | 0.01 | 1.25095190484 |
| 模型B | 1500年 | 0.1 | 0.205298649734 |
虽然统计最有可能的评估表明,模型有更好的拟合优度,视觉检查数据的能力,就能很容易地验证这些结果。
可视化的模型
砖,有许多可视化选项,您可以使用与你的砖笔记本。除了默认可视化自动使用火花DataFrames时可用,您还可以使用matplotlib, ggplot, d3。js -所有嵌入相同的笔记本。
在我们的示例中,我们使用ggplot (python代码下面)所以我们不仅能提供原始数据的散点图(蓝色),而且图线的两个模型,模型是红色的和模型B是绿色的。
p = ggplot (pydf aes (“x”,“y”)+geom_point(颜色=“蓝”)+geom_line (pydf aes (“x”,“日元”),颜色=“红色”)+geom_line (pydf aes (“x”,“y3”),颜色=“绿色”)显示器(p)嵌入在房价中位数相同的笔记本ggplot轴图,散点图是标准化的人口和轴是标准化的,房价中值;模型是红色,而模型B是绿色的。
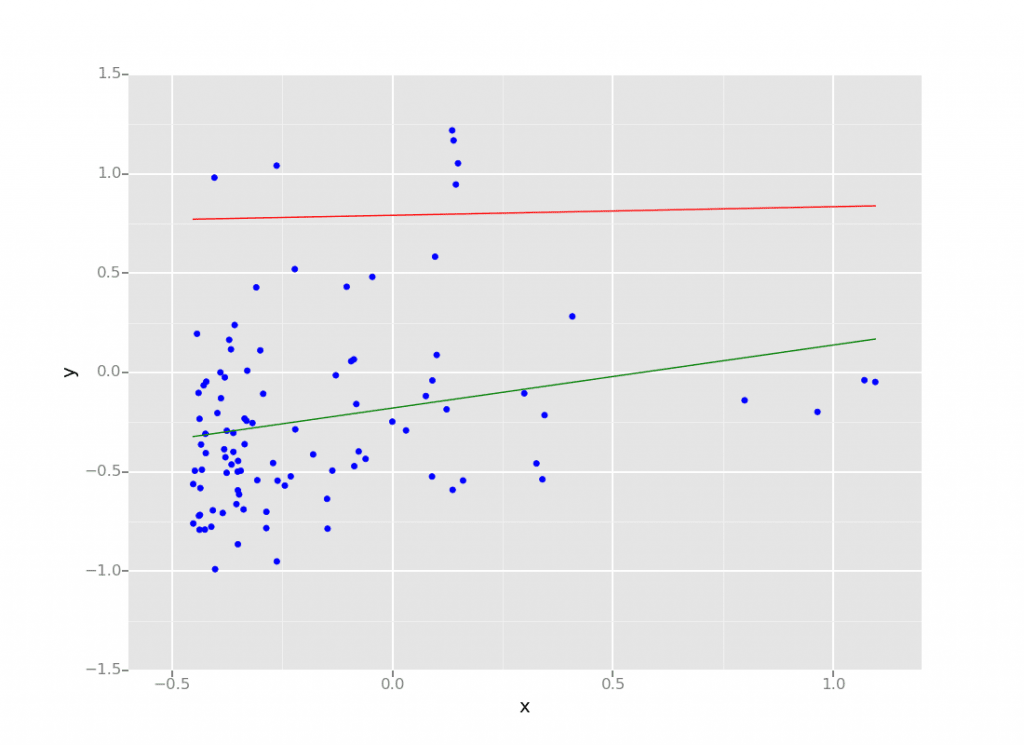
图2:截图的ggplot散点图嵌入一个砖笔记本
从上面的图可以看出,绿线(模型B)相比有更好的拟合优度红线(模型),而评估统计数据指向这个方向,能够快速可视化数据和模型在相同的笔记本允许数据科学家花更多的时间了解和优化他们的模型。
简化共享
数据科学的另一个关键方面是所需的共同努力来解决数据问题。许多开发人员、工程师、和数据科学家通常在不同的时区工作,时间表,和/或地点,重要的是要有一个环境,是为协作而设计的。
可移植性
使用砖,可以更容易与您的团队合作。你可以分享你的砖笔记本通过分享其URL,这样任何web浏览器在任何设备上都可以查看您的笔记本电脑。

图3:砖的笔记本视图相同的线性回归SGD模型通过matplotlib iPhone 6。
非专有
虽然这些笔记本是砖的优化,您可以导出这些笔记本python, scala和SQL文件,这样您就可以在您自己的环境中使用它们。这种方法的常见用例数据科学家和工程师将合作和实验数据砖,然后应用生成的代码到本地环境。
股票的定义
数据科学家或工程师使用许多不同的数据集,跟上所有的变化模式和地点本身可以是一份全职工作。帮助控制这种砖包括集中的表定义。而不是寻找包含模式的包含文件,砖中的tables选项卡,您可以定义在一个地方你所有的表。这种方式作为数据工程师更新这些表的模式或源位置,这些改变是立即可用的所有笔记本电脑。

图4:视图的表定义(模式和样本数据)从一个地方。
合作
笔记本被创建并共享,用户可以评论代码或数据,这样他们就可以提供输入笔记本没有做任何修改。这样你可以锁定笔记本以防止意外更改,仍然接受反馈。

图5:用户评论砖笔记本更容易促进反馈
简化的部署
砖的关键优势之一是模型由数据科学家可以在生产运行。这是一个巨大的优势,因为它可以减少开发周期,极大的简化了维护。相比之下,今天的数据科学家开发模型使用单独的机器工具如R或Python,然后对生产数据工程师重新实现模型。
简化基础设施
作为一个数据工程师,有很多步骤和配置在生产部署Apache火花。一些例子包括(但不限于):
- 为你配置高可用性和灾难恢复火花集群
- 建立必要的体现,自旋向上和向下集群
- 为快速检索配置引发当地利用ssd
- 或修补你的火花集群升级到最新版本的操作系统或Apache火花
砖,火花集群的管理由专门照顾砖由开发人员和工程师支持Apache火花开源项目的提交者。bob下载地址这些集群配置为最佳性能和平衡问题周围的资源调度,缓存和垃圾收集。
部署完成后,您就可以快速查看可用的集群和当前状态,包括库和笔记本连接到集群(s)。担忧高可用性、灾难恢复、体现构建和部署集群、服务管理、配置、补丁和升级都是管理代表你用你自己的(或公司)AWS帐户。

图6:你的砖砖容易管理集群视图的基础设施
简化作业调度
传统上,从代码开发过渡到生产是一项复杂的任务。它通常需要独立的人员和流程来构建代码并把它投入生产。但砖有一个强大的工作特性在生产中运行应用程序。你可以把笔记本您刚刚创建并运行它作为一个周期的工作——调度这分钟,每小时、每天、每周或每月的间隔。它也有一个智能集群配置功能,允许您现有的集群上运行你的笔记本或一个随需应变的集群。对你的工作你也可以接收电子邮件通知以及配置重试和超时。

图7:视图的人口与价格采用笔记本夜间工作
,你可以上传并执行任何火花引发JAR编译安装的工作特性。因此可以使用任何以前的工作立即重建和重建很快上手。
尝试砖
我们创建了砖方便数据科学家和工程师专注于实验和训练他们的模型,对这些模型快速部署和安排工作,容易合作和分享他们的经验,很容易地共享模式和定义的数据集。让我们管理集群、配置最优性能,进行升级和补丁,并确保高可用性和灾难恢复。
机器学习与火花MLlib更有趣当你花大部分的时间在做机器学习!