
用NLP从真实临床数据中提取肿瘤学见解




2021年9月22日 在工程的博客
癌症是主要死因和疾病,这个数字令人震惊200万新的癌症病例预计将于明年在美国确诊。癌症也占美国医疗保健总支出的很大一部分,估计到2020年将超过2000亿美元。因此,生物制药行业主要专注于肿瘤药物的开发。近40种新的抗癌药物获得批准仅在2019年和2020年,以及超过1300种新药疫苗也在临床开发中。
衡量肿瘤干预措施的疗效对于使患者与正确的干预措施相匹配至关重要。肿瘤学数据和相关的现实证据有可能为临床研究、试验设计、监管决策、安全评估、治疗途径等提供信息。不幸的是,鉴于肿瘤护理的高度专业化性质,疾病标准和终点通常无法以结构化格式提供,并且仍然锁定在数据筒仓中,这使得它们难以汇总和分析。
在肿瘤学中,病理报告(通常以PDF格式捕获并存储在EMR系统中)包含关键信息,如肿瘤大小、分级、分期和组织学。一旦使用自然语言处理(NLP)系统提取这些变量,就可以用于定义疾病队列,评估疾病严重程度,并为疾病进展创建基线,然后可以应用于上述用例,从临床试验匹配到治疗途径。但是从非结构化的临床文本数据中提取这些信息通常是数据团队的一个巨大痛点。
医疗NLP领域的领导者John Snow Labs和Databricks正积极应对这些挑战,并与医疗生态系统中的许多客户合作,将非结构化肿瘤数据转化为可操作的证据。
与Databricks和John Snow实验室进行大规模临床自然语言处理
