
复制任何东西:机器学习遇到数据湖屋


2021年4月26日 在工程的博客
事实证明,机器学习为组织和项目增加了前所未有的价值——无论是加速创新、个性化、需求预测还是无数其他用例。然而,机器学习(ML)利用来自无数来源的数据,以及不断变化的工具和依赖的生态系统,使得这些解决方案不断变化,难以复制。
虽然没有人能保证他们的模型是100%正确的,但具有可重复模型和结果的实验比那些不具有可重复模型和结果的实验更容易被信任。一个可重复的ML实验表明,我们至少能够重现以下内容:
- 培训/验证/测试数据
- 计算
- 环境
- 模型(以及相关的超参数等)
- 代码
然而,ML中的再现性是一项比表面上困难得多的任务。您需要访问模型训练时使用的相同的底层数据,但是如何保证数据没有更改呢?除了源代码之外,您是否对数据进行了版本控制?在此基础上,使用了哪些库(和版本)、超参数和模型?更糟糕的是,代码是否成功地运行端到端?
在这篇博客中,我们将介绍湖屋建筑是如何建造的三角洲湖加上开源库MLflow有助于解决这些复制挑战。特别地,本博客涵盖:
- Lakehouse架构
- 使用Delta Lake进行数据版本控制
- 用MLflow跟踪实验
- 与Databricks的端到端再现性
什么是数据湖屋(以及为什么你应该关心)
作为一名数据科学家,您可能不关心底层数据来自何处——CSV、关系数据库等等。但假设你正在处理每晚更新的训练数据。你今天用一组给定的超参数建立了一个模型,但是明天,你想改进这个模型并调整一些超参数。那么,模型性能的提高是因为更新的超参数还是因为底层数据的改变?如果不能对数据进行版本化和比较,就没有办法知道!您可能会说,“好吧,我只是快照我所有的数据”,但这可能非常昂贵,很快就会过时,而且很难维护和版本化。您需要一个可伸缩的数据真实来源,始终是最新的,并在不快照整个数据集的情况下提供数据版本控制。
