









使用动态文件修剪在Delta Lake上更快的SQL查询
有两种历史悠久的优化技术可以使查询在数据系统中运行得更快:以更快的速度处理数据或简单地处理…
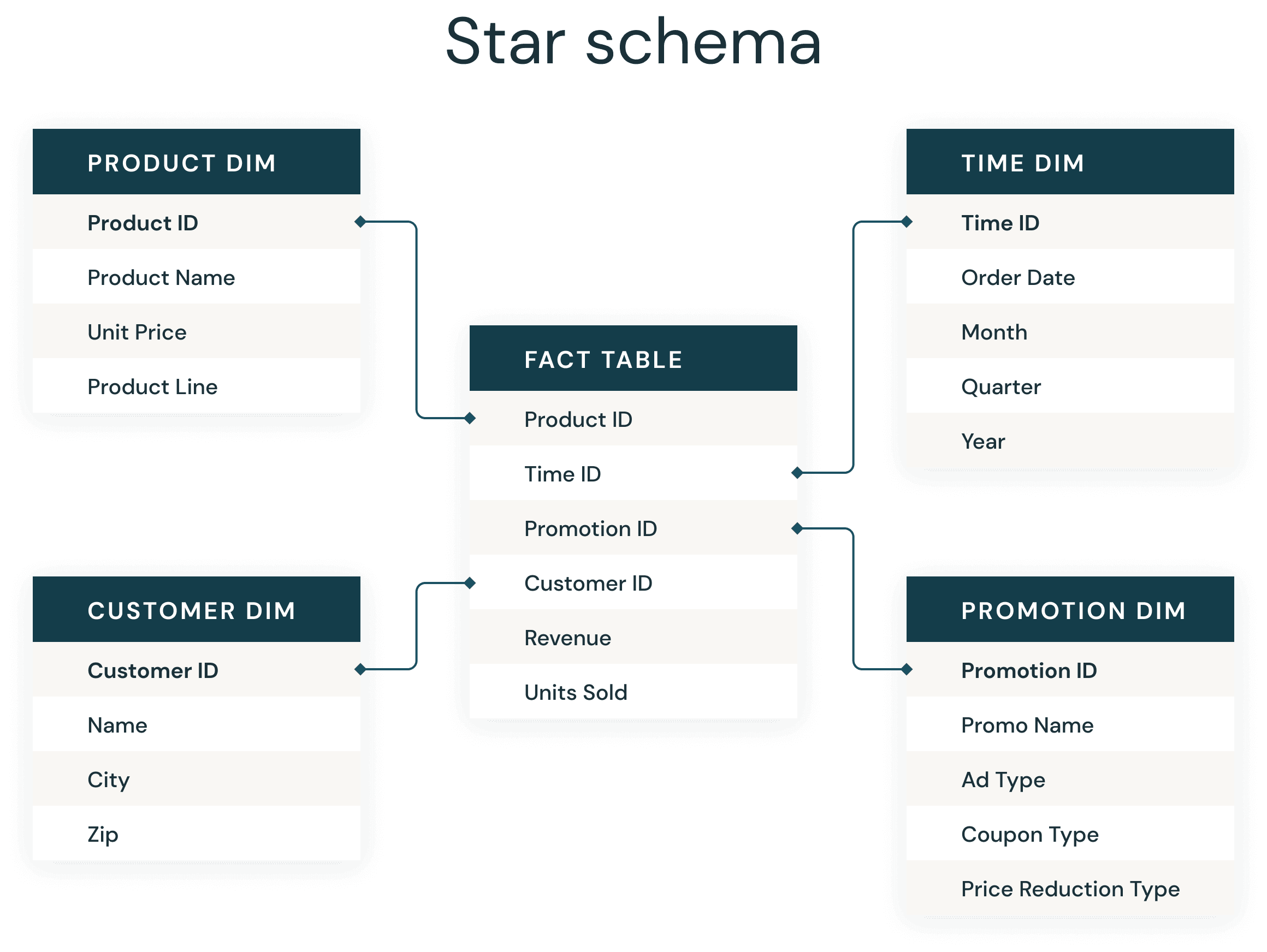
大多数数据仓库开发人员都非常熟悉始终存在的星型模式。星型模式由Ralph Kimball在20世纪90年代引入,用于将业务数据反规范化为维度(如时间和产品)和事实(如金额和数量的交易)。星型模式可以有效地存储数据、维护历史记录和更新数据,减少重复的业务定义的重复,从而快速地进行聚合和过滤。
支持商业智能应用程序的星型模式的通用实现已经变得如此常规和成功,以至于许多数据建模师实际上可以在睡梦中完成这些工作。在Databricks,我们已经开发了如此多的数据应用程序,并不断寻找最佳实践方法作为经验法则,这是保证我们获得良好结果的基本实现。
就像在传统的数据仓库中一样,在Delta Lake上可以遵循一些简单的经验规则,这些规则将显著改善Delta星型模式连接。
以下是成功的基本步骤:
三角洲湖是一个开放的存储格式层,提供了在数据湖表上插入、更新、删除和添加ACID事务的方便,简化了维护和修订。三角洲湖也提供了执行能力动态文件修剪以优化更快的SQL查询。
在Databricks Runtimes 8上语法很简单。Delta Lake是默认的表格式。您可以使用SQL创建Delta表,如下所示:
创建表格My_table (column_name字符串)8。x运行时,Databricks需要使用使用δ语法。
Apache Spark™查询中两个最大的时间消耗是从云存储读取数据所花费的时间和读取所有底层文件的需要。与数据不在Delta Lake上,查询可以选择性地只读取包含相关数据的Delta文件,从而节省大量时间。数据跳过可以帮助进行静态文件修剪、动态文件修剪、静态分区修剪和动态分区修剪。
在设置数据跳过时首先要考虑的事情之一是理想的数据文件大小-太小,您将有太多的文件(众所周知的“小文件问题”);如果太大,您将无法跳过足够的数据。
一个好的文件大小范围是32- 128mb(当然32MB是1024*1024*32 = 33554432)。同样,这个想法是,如果文件大小太大,动态文件修剪将跳到正确的文件或多个文件,但它们将如此之大,仍然有很多工作要做。通过创建较小的文件,您可以从文件修剪中受益,并最大限度地减少检索需要连接的数据的I/O。