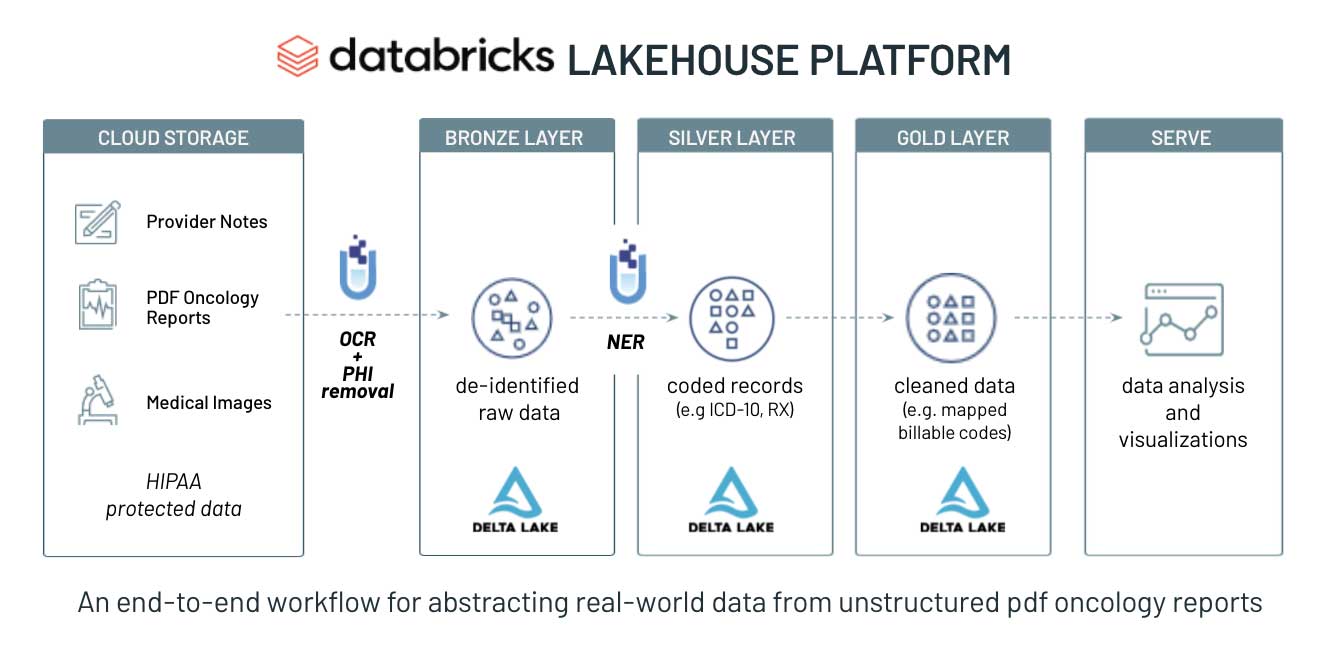
前进的道路始于Databricks湖屋平台bob体育客户端下载这是一个现代数据平台,它将数据仓bob体育客户端下载库的最佳元素(如数据管理和性能)与云数据湖的低成本、灵活性和规模相结合。这个新的,简化的架构使卫生系统得以实现将所有数据结构化(如EHR数据库中的诊断和程序代码)、半结构化(如HL7、FHIR信息)和非结构化(如自由文本笔记和图像)统一为一个传统分析和数据科学的单一高性能平台。bob体育客户端下载

Databricks Lakehouse平台的核心是bob体育客户端下载三角洲湖这是一个开源存储层,为数据湖带来了性能(通过Apache Spark™)、可靠性和治理。医疗保健组织可以将其所有数据(包括原始供应商说明、放射学报告和PDF病理报告)输入Delta Lake。在应用任何数据转换之前,这将保留真实的原始来源。相比之下,在传统数据仓库中,转换发生在加载数据之前,这意味着从非结构化文本中提取的所有结构化变量都与本机文本断开了连接。
在此基础上,约翰·斯诺实验室用于医疗保健的Spark NLP,最广泛使用的NLP库在医疗保健和生命科学行业。Spark NLP for Healthcare经过优化,可在Databricks上运行,以最先进的精度无缝提取、分类和构建临床和生物医学文本数据。