管理集群
介绍如何管理Databricks集群,包括显示、编辑、启动、终止、删除、访问控制、性能和日志监控。
显示集群
请注意
本文描述遗留集群UI。有关预览UI的详细信息,包括集群访问模式的术语更改,请参见创建集群.有关新的和旧的集群类型的比较,请参见集群UI更改和集群访问模式.
若要在工作区中显示集群,请单击![]() 计算在侧栏中。
计算在侧栏中。
“计算”页面以两个选项卡显示集群:通用的集群而且工作的集群.


左边有两列显示集群是否被固定,以及集群的状态:

 ,终止
,终止








在最右边的右边通用的集群TAB是一个可以用来终止集群的图标。
你可以使用三个按钮的菜单 来重新启动,克隆,删除,或编辑权限对于集群。不可用的菜单选项显示为灰色。
来重新启动,克隆,删除,或编辑权限对于集群。不可用的菜单选项显示为灰色。

的通用的集群TAB显示笔记本数量 附加到集群。
附加到集群。

固定一个集群
集群终止后30天,将被永久删除。即使在集群被删除之后,也要保持一个通用的集群配置终止30多天,一个管理员可以固定集群.最多可钉住100个集群。
你可以从集群列表或集群详情页面固定一个集群:


以JSON文件的形式查看集群配置
有时将集群配置查看为JSON会很有帮助。类创建类似集群时,这尤其有用集群API 2.0.查看现有集群时,只需转到配置选项卡上,单击JSON在选项卡的右上角,复制JSON,并将其粘贴到API调用中。JSON视图是现成的。
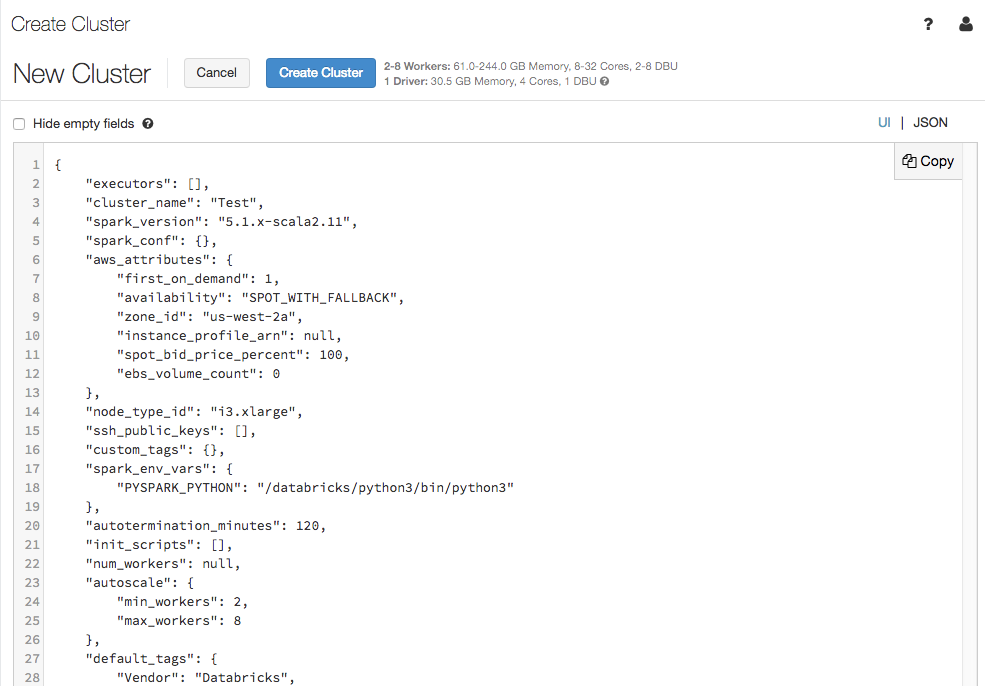
编辑集群
您可以从集群详细信息页面编辑集群配置。在“计算池”页面单击集群名称,可进入集群详情界面。

方法也可以调用编辑API端点以编程方式编辑集群。
请注意
附加到集群的笔记本和作业在编辑后仍然保持附加状态。
安装在集群上的库在编辑后仍保持安装状态。
如果编辑正在运行的集群的任何属性(除了集群大小和权限),必须重新启动它。这可能会中断当前正在使用集群的用户。
只能编辑正在运行或已终止的集群。但是,您可以进行更新权限对于不在集群详细信息页上的状态的集群。
有关可编辑的集群配置属性的详细信息,请参见配置集群.
克隆集群
您可以通过克隆现有集群来创建新的集群。
从集群列表中,单击三个按钮菜单并选择克隆从下拉列表。

