

燃烧通过电子健康记录实时闷烧




2021年1月28日, 在工程的博客
检查解决方案加速器下载笔记本在这个博客。
在以前的博客,我们看两个单独的工作流处理病人数据的电子健康记录(EHR)。在这些流程中,我们专注于一个历史批电子健康档案数据的提取。然而,在现实世界中,数据不断输入成电子健康档案。对许多重要的预测医疗分析用例,脓毒症的预测或ER过度拥挤,我们需要使用流经EHR的临床资料。
数据实际上流经一个EHR如何?一般来说,有几个通过细化。在一些EHR实现,数据首先土地以接近实时的方式到NoSQL风格经营商店。一天后,新数据在这个NoSQL存储从操作存储到规范化和SQL存储空间。其他EHR的实现有不同的数据库实现,但是,通常有一个延迟之前最后一个“历史”EHR的记录数据可用于批量分析。在实时分析临床资料,我们需要访问了基于推的HL7消息源或基于FHIR API端点。这些提要和端点包含各种健康信息的数据。例如,承认/放电/转移(ADT)消息可以用来跟踪当病人之间或移动单位,而订单输入(ORM)消息/修改/取消订单,如给病人氧或运行一个特定的实验室测试。通过提要和资源结合在一起,我们可以得到一个全面的查看我们的病人和医院。
医疗团队和临床医师面临的问题在构建实时分析系统的电子健康档案数据:我应该使用FHIR或HL7吗?我该如何解析记录?我该如何存储和合并数据?在这个博客中,我们引入闷烧,操纵电子健康档案数据使用Apache的开源库引发™。闷烧提供Spark-native数据加载器和api将HL7消息转换为SQL DataFrames Apache火花™。为了简化操作、验证和重新映射的内容信息,闷烧添加SQL函数来访问消息字段。最终,这使得它可以构建流媒体管道来摄取和分析HL7数据在几分钟内,同时提供一个易于使用的声明性语法,就不需要学习底层库像哈皮神。这些管道可以实现近实时延迟,同时实现数据统一在医疗数据来源通过利用开源标准bob下载地址三角洲湖
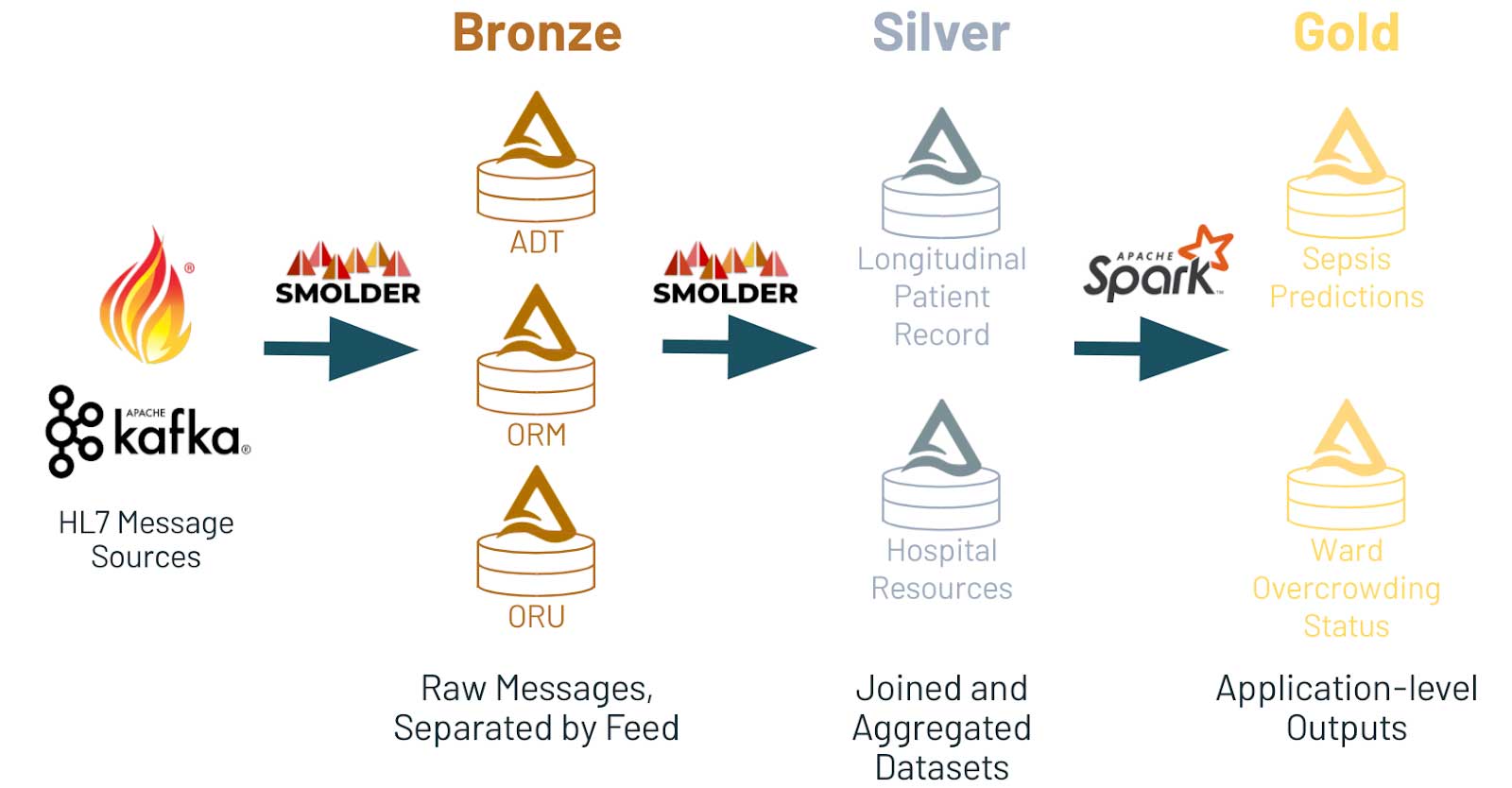
在这个博客的其余部分,我们将使用闷烧库EHR近实时的数据分析来确定患者保健利用率高。首先,我们将做一个深潜水的HL7v2标准它是如何工作的,它意味着什么。然后,我们将讨论闷烧的设计原则指导我们的发展。最后,我们将展示如何将数据加载到三角洲湖在实时通过使用Apache火花的结构化流api,和闷烧图书馆。我们将使用这些数据来驱动一个仪表板,帮助我们识别实时我们高端应用的病人在医院系统的地方。
使用HL7消息
HL7v2
HL7代表Health Level 7国际标准组织,定义了医疗的互操作性标准。他们维护多个著名的标准,如新兴FHIR医疗数据交换标准定义REST api和JSON模式交换医疗数据,基于xml的(合并)临床文档体系结构(CDA和C-CDA)标准,原HL7v2标准。这些标准有不同的目的:FHIR定义了用于应用程序开发的API端点,C-CDA定义标准,是最好的用于交换历史有关病人的信息,和HL7v2消息方言,捕获实时更新状态和数据,存在于一个电子健康档案。虽然有很多最近的兴趣FHIR对于应用程序开发,HL7v2通常是最合适的标准用于分析由于其广泛采用。目前大多数机构遗留系统利用HL7提要。因此,更容易进入更大的数据量,创造更丰富的基础分析,无需等待每个系统支持FHIR。同时,HL7提要本身通常是基于TCP / IP的数据流,而网格基于事件流体系结构非常干净。