这就是湖屋的用武之地。Lakehouses结合数据仓库和数据湖的最佳品质。现在,您可以拥有数据湖的可伸缩性和低成本存储酸数据仓库的事务性保证。这使您能够拥有数据的唯一真实来源,并且您再也不需要体验过时的、不一致的数据。它通过使用元数据管理增强现有的数据湖来实现这一点,从而优化性能,消除了将数据复制到数据仓库的需要。在保持开放标准的同时,您可以获得数据版本控制、可靠和容错事务以及快速查询引擎。现在,您可以为所有主要的数据工作负载提供单一的解决方案——从流分析到BI、数据科学和AI。这是新的标准。
这在理论上听起来很棒,但是如何开始呢?
使用Delta Lake进行数据版本控制
三角洲湖是一个开源项目,为湖屋建筑提供动力。虽然有一些开源湖屋项目,但我们更青睐Delta Lake,因为它与Apache Spark™紧密集成,并支持以下功能:
- ACID事务
- 可伸缩的元数据处理
- 时间旅行
- 模式演化
- 审计的历史
- 删除和更新
- 统一批处理和流式处理
好的ML始于高质量的数据。通过使用Delta Lake和前面提到的一些功能,您可以确保您的数据科学项目在坚实的基础上开始(明白了吗,Lake house,基础?)通过对数据的不断更改和更新,ACID事务确保在并发读写之间维护数据完整性,无论它们是批处理还是流处理。这样,每个人都对数据有一致的看法。
Delta Lake只跟踪“Delta”或自上次提交以来的更改,并将它们存储在Delta事务日志中。因此,这是可行的时间旅行基于数据版本,因此您可以在对模型、超参数等进行更改时保持数据不变。但是,使用Delta并不局限于给定的模式,因为它支持模式演化,因此可以将额外的特性作为输入添加到机器学习模型中。
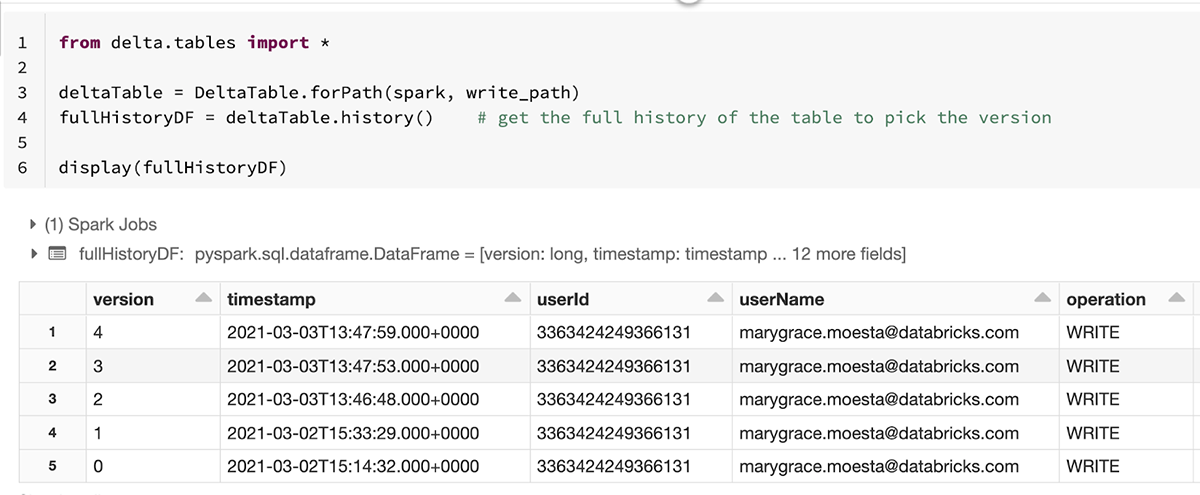
这使得跟踪底层数据的所有更改的沿袭变得很容易,确保您的模型可以使用构建它所基于的完全相同的数据重新生成。在从Delta Lake加载数据时,可以指定特定的版本或时间戳。