在集群详细信息页面中,单击 并选择克隆从下拉列表。
并选择克隆从下拉列表。

打开用集群配置预填充的集群创建表单。克隆中不包含现有集群中的以下属性:
集群的权限
安装库
连接笔记本电脑
控制对集群的访问
的集群访问控制管理控制台允许管理员和委托用户向其他用户提供细粒度的集群访问权限。集群访问控制有两种类型:
集群创建权限:管理员可以选择允许哪些用户创建集群。

集群级权限:具有可以管理集群的权限可以从集群列表或集群详细信息页面配置其他用户是否可以附加到该集群、重新启动、调整大小和管理该集群。
从集群列表中单击
 烤肉菜单(/_static/images/clusters/cluster-3-buttons.png),然后选择编辑权限.
烤肉菜单(/_static/images/clusters/cluster-3-buttons.png),然后选择编辑权限.
在集群详细信息页面中,单击
 并选择权限.
并选择权限.

 烤肉菜单(/_static/images/clusters/cluster-3-buttons.png),然后选择编辑权限.
烤肉菜单(/_static/images/clusters/cluster-3-buttons.png),然后选择编辑权限.若要了解如何配置集群访问控制和集群级权限,请参见集群访问控制.
启动集群
除了创建一个新的集群,您还可以启动一个以前的集群终止集群。这使您可以使用原来的配置重新创建先前终止的集群。
您可以从集群列表、集群详细信息页面或记事本中启动集群。
从集群列表中启动集群,单击箭头:

单击,在集群详情页面启动集群开始:

若要从笔记本启动集群,请单击连接下拉到笔记本上面。在那里,您可以选择要附加到您的笔记本的集群。




方法也可以调用开始API端点以编程方式启动集群。
Databricks用惟一的集群ID.当您启动一个终止的集群时,Databricks将使用相同的ID重新创建集群,自动安装所有库,并重新连接笔记本。
终止集群
为了节省集群资源,可以终止集群。已终止的集群不能运行笔记本或作业,但存储了其配置,以便能够运行重用(或者在某些类型的工作中-)自动启动)在稍后的时间。您可以手动终止集群,也可以将集群配置为在指定的不活动时间后自动终止。Databricks在集群终止时记录相关信息。当终止的集群数量超过150个时,将删除最老的集群。
除非集群是固定当集群终止后30天,该集群将被自动永久删除。
终止的集群出现在集群列表中,集群名称左侧有一个灰色圆圈。



自动终止
您也可以为集群设置自动终止。在创建集群期间,可以指定以分钟为单位的不活动时间段,在此时间段之后,您希望集群终止。如果当前时间与在集群上运行的最后一个命令之间的差值大于指定的不活动时间,Databricks将自动终止该集群。
当集群上的所有命令(包括Spark作业、Structured Streaming和JDBC调用)都已完成执行时,集群就被认为是非活动的。这并不包括通过SSH-ing运行到集群中的命令和运行bash命令。
警告
集群不报告使用DStreams导致的活动。这意味着自动终止集群可能在运行DStreams时被终止。关闭运行DStreams的集群的自动终止,或者考虑使用结构化流。
自动终止特性只监控Spark作业,不监控用户自定义的本地进程。因此,如果所有Spark作业都已完成,即使本地进程正在运行,集群也可能被终止。
空闲集群在终止前的非活动期间继续累积DBU和云实例费用。
删除集群
删除集群将终止集群并删除其配置。
警告
您无法撤消此操作。
不能删除固定集群。要删除固定的集群,必须先由管理员解除固定。
从集群列表中,单击三个按钮菜单并选择删除从下拉列表。
在集群详细信息页面中,单击并选择删除从下拉列表。
方法也可以调用永久删除API端点以编程方式删除集群。
重新启动集群以使用最新的映像更新它
当您重新启动集群时,它将获得计算资源容器和虚拟机主机的最新映像。为长时间运行的集群安排定期重启尤为重要,这些集群通常用于处理流数据等应用程序。
您有责任定期重新启动所有计算资源,以使映像保持最新的映像版本。
重要的
如果您启用遵从性安全配置文件对于您的帐户或工作空间,长时间运行的集群将在25天后自动重新启动。Databricks建议管理员在集群运行25天之前重新启动集群,并在计划的维护窗口内执行该操作。这降低了自动重启中断预定作业的风险。
重启集群有多种方式:
使用UI从集群详细信息页面重新启动集群。在“计算池”页面单击集群名称,可进入集群详情界面。点击重新启动.
使用集群API重新启动集群。
使用Databricks提供的脚本确定集群运行了多长时间,并可选地重新启动它们如果它们自启动以来超过了指定的天数
运行一个脚本来确定您的集群已经运行了多少天,并有选择地重新启动它们
如果您是工作空间管理员,您可以运行一个脚本来确定每个集群已经运行了多长时间,如果它们的时间超过了指定的天数,可以选择重新启动它们。Databricks将此脚本作为笔记本提供。
脚本的第一行定义了配置参数:
min_age_output:集群可运行的最大天数。默认值是1。perform_restart:如果真正的时,脚本将重新启动年龄大于指定天数的集群min_age_output.默认为假,它标识长时间运行的集群,但不会重新启动它们。secret_configuration:替换REPLACE_WITH_SCOPE而且REPLACE_WITH_KEY与一个秘密作用域和密钥名称.有关设置秘密的更多细节,请参阅笔记本。
警告
如果你设置perform_restart来真正的,脚本会自动重新启动符合条件的集群,这可能会导致活动作业失败并重置打开的笔记本。要降低中断工作空间的关键业务作业的风险,请计划一个定期维护窗口,并确保通知工作空间用户。
通过Apache Spark界面查看集群信息
您可以在Spark界面中查看Spark作业的详细信息火花UI页签。

