介绍砖Lakehouse监控
预览
这个特性是在公共预览版在以下区域:一来就,us-east-1,us-east-2,us-west-2,ap-southeast-2。注册访问,填写这张表格。
砖Lakehouse监控可以监控所有的表在您的帐户。您还可以使用它来跟踪性能的机器学习模型和model-serving端点通过监测推理表由模型的输出。
砖Lakehouse监控计算并存储度量数据质量,数据分布和漂移。它可以帮助你回答问题如下:
数据完整性是什么样子,它如何随时间变化的?例如,什么是零或零值的分数在当前数据,并增加了吗?
数据的统计分布是什么样子,以及它如何随时间变化的?例如,一个数值列的第90个百分位是什么?或者,什么是分类列中的值的分布,和它如何不同于昨天?
之间有漂移当前数据和已知的基线,或连续时间窗口之间的数据?
什么统计分布或漂移或切片数据的一个子集的样子?
毫升模型输入和预测如何转移?
随着时间的推移模型性能趋势如何?模型版本执行比版本B吗?
此外,砖Lakehouse监控允许您控制的时间粒度的观察和设置自定义指标。
需求
以下是需要使用砖Lakehouse监控:
全民必须启用您的工作区目录,你必须能够访问数据砖SQL。
只有δ支持管理和外部表监测。
请注意
砖Lakehouse监控使用serverless计算工作。你的账户是计算与这些工作相关的宣传。
为什么监测数据是重要的
从你的数据画出有用的见解,你必须有信心你的数据的质量。监测数据提供了定量措施,帮助您跟踪并确认数据的质量和一致性。当你发现变化表的数据分布或相应模型的性能,表由砖Lakehouse监测可以捕获和提醒你改变,可以帮助你确定原因。
砖Lakehouse监测是如何工作的
在砖监控表,您创建一个监视器连接到桌子上。监控性能的机器学习模型中,您将监视存储模型推理表的输入和相应的预测。
砖Lakehouse监测提供了以下类型的分析:时间序列,快照和推理。
概要文件类型 |
描述 |
|---|---|
时间序列 |
比较数据分布跨越时间窗口。您指定的粒度计算度量(例如,1天)来比较你的数据分布会随着时间而改变。这种类型的配置文件需要一个时间戳列。 |
快照 |
与时间序列相比,概要文件快照监视器表的完整内容如何随时间变化。指标计算表中所有数据,并监控表在每次刷新监控状态。 |
推理 |
这个表包含预测输出值由机器学习分类或回归模型。这个表包含一个时间戳,ID模型,模型的输入(特性),一个列包含模型的预测,以及可选的列包含独特观察ID和地面实况标签。它也可能包含元数据,如人口统计信息,不是作为模型的输入,而是公平和偏见的可能有用的调查或其他监测。一个推理剖面类似于时间序列资料,也包括质量度量模型。 |
本节简要描述了输入表使用的砖Lakehouse监测和它产生的指标表。图中显示了输入之间的关系表,指标表,监视器和仪表板。
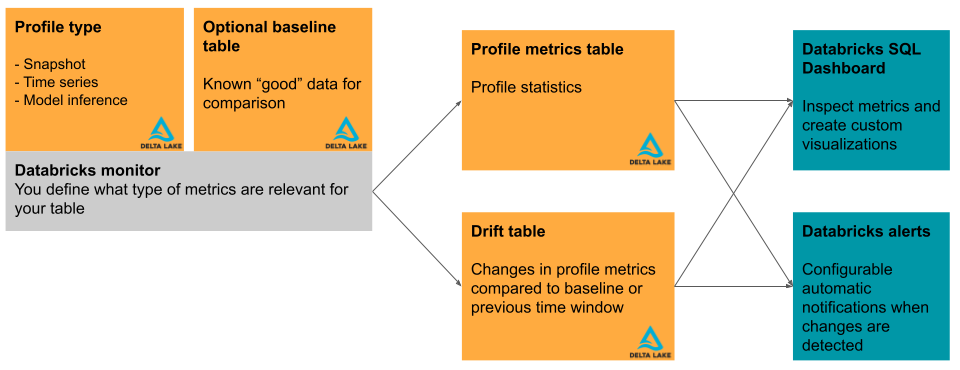
主要表和基准表
除了要监视的表,称为“主要表”,您可以选择指定一个表作为参考基准测量漂移,或随时间的变化值。基准表是非常有用的,当你有一个样本,你希望你的数据是什么样子的。然后计算漂移的想法是相对于预期的数据值和分布。
基线表应该包含一个数据集,反映了预期的输入数据的质量,统计分布而言,单个的列分布,缺失值,和其他特征。它应该监控表的匹配模式。表的例外是时间戳列使用时间序列或者推理概要文件。如果列失踪在主表或基线表,监控使用的最优启发式计算输出指标。
对于使用快照概要文件的监控,基线表应该包含的快照数据的分布代表一个可接受的质量标准。例如,在年级分配数据,一个可能设置基线前几堂课成绩均匀分布。
为监控使用时间序列资料,代表时间的基准表应该包含数据窗口(s),数据分布代表一个可接受的质量标准。例如,在天气数据,您可能将基线设置为一个星期,月或年的温度接近预期的正常温度。
对于使用一个推理概要文件的监视器,一个不错的选择对于一个基线数据用于训练或被监控模型进行了验证。通过这种方式,用户可以提醒当数据相对于漂流模型训练和验证。这个表应该包含相同的功能列作为主要的表,而且应该是一样的model_id_col这是指定主表的InferenceLog聚合数据一致。理想情况下,测试或验证设置用来评估模型应该被用来确保类似的模型质量指标。