它是唯一的本地分布式开源文本处理库,适用于Python、Java和Scala,由于每个Spark NLP管道都是一个Spark ML管道,因此特别适合构建统一的NLP和机器学习管道。Spark NLP提供Python、Java和Scala库传统NLP库的全部功能(如spaCy, nltk, Stanford CoreNLP和Open NLP),并添加了额外的功能,如拼写检查,情绪分析和文档分类。你可以在我们之前BOB低频彩的博客中了解更多关于Databricks和John Snow实验室的联合解决方案,自然语言处理在大规模卫生文本中的应用.
实际的肿瘤学数据抽象
为了展示Databricks和John Snow实验室的强大功能,我们创建了一个解决方案加速器用于从肿瘤学记录中提取真实数据。该解决方案加速器包含样本数据、预构建代码和逐步说明,用于摄取和准备肿瘤报告,以进行下游分析和生成真实世界的证据。这个解决方案已经在Databricks的笔记本中准备好了,为了帮助您入门,我们在下面提供了一个简单的解决方案演练。
对于这个解,我们使用Mt肿瘤学笔记数据集。它主要以跨医学专业的转录样本医疗报告的形式提供资源,以及在构成医疗报告一部分的特定部分中遇到的常见医疗转录单词/短语-如体检或PE,系统或ROS审查,实验室数据和精神状态检查等部分。
