配置集群
请注意
这些都说明遗留集群创建UI,并且只包括历史准确性。所有客户都应该使用创建集群UI更新。
本文解释了可用的配置选项,当你创建和编辑数据砖集群。它着重于创建和编辑集群使用UI。其他方法,请参阅砖CLI,集群API,砖起程拓殖的提供者。
帮助决定哪些配置选项的组合最适合您的需要,明白了集群配置的最佳实践。
集群政策
一个集群政策限制的能力配置集群基于一组规则。策略规则限制可用的属性或属性值创建集群。集群政策acl,限制他们使用特定的用户和组,从而限制政策,您可以选择当您创建一个集群。
配置一个集群政策,选择的集群政策政策下拉。
请注意
如果没有政策在工作区中创建,政策下拉不显示。
如果你有:
集群创建权限,你可以选择不受限制的政策和创建完全可配置集群。的不受限制的集群政策不限制任何属性或属性值。
两个集群创建权限和访问集群政策,你可以选择不受限制的你可以访问政策和政策。
访问集群政策,您可以选择您使用的政策。
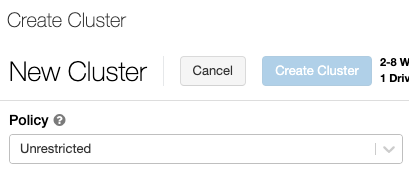
集群模式
请注意
本文描述了传统集群UI。信息关于新集群的UI(预览),看到的创建一个集群。这包括一些术语集群访问类型和模式的变化。比较新和遗留的集群类型,明白了集群UI变化和集群访问模式。在预览界面:
标准模式集群现在被称为任何隔离共享访问模式集群。
高并发性和表acl现在被称为共享访问模式集群。
砖集群支持三种模式:标准,高并发,单独的节点。默认的集群模式是标准。
重要的
如果你的工作空间是分配给一个统一目录metastore、高并发性集群并不可用。相反,你使用访问模式确保访问控制和实施强有力的隔离的完整性保证。另请参阅创建一个集群,可以访问统一目录。
你不能改变后的集群模式创建一个集群。如果你想要一个不同的集群模式,您必须创建一个新的集群。
包括一个集群配置自动终止设置的默认值取决于集群模式:
标准和单节点集群默认120分钟后自动终止。
高并发的集群不默认情况下自动终止。
标准的集群
警告
标准模式集群(有时称为任何隔离共享集群)可以由多个用户共享,与用户之间没有隔离。如果你使用High Concurrency集群模式没有额外的安全设置如表acl或凭据透传,使用了相同的设置标准模式集群。账户管理员可以防止内部凭证自动生成砖工作空间的管理员在这些类型的集群。为更安全的选择,砖建议替代的高并发性等集群表acl。
一个标准的集群仅为单一用户推荐。标准Python开发的集群可以运行工作负载,SQL, R, Scala。
高并发的集群
高并发集群是一个云资源管理。高并发性集群的主要好处是,他们提供细粒度共享最大的资源利用率和最小查询延迟。
高并发运行工作负载集群开发的SQL, Python,和r .高并发的性能和安全集群是由在单独的进程中运行用户代码,在Scala中这是不可能的。
此外,只有高并发的集群支持访问控制表。
创建一个高并发集群,集集群模式来高并发。
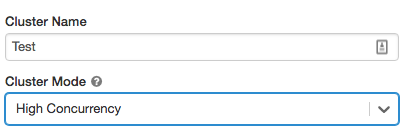
单节点集群
单个节点集群没有工人和司机节点上运行引发工作。
相比之下,一个标准的集群需要至少有一个引发工人节点除了司机节点执行引发的工作。
创建一个单独的节点集群,集集群模式来单独的节点。
了解更BOB低频彩多关于使用单节点集群,明白了单节点集群。
池
减少集群开始时间,您可以附加一个预定义的集群池闲置的情况下,司机和工人的节点。创建集群使用实例池。如果池中没有足够的空闲资源创建请求司机或工作节点,池扩大供应商分配新实例的实例。连接终止集群时,它使用实例返回到池和由不同的集群可以重用。