你可以在Python中设置整个笔记本的文件大小:
spark.conf。集(“spark.databricks.delta.targetFileSize”,33554432)或者在SQL中:
集spark.databricks.delta.targetFileSize=33554432或者你可以设置它只针对一个特定的表使用:
改变表格(数据库)。(表格)集TBLPROPERTIES (delta.targetFileSize=33554432)如果您刚好在创建了表之后阅读本文,您仍然可以为文件大小设置表属性,并且在优化和创建ZORDER时,文件将与新文件大小成比例。如果您已经添加了ZORDER,您可以添加和/或删除一个列以强制在到达最终的ZORDER配置之前重新写入。在步骤3中阅读更多关于ZORDER的信息。
可以找到更完整的文档在这里对于那些除了SQL之外还喜欢Python或Scala的人来说,完整的语法是在这里.
随着Databricks继续添加特性和功能,我们还可以根据表大小自动调优文件大小。对于较小的数据库,上面的设置可能会提供更好的性能,但对于较大的表和/或只是为了简化,您可以遵循指导在这里并实现delta.tuneFileSizesForRewrites表属性。
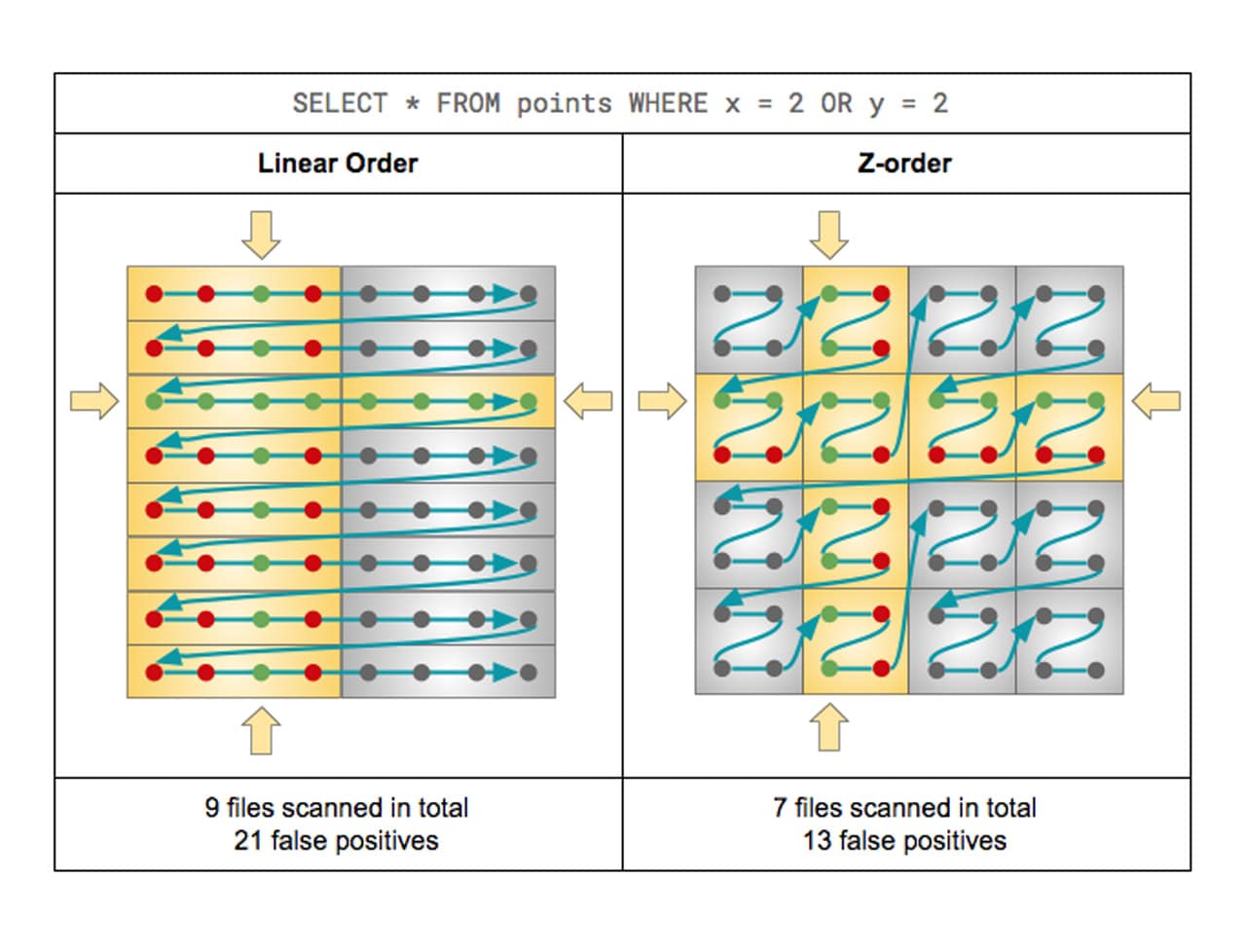
为了提高查询速度,Delta Lake支持优化存储在云存储中的数据布局z值,也称为多维聚类。z - order在与数据库世界中的聚集索引类似的情况下使用,尽管它们实际上不是一种辅助结构。Z-Order将聚类Z-Order定义中的数据,以便像来自Z-Order定义的列值一样的行在尽可能少的文件中进行配置。
大多数数据库系统引入索引来提高查询性能。索引是文件,因此随着数据的增长,它们可能成为另一个需要解决的大数据问题。相反,Delta Lake对Parquet文件中的数据进行排序,以使对象存储上的范围选择更有效。结合统计数据收集过程和数据跳过,Z-Order类似于数据库中的查找和扫描操作,其中索引解决了问题,而不会创建另一个计算瓶颈来查找查询正在寻找的数据。
对于Z-Order,最佳实践是将Z-Order中的列数限制为最佳的1-4列。我们选择了3个最大维度中的外键(使用的外键,而不是实际强制的外键),这些外键太大了,无法广播给工人。
