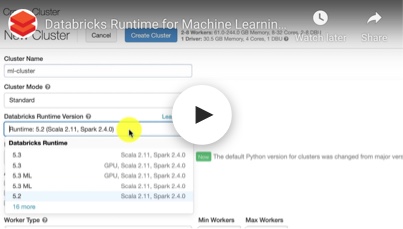
ML框架正在以疯狂的速度发展,从业者平均需要管理8个库。ML运行时提供了一键访问最流行的ML框架的可靠和性能分布,并通过预先构建的容器自定义ML环境。
데이터준비에서사전구축된AutoML을사용한추론에이르기까지머신러닝을가속화합니다。여기에는Hyperropt와MLflow를사용한하이퍼매개변수튜닝과모델이포함됩니다。
자동으로관리되는확장형클러스터인프라에서데이터크기를적은규모에서큰규모로쉽게확장할수있습니다。또한,机器学习运行时은대부분의인기있는알고리즘과HorovodRunner(분산된딥러닝을위한간단한API)에대한고유한성능개선사항도포함합니다。
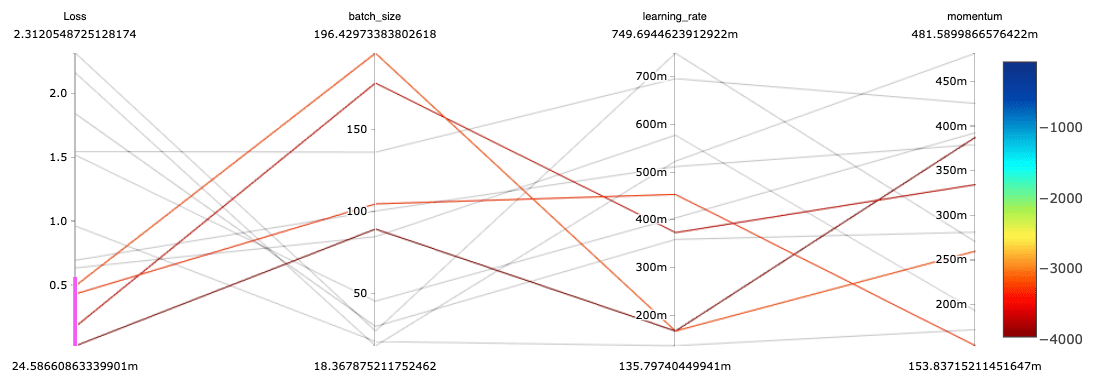
자동실험추적:오픈소스또는管理MLflow와병렬좌표플롯기능을사용하여수십만개의실험을추적,비교하고시각화합니다。
자동모델검색(단일노드ml용):향상된Hyperopt와MLflow자동추적을사용하여여러모델아키텍처에서분산및최적화된조건적하이퍼매개변수검색을제공합니다。
단일노드머신러닝에자동하이퍼매개변수튜닝적용:향상된Hyperopt와MLflow자동추적을사용하여분산및최적화된하이퍼매개변수검색을제공합니다。
분산형머신러닝에자동하이퍼매개변수튜닝적용:PySpark MLlib“의交叉验证과긴밀하게통합되어MLflow에서MLlib실험을자동추적합니다。
최적화된TensorFlow:GPU클러스터에서TensorFlow CUDA에최적화된버전을활용하여최상을성능을발휘합니다。
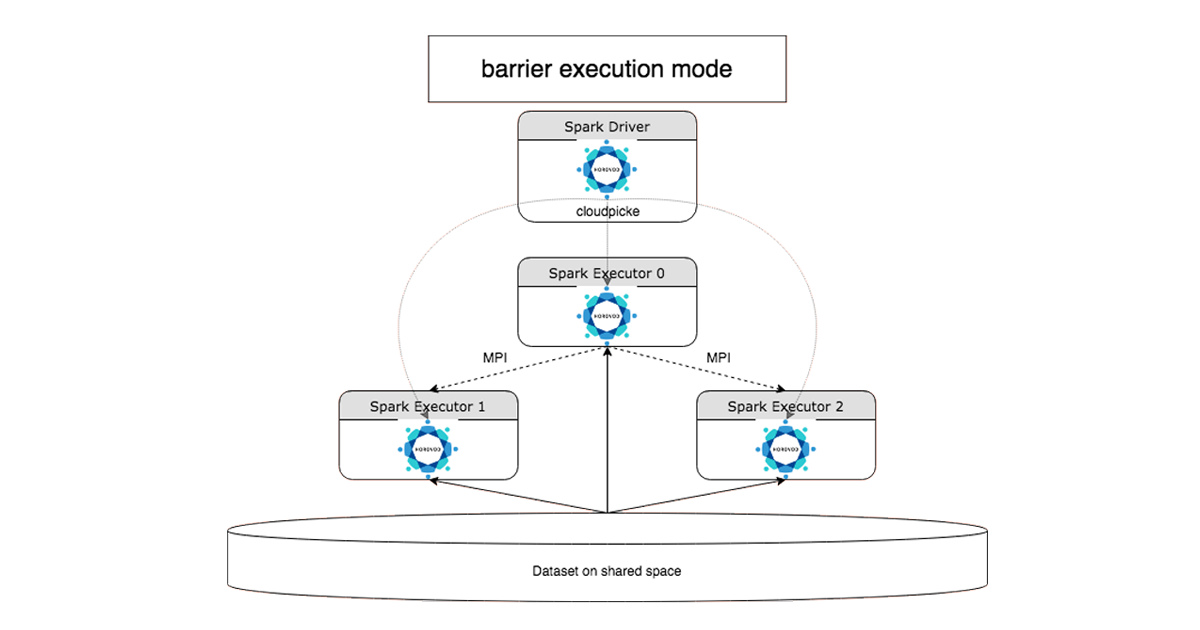
HorovodRunner:砖클러스터에서HorovodRunner (Horovod를분산형훈련에사용할경우에발생하는복잡한문제를추상화하는간단한API)를사용하여실행할수있도록단일노드딥러닝코드를신속하게마이그레이션합니다。
최적화된MLlib로지스틱회귀및트리분류기:가장많이사용하는추정도구두개가毫升용砖运行时에서최적화되어,Apache火花测试盒框대비속도가40%향상되었습니다。