MSH | ^ ~ \ & | | | | | 20201020150800.739 + 0000 | | ADT ^ A03 ^ ADT_A03 | 11374301 | P | 2.4犯| A03 | 20170820074419 - 0500PID | | | d40726da-9b7a-49eb-9eeb-e406708bbb60 | |海勒^ Keneth | | | | | | 140 Pacocha套件52 ^ ^马萨诸塞州北安普顿^ ^ ^厄尔pv | |的| ^ ^ ^迪金森医院公司动态| | | | | 49318 f80-bd8b-3fc7-a096-ac43088b0c12厄尔的^ ^ | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | | 20170820074419 - 05 \00代码:这是一个HL7消息。这个消息是一个ADT_A03消息,它提供了信息病人出院了。我们生成此消息使用开源Synthea医疗记录模拟器。
HL7v2以来我们已经谈妥,让我们先看一个HL7v2消息的内容。上图显示了单个HL7v2消息,多行,管分隔。还有一个规范的XML版本。FHIR模式是一种基于json规范。对于每个消息类型和部分指定的类型是HL7v2规范。消息一段的每一行,第一列是“段描述符,它告诉我们什么是模式的部分。当我们解析ADT_A03消息上面,我们有两个部分;“PID”段标识符包含病人的身份信息和“发现”部分包含有关病人的信息访问他们退出。在病人的身份,第二个字段的ID是病人,第四个字段名称,等等。
所以,你如何使用这些数据?我们帮助多个客户摄取HL7数据转换成砖使用Apache的火花的流媒体功能。从历史上看,我们看到客户之间建立一个渠道EHR和流媒体服务Apache卡夫卡™️、运动或EventHubs。然后他们连接其中一个流公交车到Apache火花,收益率DataFrame的消息文本。最后,他们解析本文使用手写的解析器或低级库哈皮神。
虽然这种方法对一些客户,需要手工编写解析库,或者依靠图书馆像哈皮神这样的开销,会造成挑战。湖的数据的一个关键好处是能够延迟验证管道。我们通常谈论这是铜层,这是摄取的数据并存储在它的原始状态。这使您可以灵活地保持观察到的历史数据,而无需做任何选择数据的大小和形状。
这是特别有用,当你要做之前历史验证和分析面向业务用例。例如,考虑的情况下验证初级保健提供者(PCP)领域。如果你发现一个医疗系统交换的卡式肺囊虫肺炎不同医生对护理团队,你会想要在所有这些记录追溯纠正这个错误。闷烧的设计、订阅这个范式。
不像哈皮神,闷烧将消息分为结构没有尝试验证之外是一个有效的HL7消息。这使我们能够获取观测数据,同时还使它可以查询和填充我们的银层。
设计闷烧,使用HL7在Apache的开源库火花
我们开始开发闷烧提供一个易于使用的系统,可以实现近实时延迟处理HL7v2消息很大的生态系统,使这些数据可访问数据科学可视化的工具。为此,我们采用了以下的方法:
- HL7消息变成DataFrames一行代码:DataFrames广泛应用在数据科学无论是通过熊猫,R,或火花,可以通过使用易于被像SQL声明性编程框架。如果我们能HL7消息加载到DataFrame一行代码,大大增加了下游的地方我们可以使用HL7消息。
