什么是数据Lakehouse ?
数据lakehouse是一个新的、开放数据管理体系结构,结合了灵活性,成本效益和规模数据的湖泊数据仓库的数据管理和ACID事务,使商业智能(BI)和机器学习(ML)所有数据。
数据Lakehouse:简单、灵活性和低成本
数据lakehouses启用了一个新的、开放系统设计:实现类似的数据结构和数据管理功能在数据仓库中,直接在低成本存储用于数据的湖泊。合并在一起成一个单一的系统意味着数据团队可以移动得更快,因为他们能够使用数据,而不需要访问多个系统。数据lakehouses也确保团队拥有最完整的和最新的数据用于数据科学、机器学习和业务分析项目。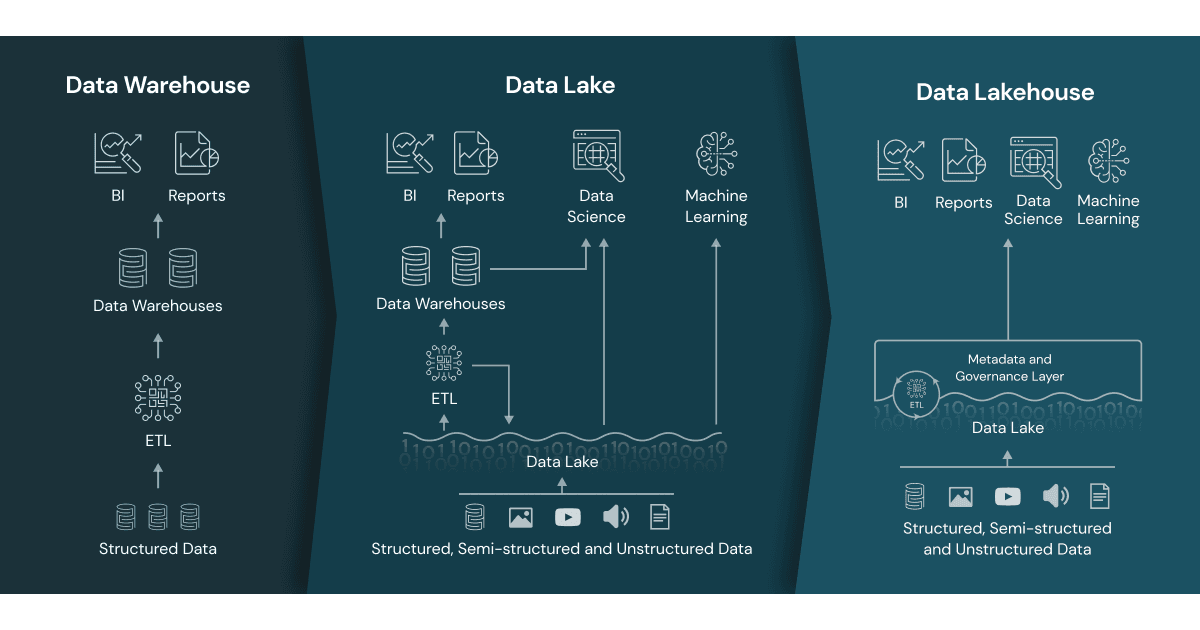
Lakehouse关键技术使数据
有一些关键的技术进步使得数据lakehouse:
- 元数据层数据湖泊
- 新的查询引擎设计提供高性能的SQL执行数据湖泊
- 优化数据访问科学和机器学习工具。
元数据层开源三角洲湖一样,坐在bob下载地址上面打开文件格式(如。镶花的文件)和跟踪哪些文件是不同的表版本的一部分,提供了丰富的管理功能,如符合acid事务将。数据lakehouses中常见的元数据层实现其他功能,如支持流式I / O(不再需要消息巴士就像卡夫卡),时间旅行旧表版本,执行模式和演化,以及数据验证。性能是关键数据lakehouses成为今天企业所使用的主要数据架构的关键原因之一,数据仓库中存在两层体系结构。而湖泊使用低成本对象存储的数据访问在过去一直很缓慢,新的查询引擎的设计使高性能SQL分析。这些优化缓存热数据包含在RAM / ssd(可能转换成更高效的格式),数据布局优化集群co-accessed数据,辅助数据结构,如统计数据和索引和矢量化现代的cpu上执行。这些技术结合在一起使得在大型数据集数据lakehouses实现性能竞争对手流行的数据仓库,根据TPC-DS基准。的lakehouses开放数据格式所使用的数据(如拼花),使它非常容易对机器学习数据科学家和工程师lakehouse访问数据。他们可以使用工具在DS /毫升生态系统和熊猫一样,TensorFlow,PyTorch和其他人拼花和兽人已经可以访问来源。火花DataFrames甚至为这些开放格式提供声明接口启用更多的I / O优化。lakehouse数据的其他特性,如审计历史和时间旅行,也帮助改进机器学习的再现性。学习更BOB低频彩多的关于技术进步支撑数据lakehouse,看到CIDR纸Lakehouse:新一代的开放式平台,统一数据仓库和先进的分析bob体育客户端下载和另一篇学术论文三角洲湖:高性能酸表存储在云存储对象。
的历史数据架构
背景数据仓库
在决策支持数据仓库有悠久的历史和商业智能应用程序,但不适合或昂贵的处理非结构化数据,半结构化数据,和数据高,速度,和体积。
出现数据的湖泊
数据然后湖泊出现来处理原始数据对廉价存储各种格式的数据科学和机器学习,尽管缺乏关键特性的数据仓库:他们不支持事务,他们不执行数据质量,及其一致性/隔离的缺乏使得它几乎不可能把附加和读取,和批处理和流媒体工作。
常见的两层数据架构
数据团队一起因此针这些系统使BI和ML跨在这两个系统的数据,导致重复数据,额外的基础设施成本、安全挑战,重要的运营成本。在两层数据架构中,数据从操作数据库为数据ETLd湖。这个湖从整个企业在低成本存储数据对象存储和存储在一个格式兼容常见的机器学习工具,但通常不是组织和维护。接下来,一小段的关键业务数据ETLd再次加载到数据仓库的商业智能和数据分析。由于多个ETL步骤,这两层架构需要定期维护和往往导致数据过时,很重要的问题的数据分析师和数据科学家都根据Kaggle和Fivetran最近的调查。BOB低频彩了解更多的常见问题与两层体系结构。