您可以获得有关活动集群和终止集群的详细信息。
如果重新启动已终止的集群,Spark界面显示的是重新启动后的集群信息,而不是已终止集群的历史信息。
查看集群日志
Databricks提供了三种集群相关活动的日志记录:
集群事件日志,捕获集群生命周期事件,如创建、终止、配置编辑等。
Apache Spark驱动和worker日志,您可以使用它进行调试。
集群初始化脚本日志,对于调试init脚本很有价值。
本节讨论集群事件日志以及驱动程序和工作日志。关于init-script日志的详细信息请参见初始化脚本日志.
集群事件日志
集群事件日志显示重要的集群生命周期事件,这些事件由用户操作手动触发或由Databricks自动触发。这些事件会影响集群整体的运行以及集群中运行的作业。
有关受支持的事件类型,请参阅REST APIClusterEventType数据结构。
事件存储60天,这与Databricks中的其他数据保留时间相当。

 在按事件类型过滤…字段并选择一个或多个事件类型复选框。
在按事件类型过滤…字段并选择一个或多个事件类型复选框。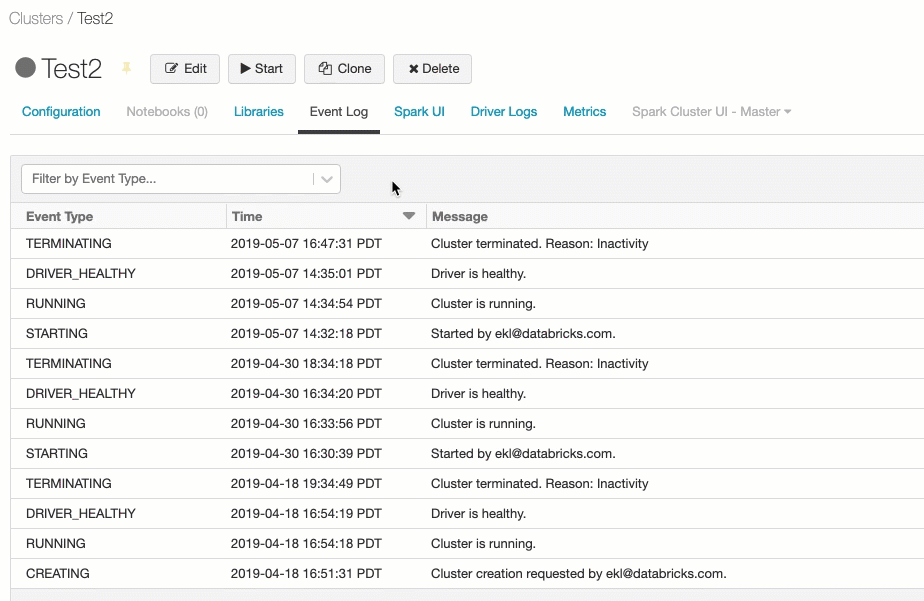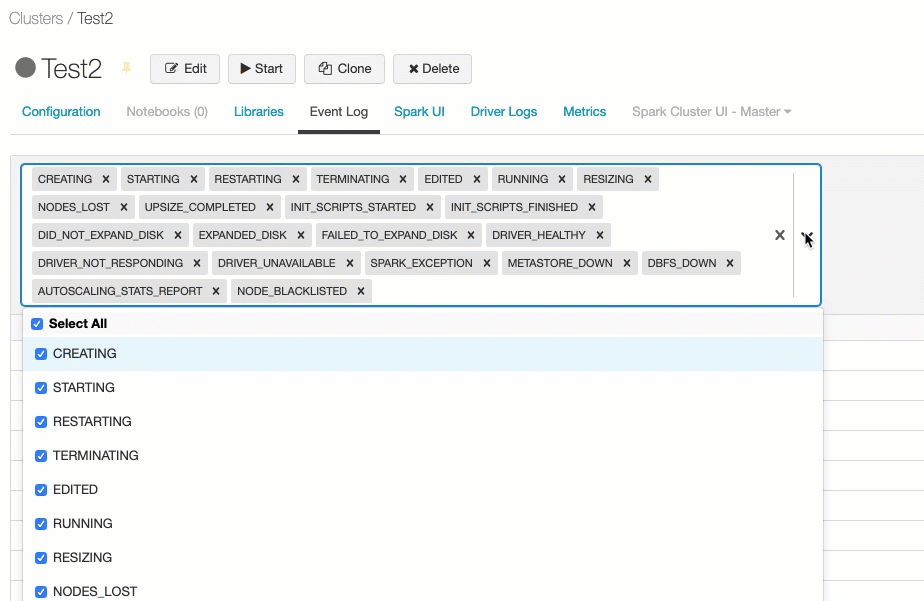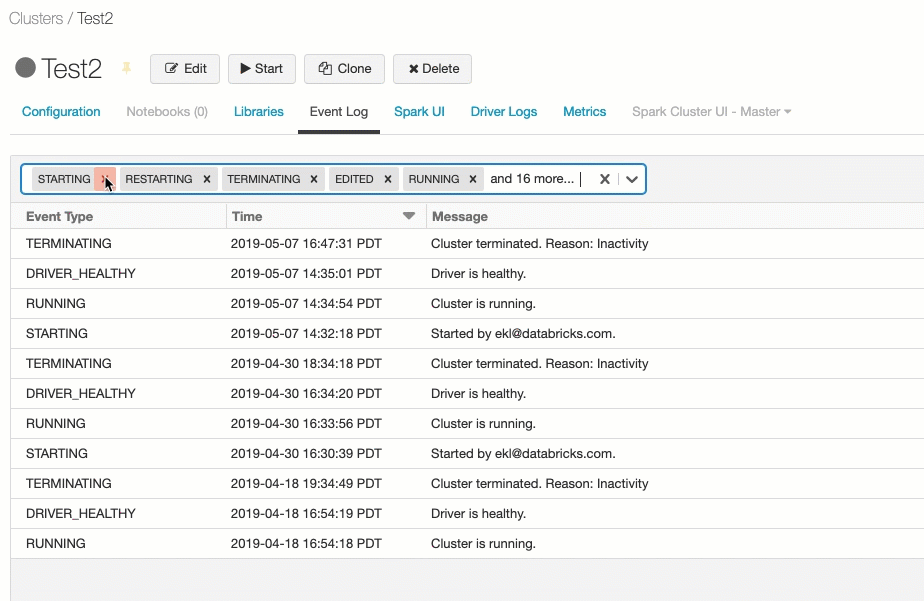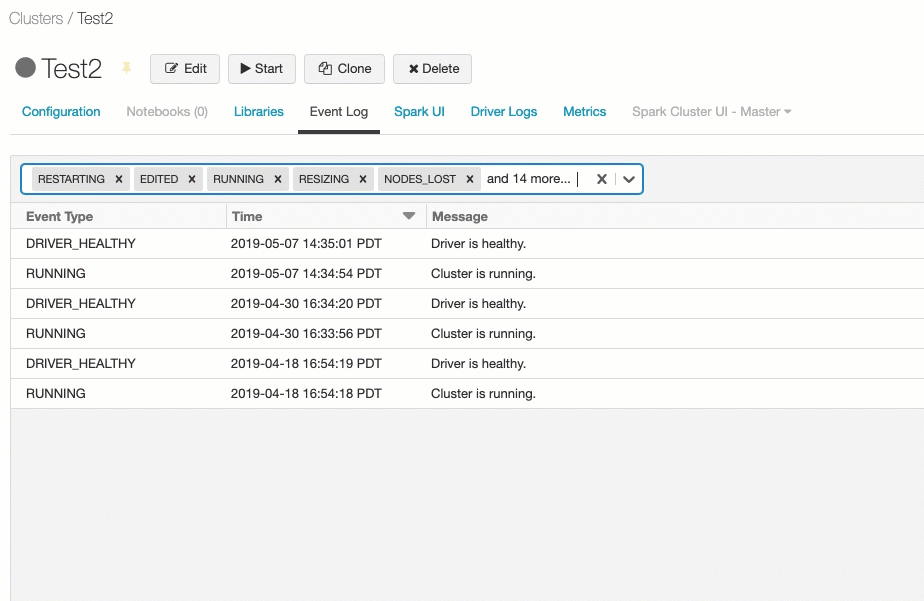