- 使用简单的声明性api从消息中提取数据:虽然图书馆像哈皮神为处理HL7v2消息提供api,这些api是复杂的,面向对象的,并且需要很多知识HL7v2消息格式。如果我们可以给人们一行sql函数,它们可以HL7消息中有意义的数据,而不需要学习一种新的和复杂的API。
- 有一个一致的模式和语义HL7消息,无论来源:闷烧既支持的直接摄入HL7v2消息,以及摄入HL7v2消息来自另一个流源文本,是否像一个开源工具Apache卡夫卡或特定于云服务,如AWS的动作或Azure的EventHubs。无论源,信息总是被解析成相同的模式。再加上Apache火花的结构化流语义我们实现便携式,平台无关的代码,可以很容易地验bob体育客户端下载证和运行同样在批处理或流媒体数据处理。
最终,这种方法使得闷烧一个轻量级的图书馆,很容易学习和使用,它可以支持sla要求大量的HL7消息。现在,我们将深入闷烧的api和如何构建一个仪表板分析住院模式。
解析使用闷烧HL7消息
Apache火花™的结构化流API允许用户流程流数据通过使用火花的SQL api的扩展。加上闷烧库时,您可以加载到DataFrame HL7v2消息,要么使用闷烧读取批生HL7v2消息,或者通过使用闷烧解析HL7v2消息文本,从另一个流源。例如,如果你有一批消息加载,只需调用hl7读者:
scala > val df = spark.read.format (“hl7”).load (“路径/ / hl7消息”)df: org.apache.spark.sql。DataFrame =[信息:字符串段:数组<结构> >)< /结构>模式包含消息中的消息头列返回。消息部分嵌套的部分列,这是一个数组,其中包含两个嵌套的字段:细分的字符串id(例如,PID病人识别部分)和部分字段的数组。
闷烧也可以用来解析原始消息文本。这可能发生,如果你在一个中间有一个HL7消息喂养土地来源(例如,卡夫卡流)。要做到这一点,我们可以使用闷烧的parse_hl7_message helper函数。首先,我们开始DataFrame包含HL7消息文本:
scala>val textMessageDf=…textMessageDf: org.apache.spark.sql.DataFrame=(价值字符串):scala>textMessageDf.show ()+- - - - - - - - - - - - - - - - - - - - - - +|价值|+- - - - - - - - - - - - - - - - - - - - - - +|MSH|^~\&| || ||2020年。。。|+- - - - - - - - - - - - - - - - - - - - - - +然后,我们可以导入com.databricks.labs.smolder parse_hl7_message消息。函数对象和应用列我们想解析:
scala >进口com.databricks.labs.smolder.functions.parse_hl7_message进口com.databricks.labs.smolder.functions.parse_hl7_messagescala > val parsedDf = textMessageDf.select (parse_hl7_message(美元)“价值”)。作为(“消息”))parsedDf: org.apache.spark.sql。DataFrame =[信息:struct>>>]这个收益率相同的模式作为我们的hl7数据来源。
