














大规模应用自然语言处理医疗文本
这是合著的文章写在与莫里茨斯特勒合作,AI传道者,约翰·斯诺实验室。观看我们的随需应变的车间、提取真实……
下健康保险流通与责任法案(HIPAA)最低必要标准,HIPAA-covered实体(如卫生系统和保险公司)被要求做出合理的努力以确保访问受保护的健康信息(φ)是有限的最低必要的信息来达到特定的目的使用、披露、或请求。
在欧洲,GDPR列出了要求匿名化和pseudo-anonymization公司必须满足才能分析或分享医疗数据。在某些情况下,这些要求超出我们规定还要求公司编辑性别身份、种族、宗教、和联盟关系。几乎每个国家都有类似的法律保护敏感的个人和医疗信息。
这样的最低必要的标准可以创建障碍推进全民医疗研究。这是因为大部分的医疗数据的价值是半结构化和非结构化图像叙事文本,通常包含个人身份健康挑战的信息删除。这样φ很难使临床医生、研究人员、科学家和数据在一个组织中注释,火车,和开发模型,有能力预测疾病进展,作为一个例子。
合规之外,另一个关键原因de-identificationφ和医疗数据分析——特别是对于数据科学项目——是防止偏见和学习的相关性。删除数据字段,如病人的地址、姓名、民族、职业、医院名称,和医生的名字可以防止机器学习算法依赖于这些领域进行预测或建议。
领袖约翰·斯诺实验室,在医疗领域自然语言处理(NLP)和砖正在共同努力,帮助组织的过程并分析其大规模文本数据的一系列解决方案加速器为常见的NLP笔记本模板用例。你可以了解更多关BOB低频彩于我们的合作在我们之前的博客,bob体育外网下载应用自然语言处理健康大规模文本。
帮助组织自动删除敏感的患者信息,我们构建了一个联合解决方案加速器φ移除建立在砖Lakehouse卫生保健和生命科学。约翰·斯诺实验室提供了两个商业扩展的开源火花NLP图书馆——两者都是用于de-identification和匿名化任务——在这个加速器使用:
的高层介绍我们的解决方案包括加速器。
在这种解决方案加速器,我们向您展示如何将φ从医疗文件,这样他们可以共享或分析在不影响病人的身份。这是一个高度概括的工作流程:
你可以访问笔记本为一个完整的解决方案的介绍。

作为第一步,我们从云存储加载所有PDF文件,为每个人分配一个惟一的ID,并存储结果DataFrames Lakehouse到铜层。注意,原始的PDF内容都存储在一个二进制列和下游步骤可以访问。

在下一步中,我们从每个文件中提取原始文本。因为PDF文件可以有多个页面,更有效率,它首先将每个页面转换成一个图像(使用PdfToImage()),然后从图像中提取文本通过ImageToText()为每个图像。
#转换PDF文档每页图像pdf_to_image = PdfToImage () \.setInputCol (“内容”)\.setOutputCol (“图像”)#运行OCRocr = ImageToText () \.setInputCol (“图像”)\.setOutputCol (“文本”)\.setConfidenceThreshold (65年)\.setIgnoreResolution (假)
ocr_pipeline = PipelineModel(阶段= (pdf_to_image,光学字符识别])类似于SparkNLP,火花OCR的变换是一个标准化的一步调整与任何Spark-related变压器,可以在一行代码执行。
ocr_result_df = ocr_pipeline.transform (pdfs_df)请注意,您可以查看每一个图像直接在笔记本内,如下所示:

应用这种管道后,然后我们商店DataFrame提取的文本和原始图像。注意形象之间的联系,提取文本和原PDF通过PDF文件的路径保存(和独特的ID)在我们的云存储。

通常,扫描文档是低质量(由于倾斜的图像,分辨率差,等等)导致不准确的文本和数据质量不佳。为了解决这个问题,我们可以使用内置的图像预处理方法在sparkOCR提高提取文本的质量。
在下一步中,我们处理图像增加信心。火花OCR已经ImageSkewCorrector检测图像的倾斜和旋转它。OCR管道中的应用这个工具有助于调整相应的图像。然后,通过应用ImageAdaptiveThresholding工具,我们可以计算一个阈值掩码图像基于当地像素邻域和应用到图像。另一个图像处理的方法,我们可以添加管道使用形态学操作。我们可以使用ImageMorphologyOperation支持侵蚀(删除对象边界像素),扩张(添加像素在图像物体的边界),开(把小对象和细线从一个图像,同时保留更大的物体的形状和大小的图像)和关闭(相反的开放和用于填充小洞在一个图像)。
删除背景对象ImageRemoveObjects可以使用以及添加ImageLayoutAnalyzer管道,图像进行分析,确定文本的区域。我们完全开发的代码OCR加速器内的管道可以找到笔记本。
让我们看看原始图像和校正图像。

图像处理之后,我们有一个更清洁的形象增加97%的信心。

现在我们已经纠正图像偏态和背景噪音,我们修正后的文本从图像中提取结果DataFrame写入银层在三角洲。
一旦我们完成了使用火花OCR处理我们的文件,我们可以使用一个临床命名实体识别(尼珥)管道检测和提取感兴趣的实体(如姓名、出生地等)在我们的文档。我们这一过程中更详细地覆盖以前的博文从实验报告中提取肿瘤的见解。
然而,经常有φ在临床实体指出,可以用来识别和链接的个人鉴定临床实体(例如疾病状态)。因此,它是至关重要的标识这些实体φ在文本和混淆。
在这个过程中有两个步骤:提取φ实体,然后把他们藏;同时确保下游分析产生的数据集包含有价值的信息。
类似于临床尼珥,我们使用一个医疗尼珥模型(ner_deid_generic_augmented)检测φ然后我们使用混淆这些实体“伪装者法”。我们全部φ提取管道也可以在加速器中找到笔记本。
管道检测φ实体,我们可以想象与NerVisualizer如下所示。