集群驱动和工作日志
笔记本、作业和库中的直接打印和日志语句会转到Spark驱动程序日志中。这些日志有三个输出:
标准输出
标准错误
Log4j日志
您可以从司机日志页签。单击日志文件的名称即可下载。
您可以通过Spark UI查看Spark worker日志。你也可以配置日志传递位置对于集群。工作日志和集群日志都被传递到您指定的位置。
监视性能
为了帮助您监控Databricks集群的性能,Databricks提供了访问神经节来自集群详细信息页面的度量。
你可以安装Datadog代理在集群节点上发送Datadog指标到您的Datadog帐户。
Ganglia指标
要访问Ganglia UI,请导航到指标页签。对于所有Databricks运行时,在Ganglia UI中都可以使用CPU指标。GPU指标可用于启用GPU的集群。

要查看实时指标,请单击Ganglia UI链接。
单击快照文件查看历史指标。快照包含所选时间之前一小时的聚合指标。
Datadog指标
你可以安装Datadog代理在集群节点上发送Datadog指标到您的Datadog帐户。下面的笔记本演示如何在集群上使用集群范围的初始化脚本.
要在所有集群上安装Datadog代理,请使用全局初始化脚本在测试集群范围的初始化脚本之后。
退役现场实例
请注意
此特性在Databricks Runtime 8.0及以上版本上可用。
因为现货实例可以降低成本,使用现货实例而不是按需实例创建集群是运行作业的常用方法。但是,站点实例可以被云提供商调度机制抢占。抢占现场实例可能会导致正在运行的作业出现问题,包括:
Shuffle读取失败
Shuffle数据丢失
RDD数据丢失
工作的失败
您可以启用退役来帮助解决这些问题。退役利用了云提供商通常在现场实例退役之前发送的通知。当包含执行器的现场实例收到抢占通知时,退役进程将尝试将shuffle和RDD数据迁移到健康的执行器。最终抢占前的持续时间通常为30秒到2分钟,具体取决于云提供商。
Databricks建议在启用退役功能时启用数据迁移。一般情况下,随着迁移数据的增多,出现错误的可能性会逐渐减小,包括shuffle抓取失败、shuffle数据丢失、RDD数据丢失等。数据迁移还可以减少重新计算,节省成本。
退役是最好的努力,并不能保证在最终抢占之前所有数据都可以迁移。当正在运行的任务正在从执行器获取shuffle数据时,退役不能保证不会出现shuffle读取失败。
启用退役后,由现货实例抢占引起的任务失败不会被添加到失败的尝试总数中。由抢占引起的任务失败不会被计算为失败尝试,因为失败的原因是任务外部的,不会导致作业失败。
为了启用退役,在创建集群时设置Spark配置设置和环境变量:
启用应用程序退役:
火花.解除.启用真正的
使用实例启用系统退役时shuffle数据迁移功能。
火花.存储.解除.启用真正的火花.存储.解除.shuffleBlocks.启用真正的
启用退役时RDD缓存数据迁移功能。
请注意
当RDD StorageLevel复制设置为大于1时,Databricks不建议启用RDD数据迁移,因为副本可以确保RDD不会丢失数据。
火花.存储.解除.启用真正的火花.存储.解除.rddBlocks.启用真正的
为工人启用退役:
SPARK_WORKER_OPTS=“-Dspark.decommission.enabled = true”
设置这些自定义Spark配置属性:
在新的集群页,单击高级选项切换。
单击火花选项卡。


要从UI访问工作人员的退役状态,请导航到Spark Cluster UI - Master标签:

当退役完成时,退役的执行程序在中显示丢失原因Spark UI > executor在集群的详细信息页面的选项卡:

