








改善供应链需求预测的新方法
细粒度的需求预测与因果因素
组织正在迅速拥抱细粒度的需求预测
越来越多的零售商和消费品制造商寻求改善他们的供应链管理来降低成本,释放营运资本为omnichannel创新和创建一个基金会。消费者购买行为的变化将供应链面临新的压力。发展更好的理解通过需求预测消费者需求被认为是一个好的起点对于大多数的这些努力对产品和服务的需求驱动决定劳动、库存管理、供应和生产计划,货运和物流和许多其他领域。
在人工智能前沿麦肯锡公司强调,10 - 20%改善零售供应链预测的准确性可能产生库存成本减少5%和2 3%的收入增长。传统的供应链预测工具并没有带来预期的结果。索赔的32%的行业平均水平不准确在零售商的供应链需求预测,甚至温和的潜在影响预测的改进对于大多数零售商是巨大的。因此,许多组织正在远离预包装的预测方案,探讨如何将需求预测技能内部和回顾过去的做法破坏预测精度的计算效率。
这些努力的重点是一代的预测在一个好的层面的时间和位置/产品分级粒度。精密需求预测有可能影响需求的捕获模式更接近的水平,需求必须得到满足。过去一个零售商可能预测短期需求类的产品在市场层面或分布水平,一个月或一周期间,然后用预测的值分配单位的特定产品类应放置在一个给定的存储和天,精密需求预测允许预测构建更本地化的动态模型,反映了特定的产品在一个特定的位置。
精密需求预测带来的挑战
如精密需求预测听起来令人兴奋,也有许多挑战。首先,通过远离总预测,预测模型和预测的数量必须产生爆炸。所需的加工水平由现有的预测工具要么是高不可攀,也大大超过服务窗口的这些信息是有用的。这种限制会导致企业的数量上做出权衡类别正在处理,或谷物的水平分析。
在之前的检查博客,Apache火花可以用来克服这一挑战,允许模型并行化工作及时、高效的执行。砖等原生云平台上部署时,可以快速分配计算资源,然后释放,使这bob体育客户端下载项工作的成本在预算之内。
第二和更加困难克服面临的挑战是理解,需求模式中存在的总检查数据时可能不会出现在更细的粒度层次上。套用亚里士多德,整个往往会大于各部分的总和。当我们搬到较低层次的细节在我们的分析中,模式更容易建模在更高级别的粒度可能不再可靠,使生成的预测技术适用的上级更具挑战性。这个问题的上下文中预测指出,许多从业者一路回亨利·赛尔在1950年代。
当我们接近事务的粒度级别,我们还需要考虑外部因果因素影响个人客户需求和购买决策。总的来说,这些可能是反映在平均水平,发展趋势和季节性时间序列,但在细粒度的水平,我们可能需要将这些直接进入我们的预测模型。