如果你选择了一个池为职工节点而不是司机节点,司机从工人节点节点继承池配置。
重要的
如果你试图选择一个池司机节点而不是工人节点,出现错误,您的集群不是创建。这个需求可以防止情况司机节点等待工人创建节点,反之亦然。
看到创建一个池了解更BOB低频彩多关于工作在砖池。
砖运行时
砖的设置是运行时上运行的核心组件集群。所有砖运行时包含Apache火花和添加组件和更新,提高可用性,性能和安全。有关详细信息,请参见砖运行时。
砖提供了几种类型的运行时和几个版本的运行时类型砖的运行时版本的拉当您创建或编辑一个集群。
光子加速
光子用于集群运行吗砖运行时9.1 LTS及以上。
使光子加速,选择使用光子加速复选框。
如果需要,您可以指定实例类型的工人的类型和驱动程序类型下拉。
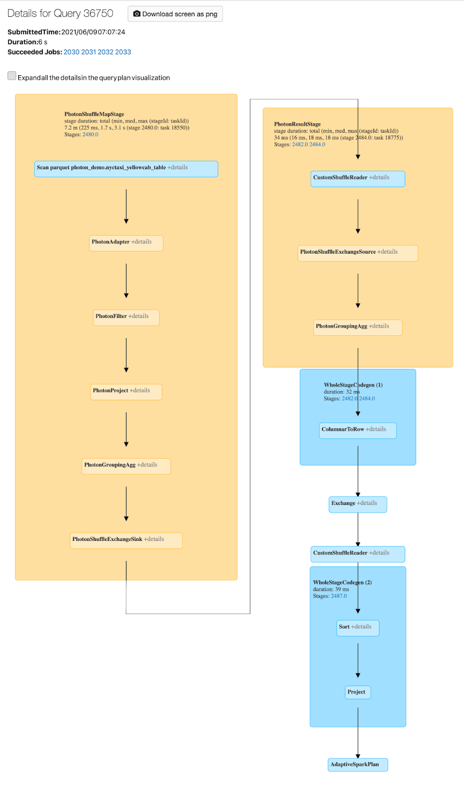
你可以把光子的活动火花UI。下面的屏幕截图显示了查询细节DAG。有两个光子在DAG的迹象。首先,光子运营商开始“光子”,例如,PhotonGroupingAgg。第二,在DAG光子运营商和阶段是彩色的桃子,而non-Photon的是蓝色的。
码头工人的图片
对于一些砖运行时版本,您可以指定一个码头工人形象当您创建一个集群。示例用例包括库定制,不会改变黄金容器环境,码头工人CI / CD集成。
您还可以使用码头工人图像来创建自定义集群GPU设备上深刻的学习环境。
说明,请参阅自定义容器砖容器服务和在GPU集群砖容器服务。
集群节点类型
一个集群由一个驱动节点和零个或多个工作节点。
你可以选择单独的云提供商为司机和工人节点实例类型,尽管默认情况下司机节点使用相同的实例类型工作节点。不同家庭的实例类型适合不同的用例,如内存密集型或计算密集型工作负载。
司机节点
司机节点维护状态信息的笔记本电脑连接到集群。司机节点还维护SparkContext并解释所有的命令你在集群上运行从一个笔记本和一个图书馆,并运行Apache主坐标的火花引发执行人。
司机节点类型的默认值是一样的工人节点类型。你可以选择一个更大的驱动节点类型和更多的内存,如果你正计划收集()大量的数据从引发工人和分析他们在笔记本上。
提示
因为司机节点维护的所有状态信息的笔记本电脑,确保分离未使用的笔记本从司机节点。
工作者节点
砖工人节点运行所需的火花执行者和其他服务正常运行的集群。当你分发工作负载与火花,所有的分布式处理发生在工作节点。砖运行一个人均执行器节点;因此条款遗嘱执行人和工人是交替使用的砖结构。
提示
火花运行工作,你至少需要一个工作节点。如果集群的工人为零,你可以运行non-Spark命令司机节点上,但火花命令将失败。
请注意
砖发射的工人每个节点有两个私有IP地址。节点的主要私人IP地址用于主机砖内部交通。二次使用的私有IP地址是火花容器实现网内集群通信。这个模型允许砖提供多个集群之间的隔离在同一个工作区。
GPU实例类型
对于需求的高性能的计算有挑战性的任务,像那些与深度学习,砖支持集群加速的图形处理单元(gpu)。有关更多信息,请参见GPU-enabled集群。
AWS引力子实例类型
砖支持集群AWS引力子处理器。基于arm的AWS引力子实例设计的AWS提供更好的价格性能比较当代基于x86的实例。看到AWS Graviton-enabled集群。
集群规模和自动定量
当你创建一个砖集群,可以为集群提供一个固定数量的工人或提供的最小和最大数量的工人集群。
当你提供固定大小的集群,砖确保集群有指定数量的工人。当你为工人的数量,提供一系列砖选择适当数量的工人需要运行你的工作。这被称为自动定量。
与自动定量、动态砖是重新分配人员占你的工作的特点。某些部位的管道可能比其他人更计算要求,和砖自动添加额外的工人在这阶段的工作(并删除他们当他们不再需要)。
自动定量使它更容易实现集群利用率高,因为你不需要提供集群匹配工作负载。这尤其适用于负载的需求随时间变化(如每天探索过程中数据集),但它也能适用于一次性短工作负载的配置需求是未知的。自动定量因此提供了两个优点:
工作负载可以运行得更快而constant-sized under-provisioned集群。
自动定量集群静态大小的集群相比可以降低整体成本。
根据集群的常数大小和工作负载,自动定量给你其中的一个或两个同时受益。集群规模可以低于最小数量的工人时选择的云提供商终止实例。在这种情况下,砖不断重试重新供应实例为了维持最低的工人数量。
请注意
自动定量是不可用的spark-submit就业机会。
如何自动定量的行为
尺度从最小到最大2步骤。
即使可以缩小规模集群不空闲看洗牌文件状态。
基于当前节点的比例尺度。
工作群,尺度下如果集群充分利用过去40秒。
通用的集群,尺度下如果集群充分利用过去150秒。
的
spark.databricks.aggressiveWindowDownS火花在几秒钟内配置属性指定集群频率使缩小规模的决定。持续增加的值会导致一个集群规模更慢。最大值是600。


本地磁盘加密
预览
这个特性是在公共预览。
一些实例类型用于在本地运行集群可能附加的磁盘。砖可能洗牌数据或临时数据存储在这些本地连接的磁盘。确保所有的数据是加密的存储类型,包括改组数据暂时存储在集群的本地磁盘,您可以启用本地磁盘加密。
重要的
你的工作负载可能会更慢,因为阅读和写作加密数据对性能的影响,从本地卷。
当启用本地磁盘加密时,砖在本地生成一个加密密钥,是独一无二的每个集群节点,用于加密所有数据存储在本地磁盘。关键是当地的范围到每个集群节点集群节点本身和被摧毁。在其一生中,加密和解密的关键驻留在内存和存储加密的磁盘上的。
启用本地磁盘加密,你必须使用集群API。在集群创建或编辑设置:
{“enable_local_disk_encryption”:真正的}
看到集群API如何调用这些api的例子。
下面是一个示例集群的创建,使本地磁盘加密:
{“cluster_name”:“my-cluster”,“spark_version”:“7.3.x-scala2.12”,“node_type_id”:“r3.xlarge”,“enable_local_disk_encryption”:真正的,“spark_conf”:{“spark.speculation”:真正的},“num_workers”:25}
安全模式
如果你的工作空间是分配给一个统一目录metastore,你用安全模式代替高并发集群模式确保访问控制和实施强有力的隔离的完整性保证。高并发集群模式和统一目录不可用。
下高级选项,选择从以下集群安全模式:
没有一个:没有隔离。不执行workspace-local表访问控制或凭据透传。不能访问统一目录数据。
单用户:只有一个用户可以使用(默认情况下,用户创建的集群)。其他用户无法连接到集群。当访问一个视图从一个集群单用户安全模式,视图和用户的权限执行。单用户集群支持工作负载使用Python, Scala, r . Init脚本库安装和DBFS坐骑在单用户支持集群。自动化工作应该使用单用户集群。