提取数据从HL7v2消息段使用闷烧
而闷烧HL7消息提供了一个易于使用的模式,我们还提供在com.databricks.labs.smolder辅助函数。函数来提取消息段的分支学科。例如,假设我们想要得到病人的名字,这是第五场在病人ID (PID)。我们可以提取这个segment_field函数:
scala>进口com.databricks.labs.smolder.functions.segment_field进口com.databricks.labs.smolder.functions.segment_fieldscala>val nameDf=df.select (segment_field (“PID”,4).alias(“名字”))nameDf: org.apache.spark.sql.DataFrame=(名称:字符串)scala>nameDf.show ()+- - - - - - - - - - - - - +|的名字|+- - - - - - - - - - - - - +|海勒^Keneth|+- - - - - - - - - - - - - +如果我们想让病人的名字,我们可以使用分区功能:
scala>进口com.databricks.labs.smolder.functions.subfield进口com.databricks.labs.smolder.functions.subfieldscala>val firstNameDf=nameDf.select(子域(“名字”美元,1).alias (“firstname”))firstNameDf: org.apache.spark.sql.DataFrame=(firstname:字符串)scala>firstNameDf.show ()+- - - - - - - - - - - - +|firstname|+- - - - - - - - - - - - +|Keneth|+- - - - - - - - - - - - +- 铜层包含原始消息源(例如,一个表/ ADT饲料,ORM, ORU,等等)
- 银层骨料这信息表用于下游应用程序(比如,一个纵向病人记录,聚集医院资源)
- 金层包含应用程序级的数据(例如,医院拥挤报警系统,占用每病房医院)
为什么建立三角洲湖上?首先,三角洲是一个开放的格式,确保数据便于从许多分析系统,其数据科学的生态系统是否通过Apache火花或数据仓库系统突触。此外,三角洲湖是为了支持级联流,这意味着数据可以通过铜层,流到银,最后金层。此外,三角洲湖提供了大量的方法优化我们的表来提高查询性能。例如,我们可能想查询迅速在病人ID和一个日期,因为这些是常见的字段查询:正如我们在以前的博客中讨论,我们可以使用z值。三角洲湖支持z值做多维数据集群和提供良好的性能在这两种查询模式。
开始建立一个健康三角洲湖闷烧
在这个博客中,我们介绍了闷烧,一个Apache 2许可库加载EHR的患者数据。你可以开始了阅读我们的项目文档,或创建一个叉的存储库今天开始贡献代码。了解更BOB低频彩多关于使用三角洲湖存储和处理临床数据集,我们的下载免费电子书使用真实的临床数据。您还可以使用笔记本电脑今天开始免费试用解决方案加速器。