最后,搬到更细的粒度层次上增加了我们的数据结构的可能性将不允许使用传统的预测技术。移动事务粮食越近,我们越高可能性,我们将需要解决时间的不活动在我们的数据。在这个级别的粒度,我们的因变量,尤其是在处理计数销量等数据,可能需要在偏态分布,不服从简单的转换,可能需要使用预测技术在许多数据科学家的舒适区。
访问历史数据
为了检验这些挑战,我们将利用公共访问历史数据从纽约自行车共享计划,也被称为花旗自行车纽约。花旗自行车纽约公司承诺帮助人们,“解锁一辆自行车。纽约解锁。“服务允许人们去任何超过850个不同的整个纽约地区和租自行车租赁位置。公司拥有超过13000的库存自行车计划增加到40000。花旗自行车超过100000用户每天近14000人骑。
花旗自行车纽约是重新分配自行车从他们离开,他们预测未来的需求。花旗自行车纽约市有一个挑战,是类似于零售商和消费品企业处理日常。我们如何最好的预测需求分配资源的地区吗?如果我们低估了需求,我们小姐收入机会和潜在的伤害客户的情绪。如果我们高估了需求,我们有多余的库存自行车被闲置。
这个公开的数据集提供了信息在每个月底之前所有的自行车出租回到程序的《盗梦空间》在2013年年中。自行车旅行历史数据确定确切的时间是从特定的出租车站和租自行车的时间返回到另一个出租车站。如果我们把站在纽约花旗的自行车项目是商店的起始位置和考虑租赁交易,我们有一些密切近似一个漫长而详细的交易历史我们可以生产预测。
作为这个练习的一部分,我们需要识别外部因素纳入我们的建模工作。我们将利用假期事件以及历史和预测天气数据外部影响力。为假期数据集,我们只会确定标准假期从2013年至今使用假期图书馆在Python中。天气数据,我们将采用计时提取物视觉交叉,一个受欢迎的天气数据聚合器。
花旗自行车纽约和视觉交叉数据集的条款和条件,禁止直接共享他们的数据。那些希望重建我们的结果应该访问数据提供者的网站,审查他们的条款和条件,和下载他们的数据集环境在一个适当的方式。我们将提供所需的数据准备逻辑将这些原始数据资产转换为我们分析中使用的数据对象。
检查事务数据
截至2020年1月,纽约花旗自行车自行车分享项目包括864活跃站操作在纽约市区,主要在曼哈顿。仅在2019年,超过400万的租金是由客户提供多达近14000租金在高峰期,发生。
程序的开始以来,我们可以看到出租的数量增加了。一些这种增长可能是由于增加自行车的使用,但这似乎是与整个站网络的扩张。
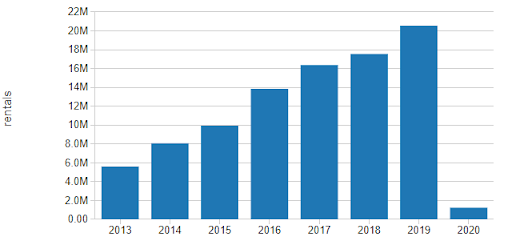
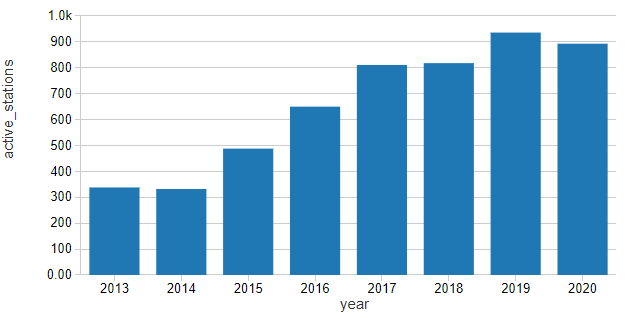
规范租赁网络中的活跃站的数量表明,客流量增长per-station基础上慢慢流逝了在过去的几年里我们可以考虑稍微线性上升趋势。
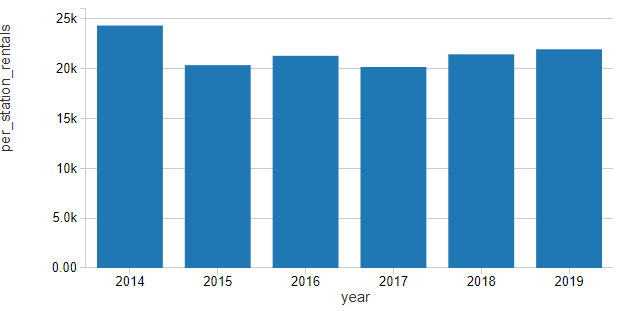
使用这个租金归一化值,客流量似乎遵循一个明显的季节性模式,在春天,夏天和秋天,然后把冬天外面的天气变得不那么有利于骑自行车
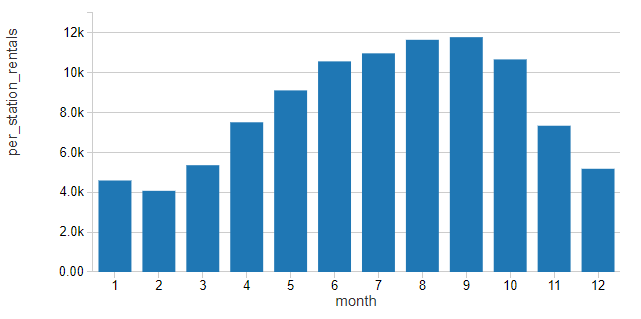
他的模式似乎密切跟踪模式的最大温度(华氏度)的城市。

虽然很难单独月客流量从模式温度,降雨量(平均每月英寸)镜像这些模式不那么容易
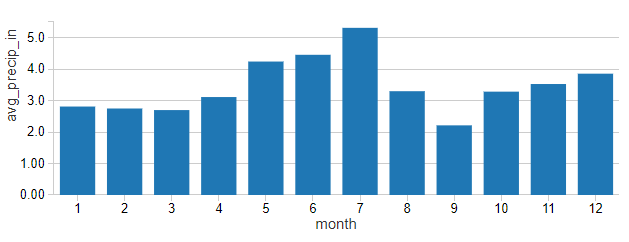
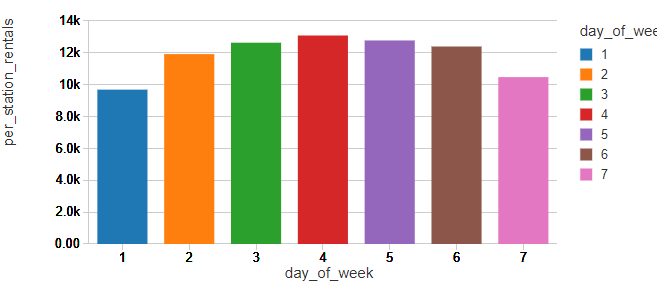
检查每周的周六和周日客流量确定为1和模式识别为7,看起来纽约人使用自行车通勤设备,一个模式在许多其他的自行车共享项目。
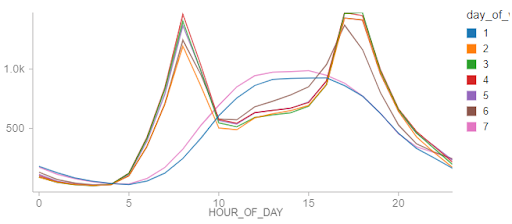
分解这些客流量模式的小时的一天,我们看到不同的工作日模式,在标准的通勤时间客流量峰值。在周末,模式表明更悠闲的利用程序,支持我们的假说。
一个有趣的假期模式,不管他们的天的星期,显示消费模式,大致模拟周末使用模式。假期可能会造成的偶然发生erraticism这些趋势。不过,似乎支持的图表,确定假期产生一个可靠的预测是很重要的。
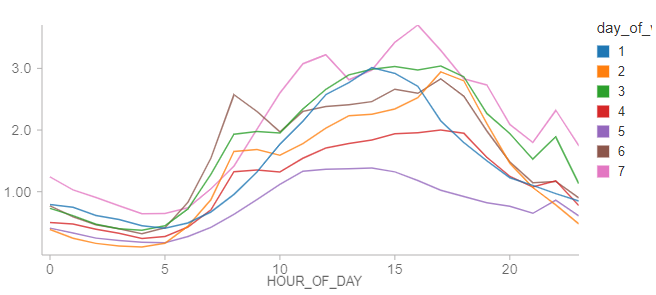
总的来说,每小时的数据似乎表明,纽约真的是不夜城。在现实中,有许多站,有一大部分的时间在此期间不租自行车。
这些差距在活动时可以有问题试图产生一个预测。从小时到4小时间隔,在个人站经验没有句点的数量租赁活动大幅下降虽然仍有许多电台不活跃在这个时间段。
而不是逃避问题的不活跃的时期甚至迈向更高层次的粒度,我们将尝试让每小时的预测水平,探索另一种预测方法可以帮助我们如何处理这个数据集。作为预报站,在很大程度上是不活跃的并不十分有趣,我们会限制我们的分析前200名最活跃的电台。
预测自行车共享租赁与Facebook的先知
在最初试图预测自行车出租在per-station层面,我们利用Facebook的先知流行的Python库,时间序列预测。模型配置与日常探索一个线性增长模式,每周和每年的季节性模式。时期与节日相关的数据集也发现这样反常行为在这些日期不会影响平均趋势和季节性模式检测算法。
使用扩展模式记录在前面引用的博文,模型训练最活跃的200个车站和36小时为每个生成的预测。总的来说,模型的均方误差(RMSE) 5.44平均平均相对误差(日军)为0.73。(新鲜感实绩调整为日军1计算。)
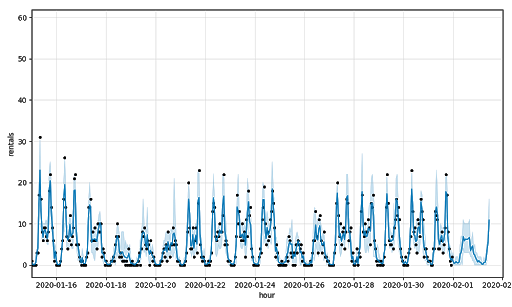
这些指标表明预测模型做一个相当不错的租金,但失踪时每小时租赁利率走高。可视化为个人站销售数据中,您可以看到这个图形在这个图表等站518年E 39圣& 2大街,有4.58和0.69的日军的RMSE:
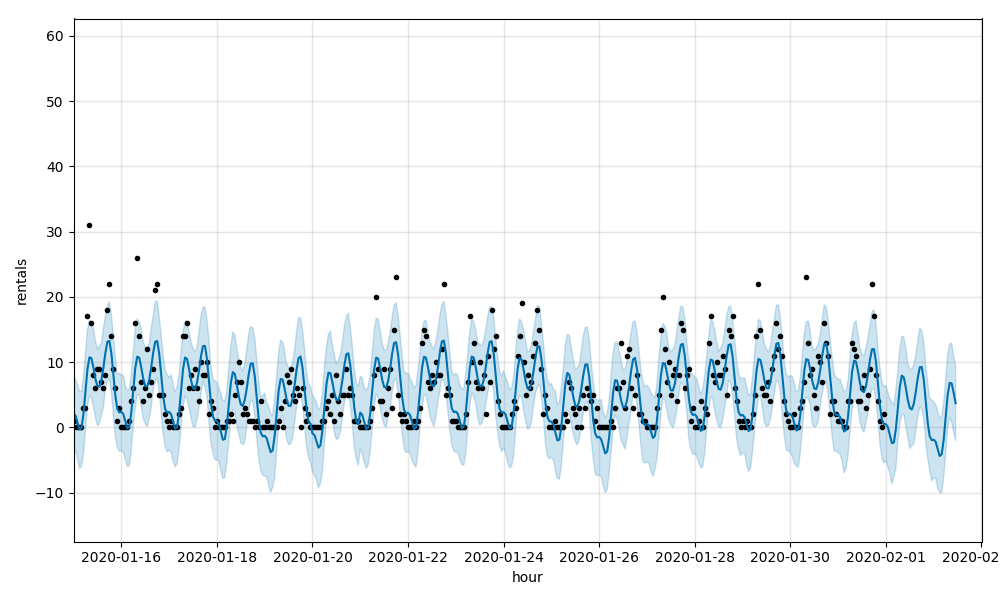
然后模型调整将温度和降水作为解释变量。集体,结果预测的RMSE 5.35和0.72的日军。非常轻微的改善时,模型仍难以收拾的大幅波动在车站客流量发现水平,再次证明站518的4.51和0.68的日军的RMSE:
这种模式的建模难度更高的值在两个时间序列模型典型的有一个处理数据泊松分布。在这种分布,我们将有大量的值在平均的长尾价值上面。在另一边的平均,零离开数据倾斜的地板上。今天,Facebook先知预计数据正态(高斯)分布但计划讨论了合并的泊松回归。
替代的方法来预测供应链的需求
然后我们会如何进行生成预测这些数据呢?一个解决方案,因为Facebook的看护人先知正在考虑,是利用泊松回归功能的背景下,传统的时间序列模型。虽然这可能是一个很好的方法,它不是广泛记录所以解决这个我们自己再考虑其他技术为我们的需求可能不是最好的方法。
另一个潜在的解决方案是模型的规模非零值和频率发生的新鲜感。每个模型的输出可以组装预测相结合。被称为Croston的方法,这个方法是最近发布的支持croston Python库而另一个数据科学家实现了自己的函数为它。不过,这并不是一种广泛采用的方法(尽管技术可以追溯到1970年代)和我们的偏好是探索更多的东西开箱即用的。
鉴于这种偏好,随机森林回归量似乎相当多的意义。决策树,在一般情况下,不施加相同的限制数据分布统计方法。预测变量的值的范围,这样它可能意义将租赁使用类似一个平方根变换之前训练模型,但即使这样,我们可能会看到算法的执行没有它。
利用这个模型,我们需要工程师几个特性。很明显的探索性分析,有很强的季节性模式的数据,这两个年度,每日和每周的水平。这使我们提取年、月、日的周和小时的特性。我们可能还包括一个标志来度假。
只使用一个随机森林回归量和time-derived特性,我们到达一个总体RMSE 3.4和0.39日军。站518日军和RMSE值是3.09和0.38,分别为:
通过利用降水和温度数据结合这些相同的时间特性,我们能够更好的(但不完全)地址的租赁价值就越高。RMSE站518下降到2.14和0.26的日军。总的来说,RMSE下降到2.37,日军0.26表明天气数据是有价值的预测对自行车的需求。
影响的结果
需求预测在细的粒度级别可能需要我们不同的思考方法建模。外部影响可能是安全考虑总结在高层时间序列模式可能需要更明确纳入我们的模型。隐藏在数据分布模式总体层面可能会变得更容易暴露需要变化的建模方法。在这个数据集,这些挑战是最好解决的每小时天气数据和远离传统的时间序列技术转向一个算法使得更少的假设我们的输入数据。
可能有许多其他外部影响力和算法值得探索,当我们沿着这条路,我们可能会发现,这些工作为某个子集的数据比别人。我们也可能发现新的数据到达时,技术,之前可能需要放弃工作和新技术。
我们看到一个共同的模式与客户探讨精密需求预测是多种技术的评估与每个训练和预测周期,我们可能描述为一个自动化模型烘烤大赛。在烘烤大赛轮,模型产生最好的结果对于一个给定的数据子集的赢得了一轮与每个子集能够决定自己的模型类型。最后,我们希望确保我们表现好的数据科学数据是否正确设置与我们使用的算法,但在一篇又一篇的文章指出,并不总是一个问题只有一个解决方案和一些可能一次比他人更好地合作。我们今天仍在使用的平台的力量像Apache火花和砖是我们获得计算能力探索这些路径和提供最好的解bob体育客户端下载决方案,我们的业务。
额外的零售/ CPG和需求预测资源
- 注册一个免费试用和下载这些笔记本开始试验:
- 下载我们的指导数据分析和艾城的零售和CPG的规模
- 访问我们的零售和CPG页面学习美元刮胡子samwers俱乐部和Zalando与砖创新
- 阅读我们的最近的博客细粒度的时间序列预测规模与Facebook先知和Apache火花学习如何砖统一数据分析平台bob体育客户端下载及时解决挑战,粒度级别,允许业务进行精确调整产品库存
免费试着砖
相关的帖子