用户隔离:可以由多个用户共享。只支持SQL工作负载。图书馆安装,init脚本和DBFS坐骑被禁用执行严格的隔离在集群用户。
表只ACL(遗留):执行workspace-local表访问控制,但不能访问统一编目数据。
只透传(遗留):执行workspace-local凭据透传,但不能访问统一编目数据。
唯一的安全模式支持统一编目工作负载单用户和用户隔离。
有关更多信息,请参见集群访问模式是什么?。
AWS的配置
当您配置一个集群的AWS实例可以选择可用性区域,马克斯现货价格,EBS卷类型和大小,和实例配置文件。指定配置,
在集群配置页面,单击高级选项切换。
在页面的底部,单击实例选项卡。

可用性区域
此设置允许您指定的可用性区域(AZ)你想要使用集群。默认情况下,这个设置是设置为汽车(Auto-AZ), AZ自动选择是基于在工作区中可用的ip子网。Auto-AZ重试其他可用性区域如果AWS返回错误能力不足。
选择一个特定AZ集群主要是有用的,如果您的组织购买了保留实例在特定的可用性区域。阅读更多关于AWS可用性区域。
现货实例
您可以指定是否使用现货实例和马克斯现货价格时使用启动实例的比例相应的随需应变的现货价格。默认情况下,马克斯价格是随需应变的100%价格。看到AWS现货价格。
EBS卷
本节描述默认EBS卷设置工人节点,如何添加洗牌卷,以及如何配置一个集群这砖自动分配EBS卷。
配置EBS卷,单击实例在集群配置选项卡,并选择一个选项EBS卷类型下拉列表。
默认EBS卷
砖规定EBS卷为每个职工节点如下:
根卷30 GB加密EBS实例使用的主机操作系统和砖内部服务。
一个150 GB的加密EBS容器所使用的根卷引发工人。这个主机火花服务日志。
(HIPAA) 75 GB加密EBS工人日志卷存储日志数据砖内部服务。
添加改组EBS卷
添加洗牌卷,选择通用SSD在EBS卷类型下拉列表:
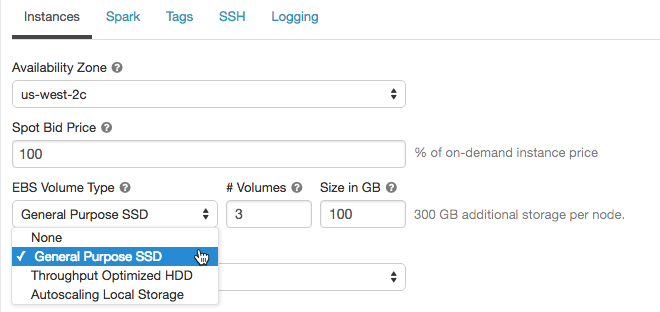
默认情况下,火花洗牌输出到本地磁盘。例如类型没有本地磁盘,或者如果你想增加你的火花洗牌存储空间,您可以指定额外的EBS卷。这是特别有用的防止磁盘空间的错误当您运行火花产生大洗牌的工作输出。
砖加密这些EBS卷的随需应变和现货实例。阅读更多关于AWS EBS卷。
AWS EBS限制
确保你的AWS EBS限制高到足以满足运行时要求所有工人在所有集群。对于信息默认EBS限制以及如何改变它们,看到的亚马逊弹性块存储(EBS)的限制。
AWS EBS SSD卷类型
你可以选择gp2或gp3 AWS EBS SSD卷类型。要做到这一点,看到的管理SSD存储。砖建议您切换到gp3 gp2相比,节省成本。技术信息gp2 gp3、明白了亚马逊EBS卷类型。
自动定量本地存储
如果你不想分配一个固定数量的EBS卷在创建集群时,使用自动定量本地存储。自动定量本地存储,数据砖监视器上可用的空闲磁盘空间集群的火花的工人。如果一个工人开始在磁盘上运行过低,砖自动高度新EBS卷的工人之前耗尽磁盘空间。EBS卷附加到一个极限5 TB的总磁盘空间的每个实例(包括实例的本地存储)。
配置自动定量储存、选择启用自动定量本地存储在自动驾驶仪选项框:

EBS卷附加到一个实例只分离时返回给AWS实例。EBS卷,永远不会脱离只要是一个实例运行集群的一部分。缩减EBS用法,砖建议使用这个特性在集群配置集群规模和自动定量或意外终止。
请注意
砖使用吞吐量的优化硬盘(死神)来扩展一个实例的本地存储。的默认AWS容量限制这些数量是20 TiB。为了避免触及这个极限,管理员应该请求增加这个极限根据自己的使用需求。
请注意
如果你创建你的砖账户之前版本2.44(2017年4月27日之前)和想使用自动定量本地存储(默认启用高并发的集群),您必须添加体积权限我角色或键用于创建您的帐户。特别是,您必须添加权限ec2: AttachVolume,ec2: CreateVolume,ec2: DeleteVolume,ec2: DescribeVolumes。完整列表的权限和说明如何更新您的现有我角色或钥匙,明白了为工作区部署创建了我的角色。
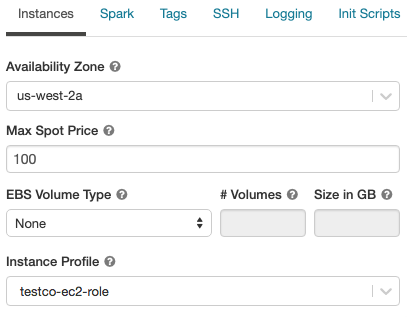
实例配置文件
安全地访问AWS资源没有使用AWS键,您可以启动砖集群实例的配置文件。看到S3访问配置实例配置文件关于如何创建和配置实例配置的信息。一旦您创建了一个实例,您选择的实例配置文件下拉列表:
请注意
一旦集群启动一个实例配置文件,这个集群附加权限的人都可以访问底层资源控制的这个角色。防止不必要的访问,可以使用集群访问控制限制权限集群。
火花配置
微调刺激就业,你可以提供自定义的火花配置属性在一个集群中配置。
在集群配置页面,单击高级选项切换。
单击火花选项卡。
在火花配置进入配置属性,每行一个键-值对。

当您配置集群使用集群API,设置火花属性spark_conf字段创建新集群API或更新集群配置API。
为所有集群设置火花属性,创建一个全球init脚本:
dbutils。fs。把(“dbfs: /砖/ init / set_spark_params.sh”,”“”| # ! / bin / bash|猫| < < EOF的> / conf / 00-custom-spark-driver-defaults.conf /砖/驱动程序|(司机){|“spark.sql.sources。partitionOverwriteMode”=“动态”|}| EOF”“”。stripMargin,真正的)
检索一个火花配置属性从一个秘密
砖建议存储敏感信息,比如密码,秘密而不是明文。引用一个秘密的火花配置,使用下面的语法:
火花。<属性名>{{秘密/ < scope-name > / <秘密名字>}}
例如,设置一个火花配置属性密码秘密存储的值秘密/ acme_app /密码:
火花。密码{{秘密/ acme-app /密码}}
有关更多信息,请参见语法引用火花配置中的秘密财产或环境变量。
环境变量
您可以配置自定义环境变量,您可以访问init脚本在一个集群上运行。砖还提供了预定义的环境变量在init脚本,您可以使用。你不能覆盖这些预定义的环境变量。
在集群配置页面,单击高级选项切换。
单击火花选项卡。
设置环境变量环境变量字段。

集群的标签
集群标签允许您方便地监视各种团体所使用的云资源的成本在你的组织中。您可以指定标签作为键值对,当你创建一个集群,和砖这些标签适用于云资源的虚拟机磁盘卷,以及DBU使用报告。
集群为集群从池中,自定义标签只应用于DBU使用报告,不传播到云资源。
为详细的信息关于池和集群标签类型一起工作,明白了使用集群和池监控使用标签。
为了方便起见,砖四默认标签适用于每个集群:供应商,创造者,ClusterName,ClusterId。
此外,就业集群,砖适用两个默认标签:RunName和JobId。
对资源使用的砖SQL,砖也是默认的标签SqlWarehouseId。
警告
不指定一个自定义标记的钥匙吗的名字一个集群。每个集群都有一个标签的名字其价值是由砖。如果你改变的键相关联的值的名字,集群可以通过砖不再被跟踪。因此,集群可能不会成为闲置后终止了并将继续产生使用成本。