version =1Wine_df_delta = spark.read。格式(“δ”) .option (“versionAsOf”版).load (data_path)#版本按时间戳时间戳=2021 - 03 - 02 - t15:33:29.000 + 0000的Wine_df_delta = spark.read。格式(“δ”) .option (“timeStampAsOf”时间戳).load (data_path)使用MLflow跟踪模型
一旦能够可靠地重新生成数据,下一步就是重新生成模型。的开源库MLflow包括4个管理ML生命周期的组件,极大地简化了实验的可重复性。

MLflow跟踪允许您将超参数、度量、代码、模型和任何附加工件(例如文件、图表、数据版本等)记录到一个中心位置。这包括记录Delta表和相应的版本,以确保每次运行的数据一致性(避免实际复制或快照整个数据)。对象上构建随机森林模型的示例葡萄酒数据集,并使用MLflow记录我们的实验。整个代码可以在这个笔记本.
与mlflow.start_run ()作为运行:#日志参数n_estimators =1000max_features =“√”参数= {“data_version”: data_version,“n_estimators”: n_estimators,“max_features”: max_features}mlflow.log_params (params)#训练并记录模型rf = RandomForestRegressor(n_estimators=n_estimators,max_features = max_features,random_state =种子)射频。fit (X_train y_train)mlflow.sklearn.log_model (rf,“模型”)#日志度量度量= {“rmse”: rmse,“美”:美,r2的: r2}mlflow.log_metrics(指标)结果被记录到MLflow跟踪UI,您可以通过选择Databricks笔记本右上角的Experiment图标来访问该UI(除非您提供了不同的实验位置)。从这里开始,你可以比较运行情况,基于特定指标或参数进行筛选。