优化MY_FACT_TABLEZorder by (largest_dim_fk, next_largest_dim_fk,…)此外,如果您的事实表中有巨大的规模和数千亿行的数据或pb级的数据,您应该考虑分区以进一步改善文件跳过。当您对分区字段进行主动筛选时,分区是有效的。
虽然Databricks没有强制要求Delta表上有主键,但由于您正在阅读本文,因此您可能有维,并且存在一个代理键——一个整数或大整数,经过验证并且期望是惟一的。
我们正在处理的一个维度有超过10亿行,并且在将谓词添加到Z-Order后受益于文件跳过和动态文件修剪。我们的小维度在维度关键字段上也有z - order,并在连接到事实中广播。与关于事实表的建议类似,将Z-Order中的列数量限制为维度中除键外最有可能包含在过滤器中的1-4个字段。
优化MY_BIG_DIMZorder by (my_big_dim_pk, likely_field_1, likely_field_2)Apache Spark™3.0的主要进步之一是自适应查询执行(Adaptive Query Execution,简称AQE)。从Spark 3.0开始,AQE中有三个主要特性,包括合并后洗牌分区、将排序合并连接转换为广播连接和倾斜连接优化。这些特性共同支持Spark中维度模型的加速性能。
为了让AQE知道为您选择哪个计划,我们需要收集有关表的统计信息。您可以通过发出ANALYZE TABLE命令来做到这一点。客户报告说,收集表统计信息显著降低了维度模型(包括复杂连接)的查询执行。
分析表格My_big_dim计算统计为所有列通过遵循上述指导原则,组织可以减少查询时间——在我们的示例中,同一集群上的查询时间从90秒减少到10秒。这些优化极大地减少了I/O,并确保我们只处理正确的内容。我们还受益于Delta Lake的灵活结构,因为它既可以扩展又可以处理从商业智能工具临时发送的查询类型。
除了在这篇博客中提到的文件跳过优化,Databricks还在用Databricks Photon提高Spark SQL查询的性能方面投入了大量资金。BOB低频彩了解更多光子和性能提升,它将提供所有Spark SQL查询与Databricks。
通过在Databricks Runtime中启用Photon,客户可以期望他们的ETL/ELT和SQL查询性能得到提高。结合本文概述的最佳实践,使用支持photon的Databricks Runtime,您可以期望实现比最佳云数据仓库更好的低延迟查询性能。