你可以添加自定义标记当您创建一个集群。集群配置标签:
在集群配置页面,单击高级选项切换。
在页面的底部,单击标签选项卡。
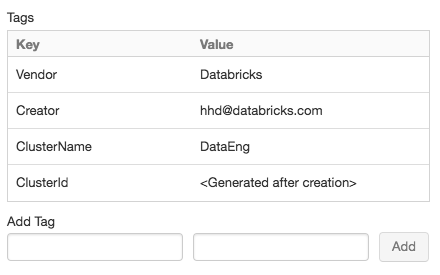
为每个定制标记添加一个键-值对。您可以添加45定制标记。

更多细节,请参见<用法标签链接>。
实施强制性的标签
确保某些标签总是填充在创建集群时,你可以把一个特定的政策,您的帐户的主要我角色(期间创建的账户设置;请联系AWS管理员如果你需要访问)。我的政策应包括明确的否认声明强制性标签键和可选值。创建集群将会失败如果需要标签的允许的值没有提供。
例如,如果您想要执行部门和项目标签,只有指定值允许前者和后者的自由格式的非空值,你可以申请一个我这样的政策:
{“版本”:“2012-10-17”,“声明”:({“席德”:“MandateLaunchWithTag1”,“效应”:“否认”,“行动”:(“ec2: RunInstances”,“ec2: CreateTags”),“资源”:“攻击:aws: ec2:地区:accountId:实例/ *”,“条件”:{“StringNotEqualsIgnoreCase”:{“aws: RequestTag /部门”:(“Deptt1”,“Deptt2”,“Deptt3”]}}},{“席德”:“MandateLaunchWithTag2”,“效应”:“否认”,“行动”:(“ec2: RunInstances”,“ec2: CreateTags”),“资源”:“攻击:aws: ec2:地区:accountId:实例/ *”,“条件”:{“StringNotLike”:{“aws: RequestTag /项目”:“? *”}}}]}
这两个ec2: RunInstances和ec2: CreateTags行动所需的每个标签有效覆盖场景的集群,只有随需应变的情况下,只有现货实例,或两者兼而有之。
提示
砖建议你为每个标记添加一个单独的政策声明。整体政策可能成为长,但更容易调试。看到我运营商参考政策条件对运营商的列表,可以使用在一个政策。
请注意
集群创建错误因为我显示出政策编码错误消息开始:
云提供商发射失败:云提供商设置集群时遇到错误。
编码的消息,因为授权状态的细节可以构成特权的用户信息请求的行动不应该看到。看到DecodeAuthorizationMessage API(或CLI)等信息如何解码信息。
SSH访问集群
请注意
你不能使用SSH登录到一个集群安全集群连接启用。
SSH允许您登录到Apache火花集群为先进的故障诊断和远程安装定制软件。
一个相关的特性,看到网络终端。
本节描述如何配置您的AWS帐户启用入口访问你和公钥的集群,以及如何打开SSH连接到集群节点。
配置安全组
你必须更新砖安全组的AWS帐户给入口访问的IP地址将启动SSH连接。你可以设置这一个IP地址或提供一系列代表整个办公室的IP范围。
在AWS控制台,找到砖安全组。它将有一个标签相似
< databricks-instance > -worker-unmanaged。(例如:dbc-fb3asdddd3-worker-unmanaged)编辑安全组和添加一个TCP规则允许入站端口
2200年工人的机器。它可以是一个单一的IP地址或一个范围。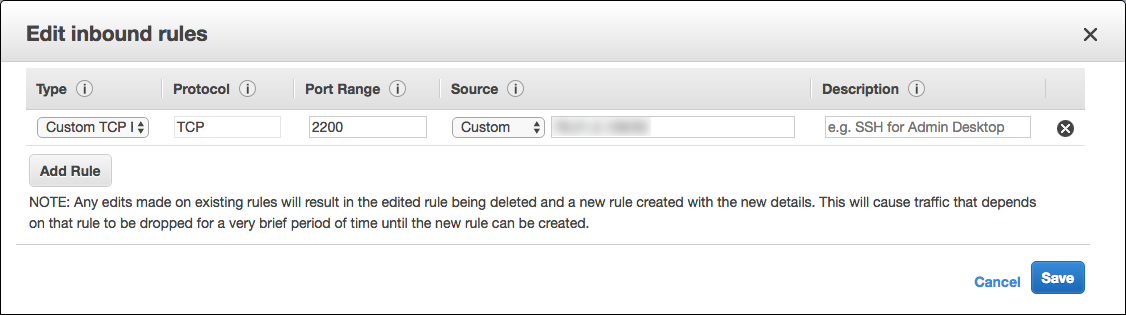
确保你的电脑和办公室让你发送TCP流量端口