除了手动记录参数、指标等外,还有其他方法autologging功能对于一些MLflow支持的内置模型风味.例如,要自动记录sklearn模型,只需添加:mlflow.sklearn.autolog ()它将记录参数,指标,生成分类问题的混淆矩阵等estimator.fit ()被称为。
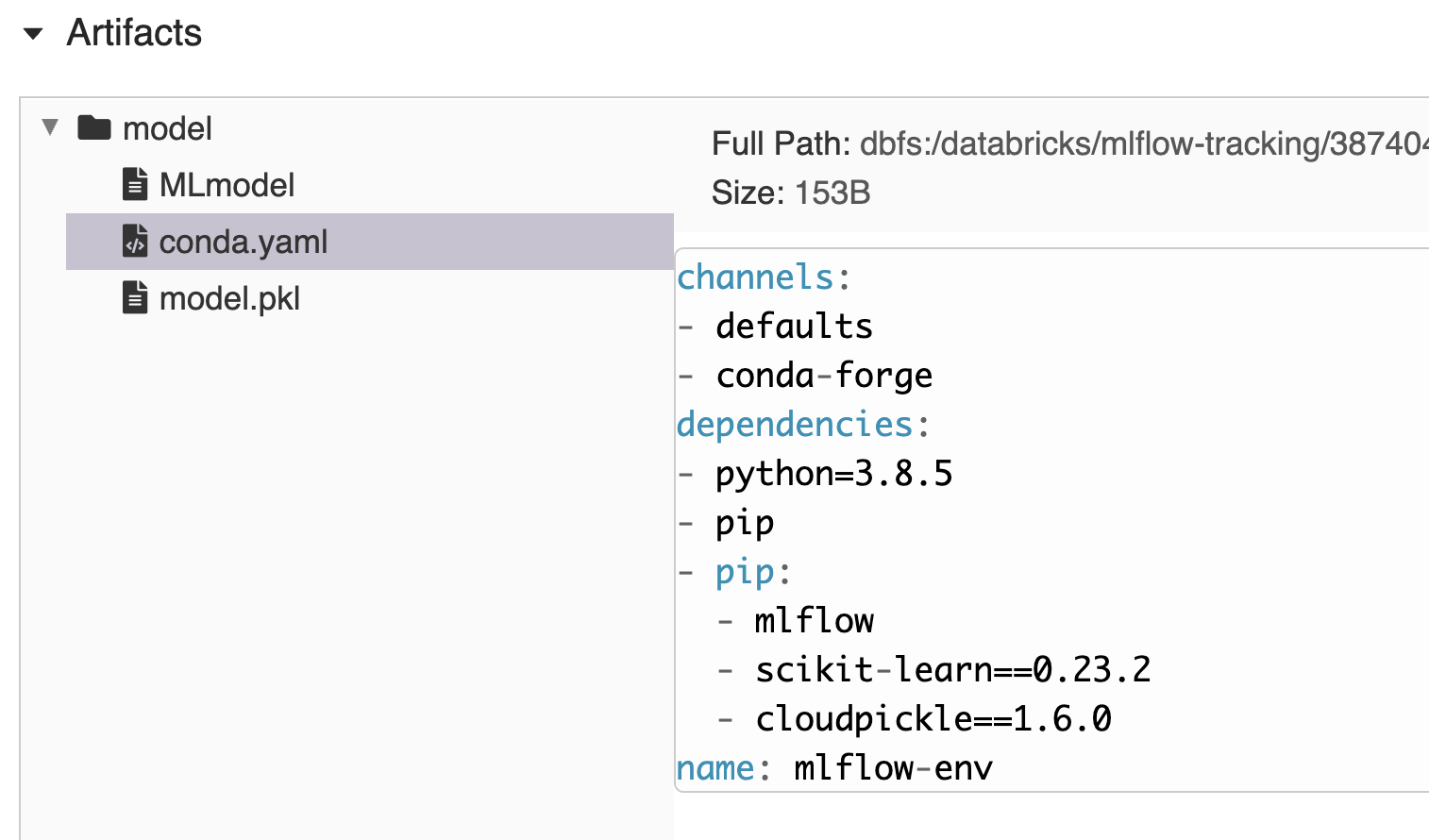
当将模型记录到跟踪服务器时,MLflow将创建一个标准模型包装格式.它会自动创建一个conda。Yaml文件,其中概述了重新创建加载模型所需的环境所需的必要通道、依赖项和版本。这意味着您可以轻松地将跟踪并记录到MLflow的任何模型的环境镜像出来。
当在Databricks平台上使用托管MLflow时,有一个bob体育客户端下载“复制运行'功能,允许您通过单击按钮来重现训练运行。它会自动对Databricks笔记本电脑、集群配置和您可能已经安装的任何附加库进行快照。
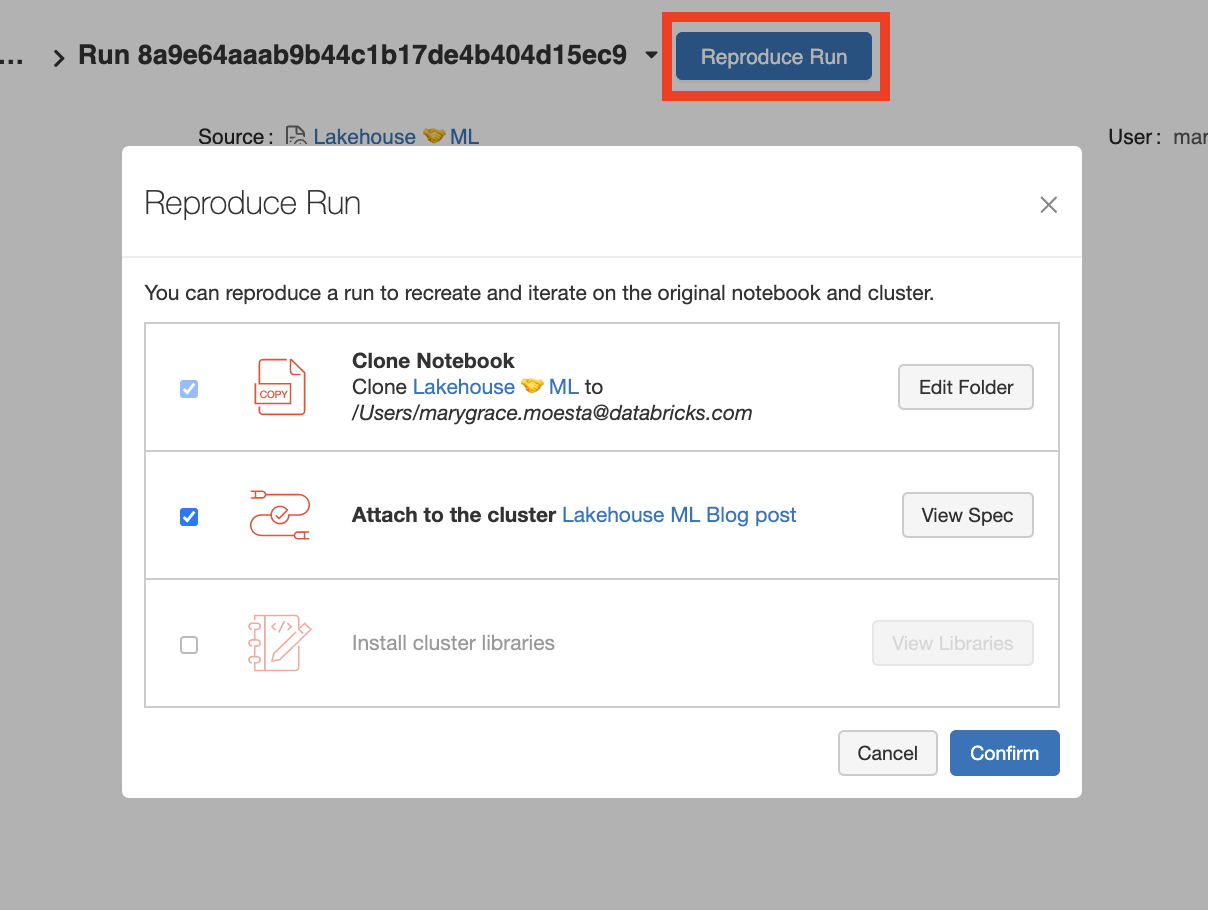
看看这个重复运行功能,看看你是否可以重复你自己的实验或你同事的实验!
把它们放在一起
现在,您已经了解了使用Delta Lake和MLflow的Lakehouse架构如何解决数据、模型、代码和环境ML再现性挑战,下面来看一看这个笔记本为你自己重现我们的实验!即使有能力重现上述项目,可能仍然有一些事情超出你的控制。无论如何,在Databricks上使用Delta Lake和MLflow构建ML解决方案解决了人们在重现ML实验时面临的绝大多数问题
有兴趣了解您可以使用数据湖屋解决哪些其他问题吗?阅读这篇最近的文章关于传统两层数据架构的挑战的博客以及湖屋建筑如何帮助企业克服这些障碍。