现在来构造一个端到端的deidentification管道,我们只是模糊的步骤添加到φ提取管道替换φ假数据。
模糊= DeIdentification () \.setInputCols ([“句子”,“令牌”,“ner_chunk”])\.setOutputCol (“鉴定”)\.setMode (“混淆”)\.setObfuscateRefSource (“骗子”)\.setObfuscateDate (真正的)
obfuscation_pipeline管道(阶段= = (deid_pipeline,困惑])在下面的例子中,我们修订的诞生地病人,取而代之的是虚假的位置:

除了困惑,SparkNLP卫生保健提供pre-trained模型修订。这是一个截图显示修订的输出管道。

de-identification SparkNLP和火花OCR很好地协同工作的大规模φ。在很多情况下,联邦政府和行业法规禁止销售或共享的原始文本文件。作为演示,我们可以创建一个可伸缩的和自动化生产管道在pdf文本分类,混淆或修订φ实体,结果数据回Lakehouse写。数据团队可以轻松分享这个“洁净”数据和消除识别信息信息与下游分析师、数据科学家,或业务用户在不影响病人的隐私。下面是一个总结表的数据流数据砖。
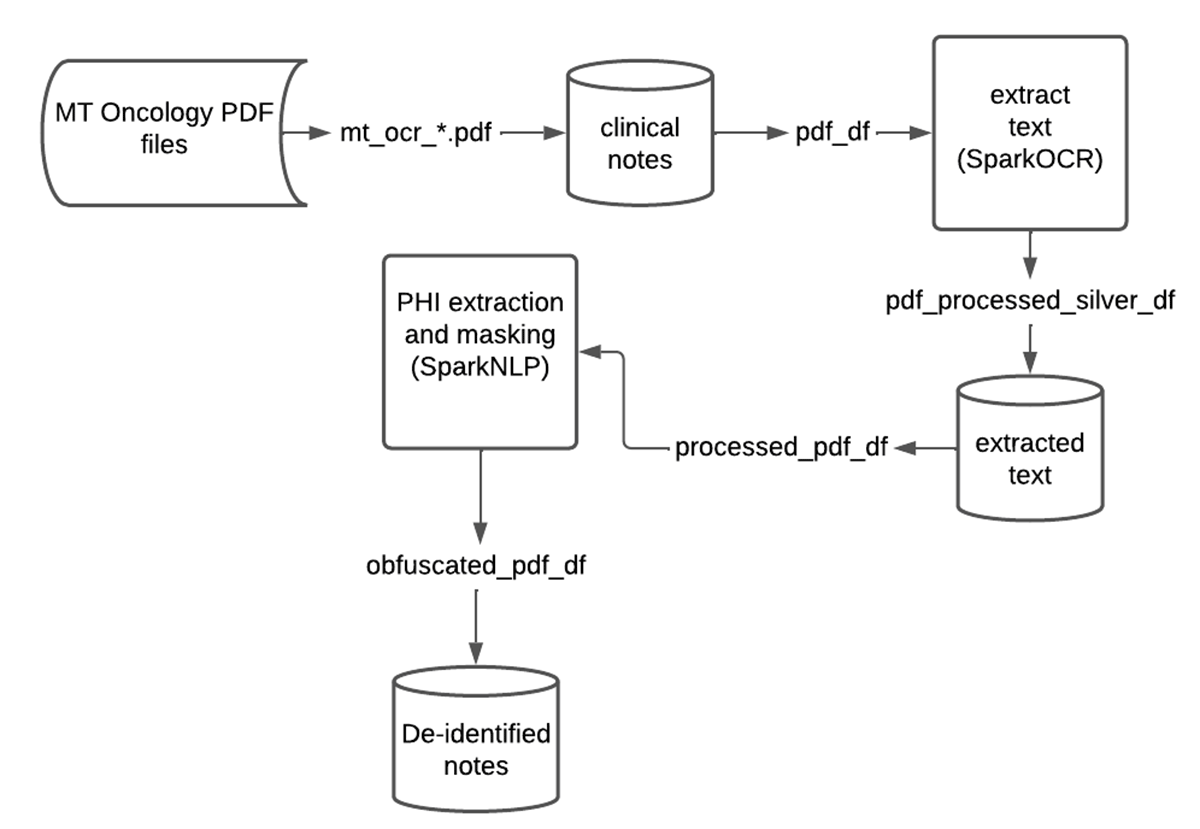
这个解决方案加速器,砖和约翰·斯诺实验室很容易自动化de-identification和困惑中包含敏感数据的PDF医疗文件。
加速器使用这个解决方案,您可以预览笔记本电脑在线并将直接导入你的砖账户。笔记本电脑包括指导安装相关的约翰·斯诺实验室NLP图书馆和许可证密钥。
你也可以访问我们Lakehouse卫生保健和生命科学页面来了解我们所有的解决方案。