我们从MT oncology notes数据集中选择了50份去识别的肿瘤学报告作为非结构化文本的来源,并将原始文本数据放入Delta Lake bronze层。出于演示目的,我们将样本数量限制在50个,但是这个解决方案加速器中提供的框架可以扩展到容纳数百万个临床记录和文本文件。
我们的加速器的第一步是使用命名实体识别(NER)的各种模型提取变量。为此,我们首先设置NLP管道,其中包含注释器例如documentAssembler, senencedetector和tokenizer,这些都是专门为医疗保健相关NER培训的。在下面的例子中,我们合并了bionlp_ner为临床NER模型jsl_ner,这是一个预训练的深度NER临床术语模型。我们看到间皮瘤患者有咳嗽等症状。

从文本中提取命名实体是人工智能辅助ETL的一个很好的例子:预训练的深度学习(DL)模型使我们能够将非结构化数据转换为可用于下游临床分析的结构化格式。
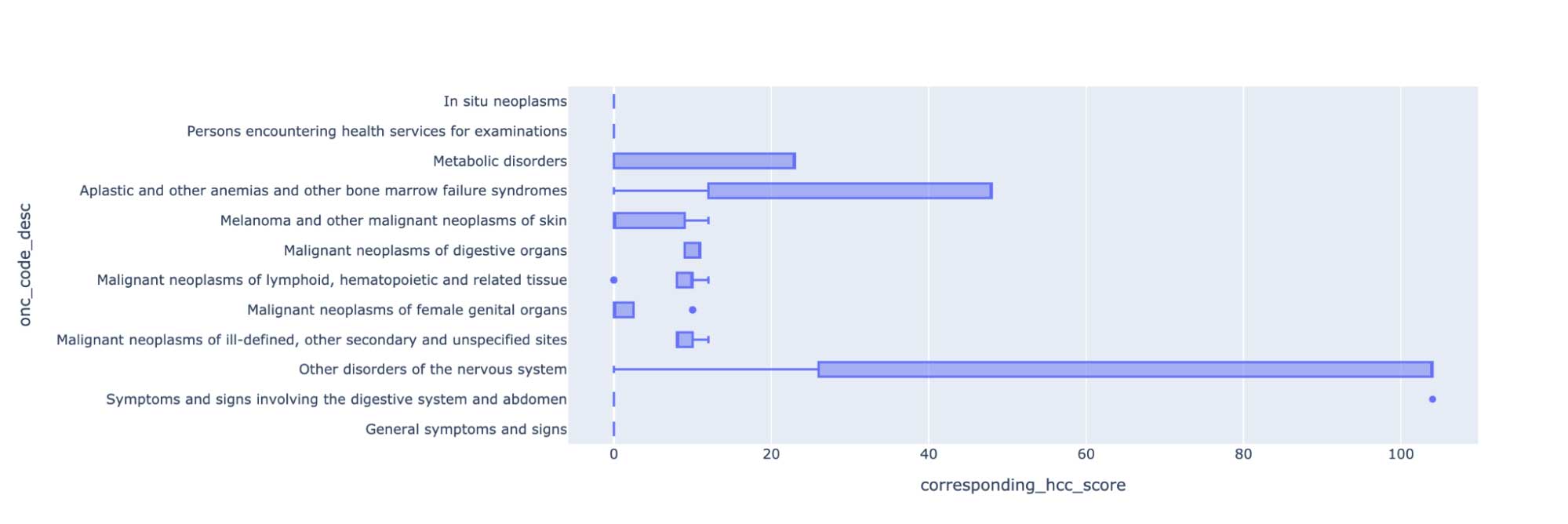
一旦我们提取出症状,我们就可以映射到icd - 10编码,可用于编码自动化和改进层次条件类别(HCC)医疗保险风险调整的编码精度。我们可以进一步使用这些数据来分析治疗模式,并分析症状和肿瘤实体之间的关联。
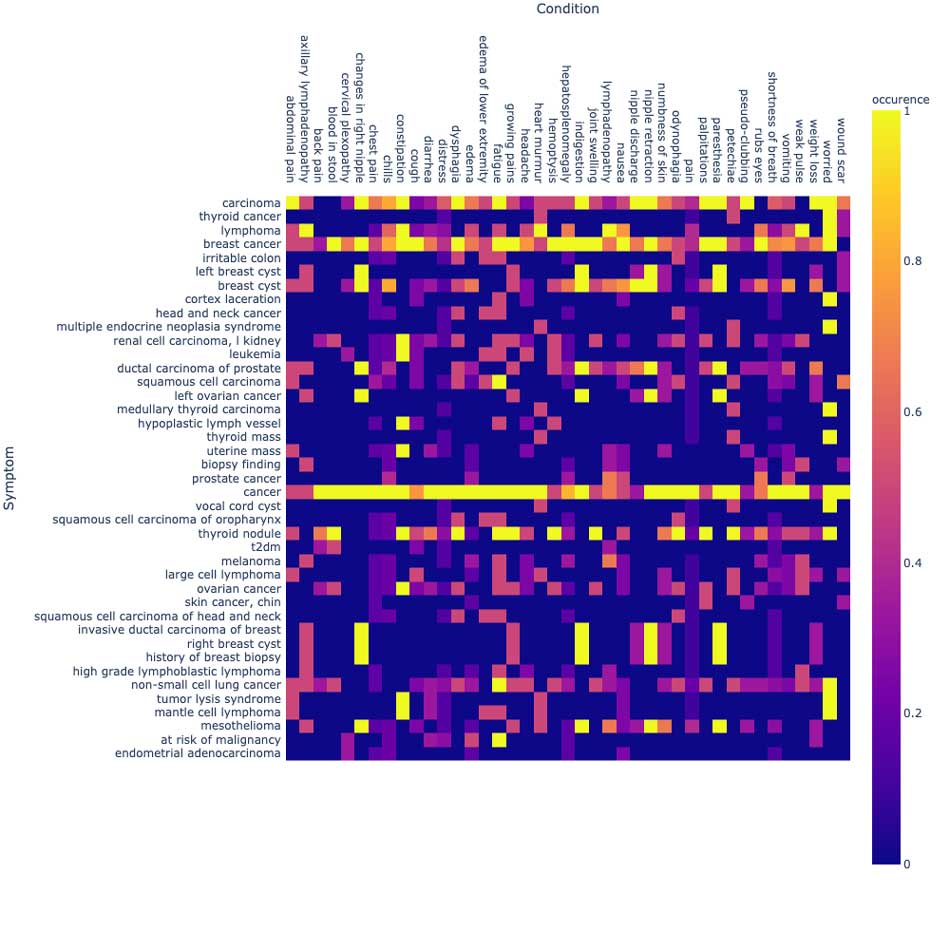
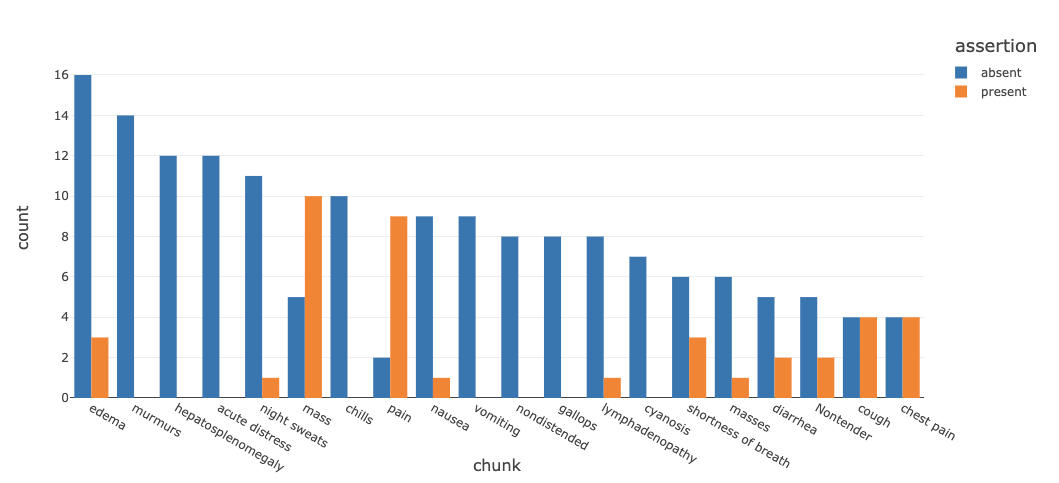
我们还可以生成一个图表,以研究这些症状存在、不存在或与其他人(例如,家庭成员)相关的断言状态。
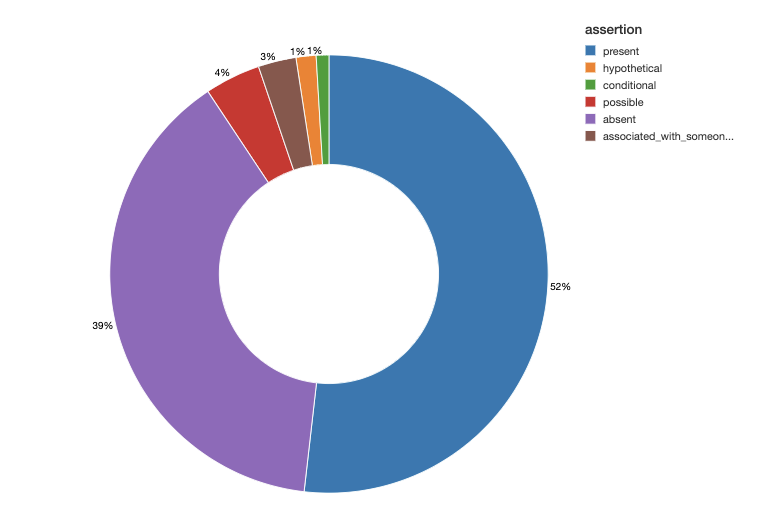
继续使用相同的注释集,我们运行描述性和可视化统计,以显示按断言状态分层的最常见肿瘤实体(如下例)。
接下来,我们可以看看治疗,包括药物频率和持续时间,这构成了肿瘤方案的基础。下面是我们的解决方案笔记本中包含的提取药物治疗和持续时间信息的NLP模型的截图。

然后,我们可以将症状与治疗相关联,以及疾病状态,如复发,与信心评分相关联。

这些数据对于确保个体患者护理的质量和人群水平的研究至关重要,有助于确定现实世界中干预措施的有效性和安全性。
使用Databricks Lakehouse平台,我们还可以轻bob体育客户端下载松创建一个关于病情、症状和程序的数据库,以及从非结构化笔记中提取的其他相关信息,然后可用于下游分析、临床决策支持和研究。
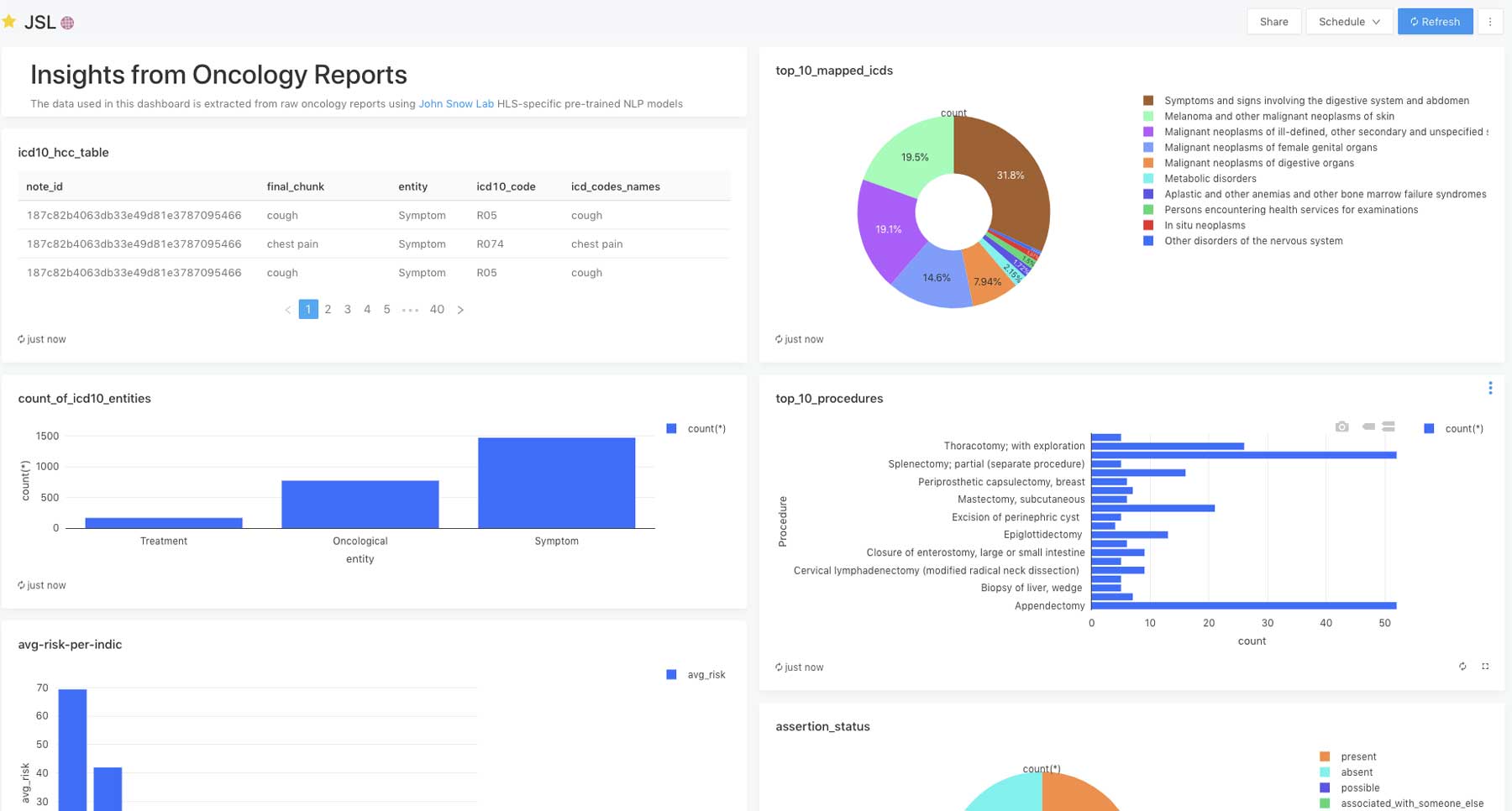
有了这个解决方案加速器,Databricks和John Snow实验室打开了大规模提取肿瘤数据的大门,并具有生成真实世界证据所需的质量。
开始使用NLP从肿瘤学笔记中提取RWD
要使用此解决方案,请预览笔记本电脑在线或者马上开始下载并导入笔记本电脑进入你的Databricks帐户。笔记本包括安装相关的John Snow Labs NLP库和许可密钥的指导。