2200年。

生成SSH密钥对
创建一个SSH密钥对通过终端会话中运行以下命令:
ssh - keygen rsa - t - b4096年- c“email@example.com”
您必须提供目录的路径你想保存的公钥和私钥。保存公钥与扩展.pub。
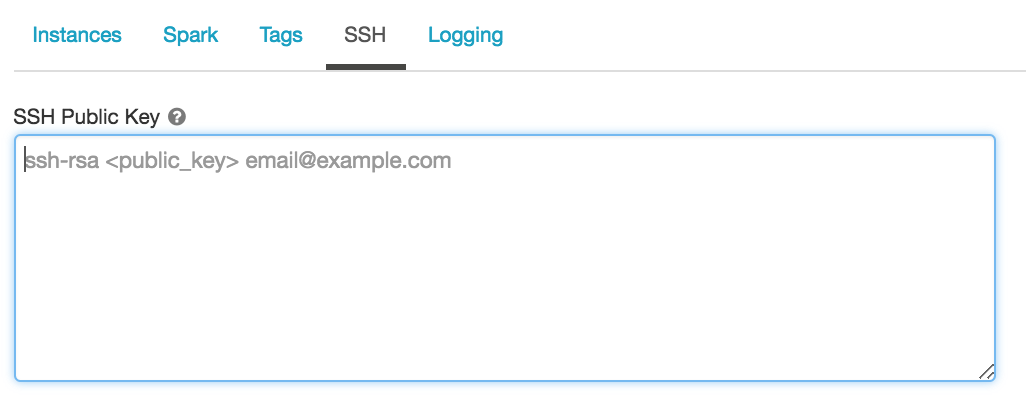
现有的集群配置您的公钥
如果你有一个集群和集群创建期间没有提供公共密钥,您可以通过运行这段代码注入的公钥从任何笔记本连接到集群:
瓦尔publicKey=“把你的公钥这里”defaddAuthorizedPublicKey(关键:字符串):单位={瓦尔弗兰克-威廉姆斯=新java。io。FileWriter(“/ home / ubuntu / . ssh / authorized_keys”,/ *添加* /真正的)弗兰克-威廉姆斯。写(“\ n”+关键)弗兰克-威廉姆斯。关闭()}瓦尔numExecutors=sc。getExecutorMemoryStatus。键。大小sc。并行化(0直到numExecutors,numExecutors)。foreach{我= >addAuthorizedPublicKey(publicKey)}addAuthorizedPublicKey(publicKey)

集群日志交付
当您创建一个集群时,您可以指定一个位置提供的日志引发司机节点,工作节点,和事件。日志是每5分钟发送到您所选择的目的地。终止一个集群时,砖保证交付的所有日志生成到集群是终止。
日志的目的地取决于集群ID。如果指定的目的地dbfs: / cluster-log-delivery、集群日志0630 - 191345 leap375交付给dbfs: / cluster-log-delivery / 0630 - 191345 leap375。
配置日志交付地点:
在集群配置页面,单击高级选项切换。
单击日志记录选项卡。
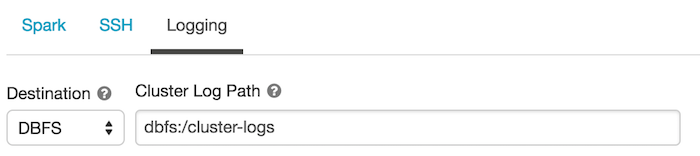
选择一个目的地类型。
进入集群日志路径。

S3 bucket的目的地
如果你选择一个S3目的地,您必须配置的集群实例配置文件,可以访问桶。这个实例配置文件必须都propertynames和PutObjectAcl权限。一个示例实例配置文件已经包括了你的便利。看到S3访问配置实例配置文件说明如何设置一个实例配置文件。
{“版本”:“2012-10-17”,“声明”:({“效应”:“允许”,“行动”:(“s3: ListBucket”),“资源”:(“攻击:aws: s3::: < my-s3-bucket >”]},{“效应”:“允许”,“行动”:(“s3: propertynames”,“s3: PutObjectAcl”,“s3: GetObject”,“s3: DeleteObject”),“资源”:(“攻击:aws: s3::: < my-s3-bucket > / *”]}]}
请注意
这个功能也可以在REST API。看到集群API。
Init脚本
一个集群节点初始化运行初始化脚本是一个shell脚本,在启动每个集群节点之前火花司机或工人JVM开始。您可以使用init脚本安装包和库不包含在砖运行时,修改JVM系统类路径,设置系统属性和环境变量所使用的JVM,或修改配置参数,以及其他配置任务。
您可以将init脚本附加到一个集群扩展高级选项部分并单击Init脚本选项卡。
有关详细说明,请参见init脚本是什么?。